DynamoDB 裡的鍵超載
從 SQL 過來,一個欄永遠只代表一件事:orders.created_at 永遠是日期,users.email 永遠是 email。鍵超載把那套丟掉。你給分割鍵和排序鍵通用的名稱——pk、sk——讓每一種項目類型往裡頭灌進不同的意義。一張表,多種實體,一個形狀。
DynamoDB 的鍵超載是什麼?
鍵超載是指在一張表中以通用鍵名稱(如pk/sk)存放多種實體類型,並將類型編碼進鍵值裡(USER#u_3001、INVOICE#2026-0014)。屬性名稱保持中性,讓使用者、發票和事件共用同一個分割區;值本身承載類型,而排序鍵前綴讓一次Query透過begins_with切出各類實體。
- 通用的鍵名稱,帶類型的值。 把你的鍵命名為
pk/sk,並把實體類型放進值裡:pk = "TENANT#acme"、sk = "USER#u_3001"。名稱是笨的;值才承載類型。 - 這是讓單表設計運作的關鍵。 沒有超載,一張共用的表只是一個雜物抽屜。有了它,每一種實體都坐在一個你能
Query的分割裡。 begins_with是回報。 排序鍵上的一個類型前綴,讓一次Query拉出一整個實體,或它的一段切片,沒有Scan、沒有過濾。- 代價:可讀性。 一份原始的
pk/sk傾印什麼都告訴不了你。你需要一個能解碼前綴的檢視器,否則你會對著一堆字串瞇眼。
為什麼通用名稱勝過真實名稱
DynamoDB 每張表正好有兩個鍵屬性,而一次 Query 只能瞄準單一個分割鍵。所以如果你把鍵命名為 userId,那只有使用者項目能乾淨地住在那張表裡——其他一切都得偽造一個 userId,或搬到它自己的表去。
超載繞過了那個。一個中性的名稱像 pk 不對任何實體做承諾,所以一個使用者、一張發票和一個稽核事件,全都能共用同一個鍵屬性和同一張表。是那個值,而不是屬性名稱,說明該項目是什麼。
這個動作把單表設計從理論變成你真正能查的東西。共用的表是容器;超載則是讓不同實體在裡頭共存的關鍵。
一個多租戶範例
假設你經營一個 SaaS 計費產品。每個租戶有成員、發票和一條稽核軌跡。別用三張表,把這一切全放進一張,並把鍵超載:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
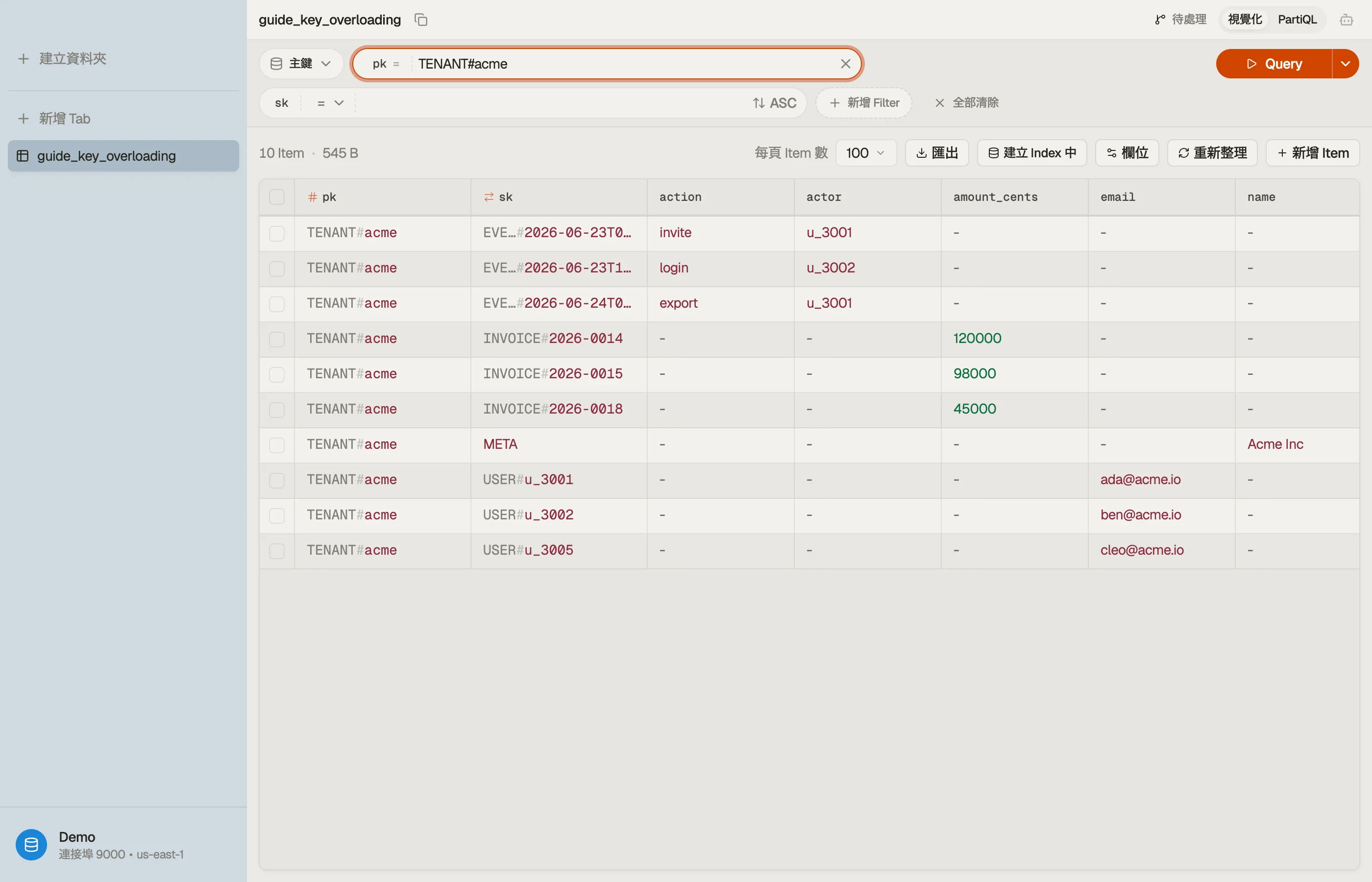
每一列共用 pk = "TENANT#acme",所以它們組成一個項目集合——全部共置、全部在一次分割讀取裡可達。
排序鍵的前綴在做真正的活。它把實體分組,並且把它們排序。
查詢這個超載的集合
因為類型住在排序鍵前綴裡,begins_with 不掃描任何東西就把分割依實體切片:
Query pk = "TENANT#acme" -- 整個租戶,每一種類型
