如何在 DynamoDB 中建模資料
在 SQL 裡,你先建模實體與關聯,然後信任查詢規劃器稍後組裝你所要的任何東西。DynamoDB 把這顛倒過來。你建模 你已經知道自己會做的讀取,而 key 的存在就是為了服務它們。
沒有 join 引擎、沒有規劃器在執行期挑選策略。一個 Query 沿一條 key 讀一個 partition,而那就是整個效能契約。所以你為已知的存取模式設計 key,而非為一個整齊的 schema。
AWS 在它的最佳實務指南裡講得很白:「在你知道 schema 需要回答哪些問題之前,你不該開始設計它。」
本指南在一個領域上走完整個流程:一個 多人遊戲排行榜,追蹤玩家、他們打的比賽,以及他們的每季排名。我們從一份問題清單走到一套可運作的 key schema。
如何在 DynamoDB 中建模資料?
先建模讀取,而非表。列出應用程式執行的每一個查詢,然後設計 partition key 與 sort key,讓每個問題都能收斂成單一 Query 或 GetItem。將一起讀取的 item 共置、在 sort key 中對值做範圍掃描,並為 base table 無法服務的存取模式加上 GSI。
- 先列出讀取,不是表。 問題就是規格;名詞是干擾。
- 每個問題都必須是一個
Query或GetItem。 如果某個問題需要Scan,那模型就是錯的。 - 共置的 item 共用 partition key;任何你要範圍掃描的東西放進 sort key。
- base table 答不出的問題就配一個 GSI — 永遠別用帶過濾的
Scan。
步驟 1 — 把問題框成問句,而非表
按捺住畫出 players、matches、scores 表的衝動。那種直覺是 SQL 習慣,在這裡是錯的。改成寫下應用程式實際執行的每個讀取。對我們的排行榜:
- 依 id 取得某玩家的個人資料。
- 列出某玩家的近期比賽,最新在前。
- 顯示某一季的前 N 名玩家,依 rating 排名。
- 依公開代號查詢某玩家(例如用於個人資料 URL)。
這四個問題 — 而非那些名詞 — 就是規格。每一個都必須收斂成單一 Query(或 GetItem),因為那是 DynamoDB 在規模下唯一便宜服務的存取形狀。
如果某個問題只能靠掃描表來回答,那模型就是錯的,而你會在延遲與成本上感受到 — 為什麼 Scan 是要避開的地雷,請見 Query vs Scan。
整套方法是一條短而有序、每個領域跑一次的流水線:
下面每個步驟對應一個框:列出、列舉、設計 key、為其餘的加 index,然後驗證。
步驟 2 — 理解你用來建模的原語
一張表有一個 partition key(PK),用來挑選某個 item 住在哪個實體 partition 上,以及一個可選的 sort key(SK),用來在 那個 partition 內排序 item。
AWS 的核心元件文件把這一對稱為 item 的主鍵。一個 Query 總是鎖定剛好一個 PK 值,且能對 SK 做範圍掃描或過濾 — 那就是整套工具。
這種單一 partition 的設計,正是讓 DynamoDB 能交付 2007 年 Amazon Dynamo 論文首先描述的那種可預測、低延遲、水平分割讀取的關鍵。
兩個後果驅動下面的每個決定:
- 一併讀取的 item 應共用一個 partition key,這樣一個
Query就能在單一計費請求中回傳它們。 - 任何你想範圍掃描的東西(近期比賽、最高 rating)都必須住在 sort key 裡,因為那是
Query唯一能排序與設邊界的屬性。
當某個問題需要 base table 提供之外的 不同 存取形狀時,你就加一個 Global Secondary Index — 把表在不同的 PK/SK 下重新投影。
(GSI 與 Local Secondary Index 的對照,請見 GSI vs LSI。)
步驟 3 — 設計 key,一次一個問題
我們用一張表搭配通用、overloaded 的 key 屬性 — single-table 做法 — 因為一個玩家與他的比賽是一併讀取的。
