DynamoDB 裡的排序鍵補零
DynamoDB 的字串排序鍵是按字典序排序——一次一個字元,由左到右——不是按數字排。所以 "10" 落在 "2" 之前,因為 "1" 排在 "2" 之前。補零到一個固定寬度,就是你讓字串順序吻合數字順序的辦法。
為什麼 DynamoDB 排序鍵裡 "10" 會排在 "2" 之前?
因為 DynamoDB 字串排序鍵是以 UTF-8 位元組順序做字典序比較,而非數值比較。"1" 的位元組在 "2" 之前,所以 "10" 落在 "2" 之前。將每個數字用前導零補到固定寬度——"2" 變成 "0000000002"——字串順序就會與數字順序完全吻合。
- 陷阱: 以字串儲存的數字會像單字一樣排序。
"100"、"11"、"2"就是 DynamoDB 給你的順序——不是你的本意。 - 解法: 把每個數字用前導零補到固定寬度,這樣
"2"就變成"0000000002"。現在字典序和數字序一致了。 - 寬度挑一次: 依你將來會存的最大值來定它的尺寸,然後多加幾位。事後改寬度意味著要改寫每一個鍵。
- 遞減免費拿到: 要由高到低排序(排行榜的情況),存
maxValue - value,一樣補零——DynamoDB 沒有每屬性的排序方向。
為什麼字串排序鍵會背叛你
從 SQL 過來,對一個整數欄做 ORDER BY score DESC「就是會動」——引擎知道那欄是數字的。DynamoDB 對一個不是 Number 型別的排序鍵,沒有那種奢侈。
DynamoDB 用 UTF-8 位元組順序比較字串(S)排序鍵,依AWS 排序鍵文件。是位元組,不是大小。"9"(0x39)勝過 "10",因為它的第一個位元組打敗 "1"(0x31)。長度無關緊要——只有第一個相異的位元組做決定。
那就是地雷:一個數字一住進字串排序鍵裡,每一個走過那個範圍的 Query,回傳列的順序看起來都被打亂了。
打造一個排行榜排序鍵
拿一個季度的街機排行榜。每個賽季一個項目集合,裝著每位玩家的成績,而你希望最高分先出現。
用一個複合鍵把它建模在單一個項目集合裡:
leaderboardId(分割鍵)——例如SEASON#2026-SPRING。rankKey(排序鍵)——補零的分數加上一個破平局值。
一個天真的初次嘗試把原始分數當字串存:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "9" | quickdraw |
| SEASON#2026-SPRING | "10" | ace_pilot |
| SEASON#2026-SPRING | "1500" | nightowl |
| SEASON#2026-SPRING | "240" | bytecrash |
對 SEASON#2026-SPRING 的一次 Query 按這個位元組順序回傳它們:"10"、"1500"、"240"、"9"。9 分的成績墊底,而 1500 分的成績埋在中間。對一個排行榜毫無用處。
補到固定寬度
挑一個寬到足以容納你將來會記錄的最大分數的寬度,然後用零左補。假設分數上限是一千萬——那是八位數,所以用十位數留餘裕:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
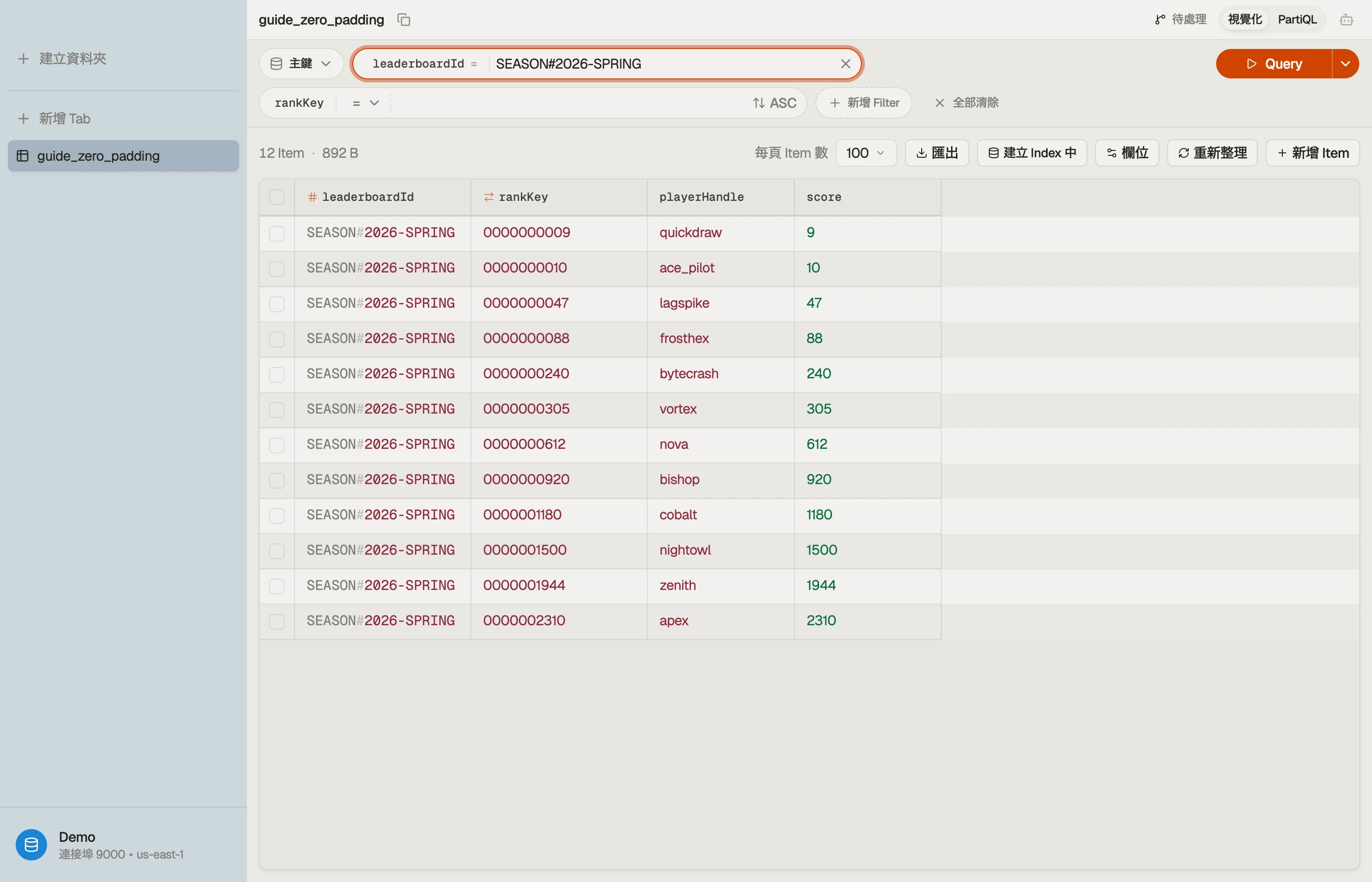
| SEASON#2026-SPRING | "0000000009" | quickdraw |
| SEASON#2026-SPRING | "0000000010" | ace_pilot |
