DynamoDB 的複合排序鍵
複合主鍵是一個分割鍵加上一個排序鍵。讓它強大的訣竅,在於你放進排序鍵裡的東西:把一層階層編碼成一個帶分隔符的字串,單一 Query 就能依排序順序讀出整個子樹——沒有 join、沒有遞迴、沒有第二趟往返。
複合排序鍵在 DynamoDB 裡是如何運作的?
複合排序鍵把一層階層打包進一個帶分隔符的字串——root/photos/2026/——DynamoDB 會以 UTF-8 位元組順序儲存它。由於這個佈局已經吻合那棵樹,單一個帶 begins_with(SK, "root/photos/") 的 Query 就能依路徑順序讀出整個子樹。沒有 join、沒有遞迴、沒有第二趟往返——只是在一段連續切片上的前綴掃描。
- 排序鍵是一個可排序的字串,不只是一個 ID。 把一條路徑打包進去——
root/photos/2026/——DynamoDB 就會自動以 UTF-8 位元組順序儲存該分割的項目。 - 一個分隔符把前綴比對變成子樹讀取。
begins_with(SK, "root/photos/")在一次查詢裡回傳該資料夾的每一個後代。 - 排序鍵支援範圍條件,不是任意過濾。 你能用
begins_with、between、>、<——設計鍵時要讓你需要的那次讀取是一個前綴或一個範圍,而不是一次Scan。 - 分隔符是承重的。 挑一個不可能出現在路徑片段裡的,否則兩個不相干的分支會碰撞。
為什麼排序鍵是整場遊戲的關鍵
從 SQL 過來,你會用一個 parent_id 自連接來建模資料夾樹,再遞迴地走過它——每一層一次查詢。在 DynamoDB 裡,那是對一個沒有 join 的鍵值儲存所擺出的 N+1 地雷。
DynamoDB 把每個項目存在某個分割鍵之下,依它的排序鍵排序,字串則以 UTF-8 位元組順序(AWS:Query 鍵條件)。所以如果你的排序鍵就是那條路徑,實體佈局就已經吻合那棵樹。一次讀取變成在一段連續切片上的前綴掃描——而不是一次圖走訪。
那就是那個轉變:排序鍵不是你要精確比對的識別符。它是一個可排序的位址。設計好它,查詢就免費掉出來了。
建模一棵檔案系統樹
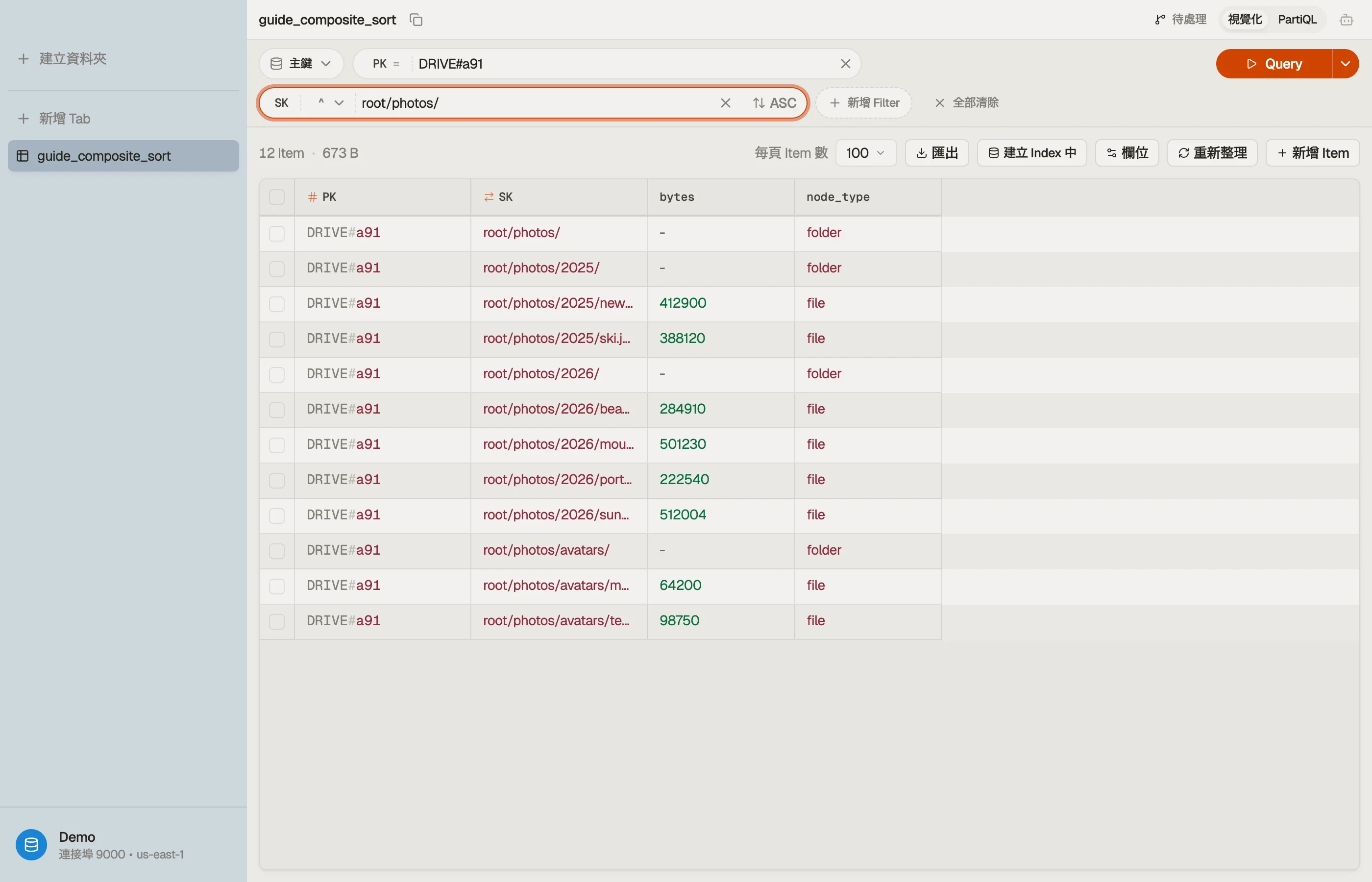
假設你在儲存每個帳號的檔案樹。每個帳號一個磁碟是自然的分割;磁碟裡的路徑是排序鍵。
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
這裡有兩個原創慣例在做事:
PK = DRIVE#<account>把一個帳號的整棵樹保留在單一項目集合裡,所以任何子樹讀取都是一次單分割Query。SK是完整路徑,資料夾尾端帶一個/。那個尾斜線是刻意的——它讓一個資料夾排在它自己的子項目之前,並讓root/photos/與一個名為root/photos的同層檔案有所區別。
一次查詢讀出一棵子樹
列出 root/photos/ 底下的一切——資料夾、子資料夾與檔案,遞迴地:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"那會回傳 root/photos/、root/photos/2026/、beach.jpg 與 sunset.jpg——依路徑順序,在一次計費的讀取裡。你只為那段切片裡的項目付費,不是整個磁碟。