發明你自己的前綴;這裡 PLAYER#、MATCH#、SEASON# 在原本通用的 key 內標記實體類型。
問題 1 和 2(個人資料 + 近期比賽)共用一個 partition,所以兩者都掛在同一個 PK 下:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" 在一次讀取中回傳個人資料與每場比賽。只要個人資料,就 GetItem。
對於近期比賽,rangeId begins_with "MATCH#" 搭配 ScanIndexForward = false 會把它們從最新走起 — sort key 裡的時間戳免費替你排序。
問題 3 和 4 無法從那個 partition 回答 — 它們圍繞賽季排名與代號旋轉,兩者都不是 base PK。每個各配一個 GSI。
我們加上兩個通用的 index 屬性,gsiPartition / gsiSort,讓每個 item 用那個 index 所需的任何東西去填它們:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
現在 Query 賽季 index WHERE gsiPartition = "SEASON#2026-Q2" 搭配 ScanIndexForward = false 回傳依 rating 排名的玩家 — 那就是排行榜。
第二個以 HANDLE#… 為 key 的 index,在一次讀取中把公開代號解析成玩家 id。一張實體表,四個單一 Query 的存取模式。
關於
RATING#1842的零填補提醒:DynamoDB 對 sort key 做 字典序 而非數值排序,所以 rating 必須零填補到固定寬度(RATING#01842),否則9會排在1000之後。這是一個值得一開始就做對的經典建模陷阱。
步驟 4 — 在 DynoTable 中驗證模型
只有當你看著一個真實的 Query 剛好回傳你預期的 item、且不多不少時,一套 key schema 才贏得信任。
在 DynoTable 中打開表,對賽季 index 跑排行榜查詢,並確認 partition 以排名且有邊界的方式回來 — 沒有 Scan、沒有客戶端排序。

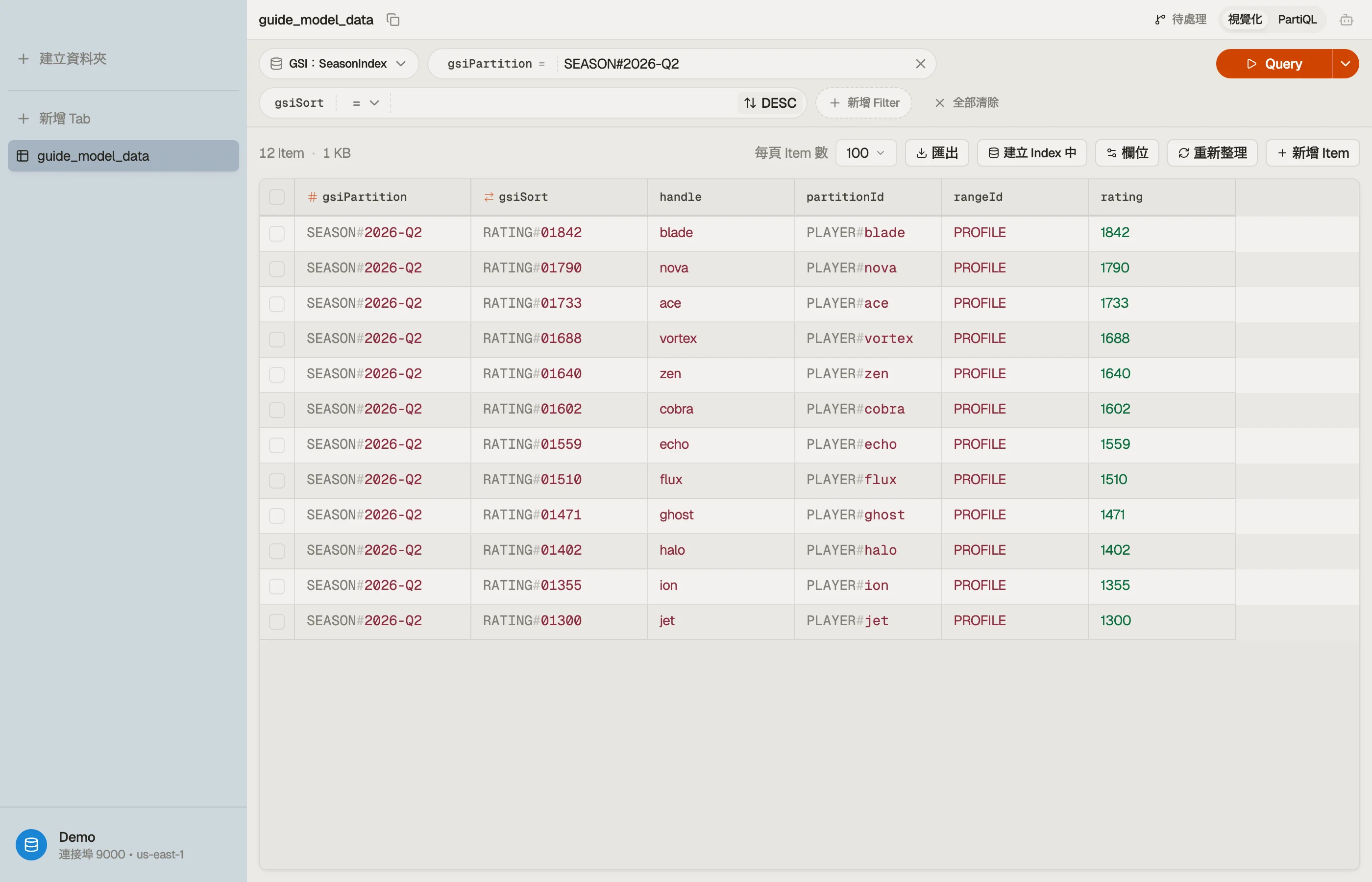

當你為這些查詢建立 condition expression 時 — begins_with、gsiPartition = :p、佔位符 :p 繫結 — 讓 DynamoDB Expression Builder 來做。
它會產生 KeyConditionExpression、ExpressionAttributeNames 與 ExpressionAttributeValues,這樣像 result 這種保留字或一個打錯的佔位符就絕不會悄悄弄壞一次讀取。
步驟 5 — 陷阱與下一步
出貨模型之前要檢查的幾個陷阱:
- 別替你從不一併讀取的關聯建模。 每個問題一個 GSI 很便宜;一個浪費的 GSI 是反覆出現的成本。從問題清單加 index,別投機。
- 留意 partition 的熱度。 如果一個 PK(一位名人玩家、單一熱門賽季)吸走大多數流量,那個 partition 可能會被節流。在一個 key 被證實很熱時,用後綴分片散開寫入 — AWS 在 partition-key 設計中涵蓋這點。
- 對 sort key 中任何數值或時間性的東西都零填補並用 ISO-8601,這樣字典序排序才會符合你想要的順序。
- 一個新問題 = 一個新 key 或 index,絕不是
Scan。 當稍後真的出現一個全新存取模式時,擴展 key;別用過濾來敷衍它。
先建模問題,把 key 設計成每個都是一個 Query,然後證明它。
試試 DynoTable 來瀏覽你的表、把這些查詢並排對 base table 與 GSI 跑,並看著你設計的存取模式剛好回傳你規劃的東西。