| SEASON#2026-SPRING | "0000000240" | bytecrash |
| SEASON#2026-SPRING | "0000001500" | nightowl |
現在每個鍵都一樣長,所以逐位元組的比較和數字的比較產生相同的順序。遞增 Query 給出 9, 10, 240, 1500。數學終於吻合位元組了。
寬度是一道單向門。如果你補到十位數,而一個分數後來超過那個,一個 11 位數的值會排在一個 10 位數的值之前——把一切重新打壞——而要修它意味著改寫每一個既有的 rankKey。把寬度超量配置;代價就是區區幾個位元組。
遞減排序:存差值
排行榜要最高分先出現。DynamoDB 可以用 ScanIndexForward: false 正向或反向讀一個排序鍵,所以遞減通常是一個讀取時的旗標——先伸手抓它。
但當一個項目集合必須服務混合的排序方向時,或當你希望最高分不論讀取旗標都實體上排在最前面時,就翻轉數字本身。存 maxValue - score,補零到相同寬度:
score inverted (9999999999 - score) rankKey
1500 9999998499 "9999998499"
240 9999999759 "9999999759"
10 9999999989 "9999999989"
9 9999999990 "9999999990"對這個翻轉值的遞增位元組順序,現在產出由高到低的原始分數:1500, 240, 10, 9。這個訣竅符合 2007 年 Amazon Dynamo 論文的精神——鍵是不透明的位元組,所以你把意圖編碼進位元組裡。
加一個破平局值
兩位玩家可能打平。一個光禿禿的補零分數會在排序鍵上碰撞,而第二次寫入會覆蓋第一次(相同的 PK + SK)。接一個唯一後綴,讓每筆成績都是一個不同的項目,平局也以確定的方式解決:
rankKey = "<paddedScore>#<paddedTimestamp>#<playerId>"例如 "0000001500#0000001719100800#p_8842"。同樣的分數、較早的時間戳贏得較高的位置——把時間戳也補零,否則它會重新引入你剛修掉的那個確切錯誤。
在 DynoTable 裡,你可以瀏覽依補零的 rankKey 排序的賽季排行榜,看著補零後的值將各行正確排列——這是你出貨前確認寬度正確的有力證明。
手刻那個複合鍵時,很容易手滑打錯一個寬度。在 expression builder 裡為一個「賽季榜首」的 Query 生成 KeyConditionExpression,能在你實驗寬度的同時,讓 begins_with / between 語法保持誠實。


要避開的陷阱
- 補得太窄。 整套方案會在一個值首次溢出寬度時崩塌。為最壞情況定尺寸,然後再加位數。
- 忘了讀取旗標。 如果你永遠只讀遞減,
ScanIndexForward: false也許就是你需要的全部——當一個旗標就能搞定時,別伸手去抓翻轉鍵。 - 同一個集合裡混用寬度。 共用一個排序範圍的每一個鍵都必須用相同寬度。一次只補新列卻不補舊列的遷移,會把它們錯誤地交錯起來。
- 補錯了片段。 在一個複合鍵裡,把每一個參與排序的數字片段都補零——分數和時間戳兩者,不只是分數。
下一步
補零是更廣的排序鍵設計工具箱裡的一個工具;當你超載一個鍵去服務好幾種模式時,把它跟項目集合搭配,並在順序對了之後,倚賴一個精確的 Query 而不是一次 Scan。
試用 DynoTable,去瀏覽一張真實的表,在你提交綱要之前,看著你補零的排序鍵落入數字順序。