DynamoDB 的一對多關聯
SaaS 控制平面幾乎都會有一層包含階層:一個 workspace
擁有多個 project。在 SQL 裡你會在 projects 表上放一個 workspace_id
外鍵,然後 JOIN。
DynamoDB 沒有 join、也沒有外鍵,所以關聯必須存在於
key schema 本身。做對了,「載入一個 workspace 與其中每個 project」
就會變成單一 Query,而不是一次讀取加上後續掃描。
如何在 DynamoDB 中建立一對多關聯的模型?
讓父項與其所有子項共用相同的 partition key,使它們共享同一個 item collection,再以 sort key 加以區分。DynamoDB 沒有 join 也沒有外鍵,因此關聯必須存在於 key schema 本身。如此一來,載入父項及其所有子項就能以單一 Query 完成,而不需要 join。
- 建模你的讀取,而不是實體。 這個一對多關聯之所以存在,只是為了服務 「列出某個 workspace 的所有 project」 — 圍繞那個查詢來塑造你的 key。
- 把父項編碼進子項的 partition key。 讓 workspace 與其所有 project 共用同一個 partition-key 值,使它們落在同一個 item collection。
- 這樣列表讀取就是一個
Query。 父項加上任意數量的 子項,會在單一計費呼叫中一併回傳 — 沒有 join、沒有第二趟往返。 - 留意熱 partition。 一個超大的租戶會把所有流量集中在單一 partition;一個巨大的 workspace 可能需要分片的 key 與扇出讀取。
先談存取模式
DynamoDB 建模是存取模式優先,而非實體優先 — 這正是 single-table design 背後的同一套紀律。在選定任何 key 之前,先寫下應用程式實際發出的讀取:
- 取得某個 workspace 的設定。
- 列出某個 workspace 裡的每個 project,最新的在前。
- 依 id 取得某個特定的 project。
「一個 workspace、多個 project」這個關聯之所以重要,只因為讀取 #2。 如果你從不需要把一個 workspace 的 project 一併列出,你根本不會去建這個 關聯模型 — 你會把 project 各自獨立儲存。
所以問題從來不是抽象的「我該怎麼表示一對多?」。而是 「這個關聯必須服務哪些查詢?」回答了這個,再圍繞它塑造 key。
為什麼外鍵在這裡幫不上忙
在 DynamoDB 中,每個 GetItem 與 Query 都鎖定一個 partition key,而
服務會對那個 key 雜湊以定位存放該 item 的 partition。
AWS 在 Core Components 文件中直接這麼說:partition-key 值是內部雜湊函式的輸入,由它 決定資料存放在哪裡。
這種基於雜湊的放置方式,承襲自 2007 年原始的 Dynamo: Amazon's Highly Available Key-value Store 論文,當中以一致性雜湊 把 key 分散到各節點。
project item 上一個光禿禿的 workspace_id 屬性 對那套機制而言是
看不見的 — DynamoDB 無法去「追蹤」它。
要在單一請求中取得相關 item,父項的身分必須編碼進
project 的 partition key,這樣某個 workspace 的所有 item 才會雜湊到同一個
partition,讓一個 Query 能一次掃過它們。
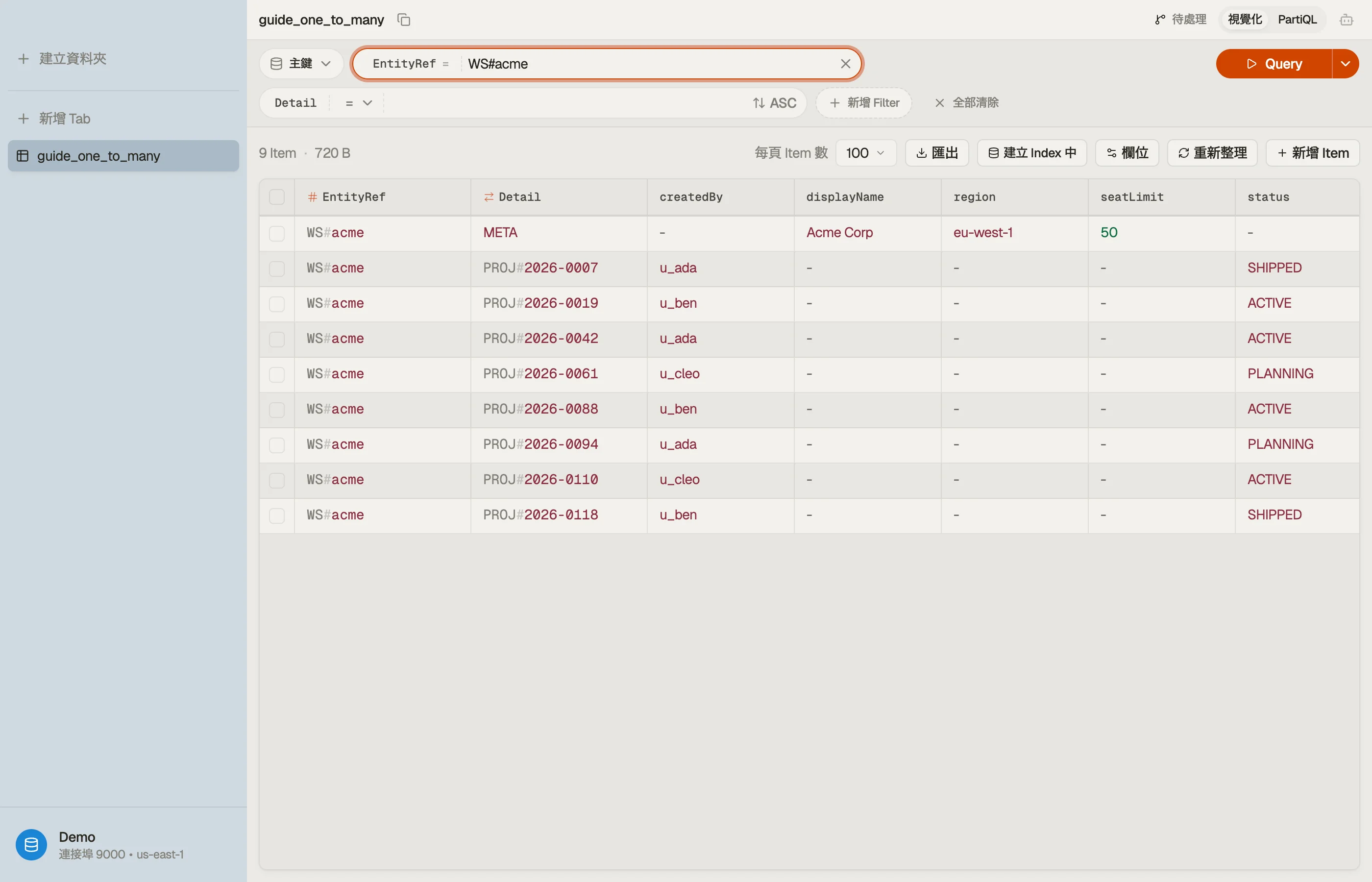
完整範例:workspaces 與 projects
使用一套通用、overloaded 的 key schema。把 partition key 稱為 EntityRef、sort
key 稱為 Detail。workspace 身分對 workspace item 與其下每個 project 兩者
都放進 EntityRef:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