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- 只要成員
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- 只要發票你只為條件比對到的項目付費,不是整個分割——這跟一次帶過濾的 Scan 相反,後者你要付費去讀那些你接著就丟掉的列。AWS 把這稱為一個鍵條件(condition);它在任何資料離開分割之前,就先在鍵上執行。
如果你手刻那個 begins_with 條件,要把類型標籤弄對——一個漏寫的 USERS#(而非 USER#)會無聲地回傳空白。expression builder 會生成 KeyConditionExpression 與 ExpressionAttributeValues 映射,好讓前綴吻合你實際寫的東西。
把索引也超載
同一個訣竅也適用於 GSI。給它通用的鍵名稱——gsi1pk、gsi1sk——讓每一種實體寫進它所需的任何東西。然後一個索引就回答了基礎表回答不了的模式。
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
現在 Query gsi1 WHERE gsi1pk = "STATUS#open" 列出所有租戶之間每一張未結帳的發票,依到期日排序——這是一個跨分割的檢視,基礎表那以租戶為界的鍵永遠服務不了。另一種實體可以用它自己的意義重用 gsi1(比如 gsi1pk = "ROLE#admin"),所以一個索引涵蓋好幾種讀取。只要記得 GSI 是最終一致——它的寫入會落後基礎表。
在 DynoTable 裡做
原始的超載鍵讀起來很不友善:INVOICE#2026-0015 和 EVENT#2026-06-23T09:12Z 在一張扁平列表裡糊成一團。一個依分割分組並把前綴呈現出來的檢視器,把雜物抽屜重新變回實體。


陷阱
- 分隔符挑一次就絕不改。
#是慣例。在不同實體之間混用#和:,會以沒有任何東西會警告你的方式打壞begins_with。 - 別超載需要範圍運算的值。 一個
INVOICE#2026-0015的排序鍵是按字典序排,不是按數字排——把 id 補零,並用 ISO-8601 日期,好讓字串順序吻合你要的順序。 - 保留前綴命名空間。 兩種都以
USER開頭的實體類型(比如USER#和USERGROUP#)會在begins_with(sk, "USER")之下碰撞。讓前綴從第一個字元起就毫不含糊。 - 在設鍵之前先規劃讀取。 超載服務的是你已經列舉過的存取模式。如果你還不知道你的讀取,先看單表設計——鍵是查詢的下游。
把一個分割畫出來,然後下載 DynoTable,去瀏覽你自己的超載鍵,看著一次 Query 把一整個租戶一口氣拉回來。