在 DynoTable 中,你直接對路徑排序鍵執行這個 begins_with 查詢,資料夾及其後代就會依路徑順序回傳——無需手寫佔位符語法。
需要為自己的程式碼準備原始的 KeyConditionExpression(名稱、值與 begins_with)?在 DynamoDB Expression Builder 裡建立並複製即可。


只列一層,不是整棵子樹
begins_with 給你的是遞迴讀取。若要一次非遞迴的目錄列出——root/photos/ 的直接子項目,不再更深——就存一個深度屬性並加一個排序鍵範圍外加一個過濾,或把路徑拆進一個 parent GSI。最單純的版本:保留一個 parent 屬性(root/photos/)並用它設一個 GSI 的鍵。
重點是:排序鍵便宜地回答前綴與範圍問題。「只要直接子項目」是另一個問題——把它明確地建模出來,別指望一個 FilterExpression 會讓它有效率。過濾在讀取之後才執行,而它丟掉的每一個項目你都要付費。
小心挑選分隔符
分隔符是你資料契約的一部分。兩條規則:
- 它絕不能出現在某個路徑片段裡。 如果檔名可以含
/,那/就是錯的分隔符——一個名為a/b的檔案,跟一個裝著b的資料夾a無從分辨。挑一個保留位元組(有些團隊用#或一個控制字元),並在片段裡禁用它。 - 留意邊界處的排序順序。
/(0x2F)排在數字和字母之前,這通常正是你要的樹順序。換掉分隔符你就換掉了順序——用真實資料驗證它。
複合排序鍵 vs. 一個獨立的排序屬性
複合排序鍵(root/photos/2026/x) | 純 ID 排序鍵 + parent 屬性 | |
|---|---|---|
| 子樹讀取 | 一次 begins_with 查詢 | 遞迴查詢(N+1)或一次 GSI 走訪 |
| 排序 | 路徑順序,免費 | 必須加一個明確的排序屬性 |
| 移動/改名 | 改寫所有後代 | 更新一個 parent 指標 |
| 列直接子項目 | 需要深度屬性或 GSI | 天然(parent = x) |
當讀取是子樹形狀且順序重要時,複合鍵勝出;當樹不斷變動時,扁平 ID 模型勝出。大多數讀取繁重的階層——檔案樹、分類樹、組織圖——都偏向複合。
陷阱與下一步
- 別把鍵塞太滿。 你編碼進去的一切都是不可變的,而且只能依前綴索引。你要用相等比對來查的屬性,屬於它們自己的欄位或一個 GSI,不該硬塞進排序鍵裡。
- 排序鍵做不了任意的
WHERE。 只有begins_with、between與比較。如果你發現自己在伸手抓一個FilterExpression,那你大概把鍵建模錯了——見 Query 與 Scan。 - 更深入的鍵設計在單表設計裡;至於什麼時候子樹讀取需要一個索引而非基礎表,見 GSI 與 LSI。
用 Expression Builder 建好 begins_with 鍵條件,然後下載 DynoTable,對你自己的表執行這些前綴查詢,看著一棵子樹依路徑順序回來。