workspace 與其所有 project 共用 EntityRef = "WS#acme",因此它們組成一個
單一 item collection,一起存活在同一個 partition 上。
Detail sort key 把它們區分開來:META 是 workspace 紀錄,而每個
project 帶有 PROJ# 前綴,加上零填補、依時間排序的 id,讓 project
自然排序。
視覺上,父項與其子項在一個 partition 內堆疊,依 sort key 排序:
對 EntityRef = "WS#acme" 的一個 Query 會掃過整疊 — 父項加上每個
子項 — 在單一讀取中完成。
現在這三個存取模式各自收斂為一次呼叫:
- workspace 設定 —
GetItem(EntityRef="WS#acme", Detail="META")。 - 列出 project,最新在前 —
Query(EntityRef="WS#acme")搭配Detail begins_with "PROJ#",以降序執行 (ScanIndexForward = false)。 - 單一 project —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042")。
第二個才是整個重點:父項與任意數量的子項
會在 一個 計費 Query 中回傳,沒有 join、沒有第二趟往返。這正是
你用外鍵屬性加 Scan 做不到的招式。
手寫那個 begins_with 條件很瑣碎 — key-condition 與
projection-expression 語法會咬人。
DynamoDB Expression Builder 會產生
KeyConditionExpression、#name/:value 佔位符對應表,以及一段
可直接執行的 SDK 程式碼片段,讓你不必跟文法搏鬥:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }在 DynoTable 中檢視 item collection
這種排版的回報是視覺化的:每一列共用同一個 EntityRef,就是
workspace 加上它的子項,彼此緊鄰排列。
DynoTable 會把它們分組,讓你把一對多關聯看成一個連續的 區塊,而不是在分散的表格之間猜測。


陷阱與替代形狀
幾件要留意的事:
- 熱 partition。 一個 workspace 的每個 item 都住在同一個 partition,所以
單一非常大或非常忙碌的租戶會把流量集中。AWS 描述的
adaptive capacity
行為可以吸收中度的偏斜,但一個擁有數百萬個
project 的 workspace 可能需要分片的 key(例如
WS#acme#01 … #10)與扇出讀取。 - item collection 大小。 當存在 local secondary index 時,單一 partition 的 item collection 上限為 10 GB;沒有 LSI 就沒有這種限制。如果 你在這裡權衡 index 類型,請見 GSI vs LSI。
- 拿
Query,永遠別拿Scan。 整套設計存在的目的,就是讓你能對 一個 partition 下Query。退回用過濾的Scan去「找一個 workspace 的 project」,就是把模型丟掉、讀整張表 — 這正是 Query vs Scan 涵蓋的陷阱。
如果你真的需要 跨 workspace 列出 project(例如全域所有
status = ACTIVE 的 project),base table 無法回答這件事 — 它的
partition key 是以 workspace 為範圍的。
那是給某個次要 index 的工作,它在另一個屬性上重新分割 project, 而不是去重塑這個關聯。
下一步
把存取模式建模,把父項編碼進子項的 partition key,
一對多讀取就是單一 Query。用 DynamoDB Expression Builder 建立並驗證 key condition。
然後 下載 DynoTable 載入這個 schema,即時瀏覽 workspace→projects 的 item collection,並確認每個查詢都剛好做一次 讀取。