DynamoDB Sort Key 策略
一個 DynamoDB 主鍵是一或兩個屬性:單獨一個 partition key,或一個 partition key 加上一個 sort key。partition key 決定哪個實體 partition 存放某個 item。
sort key 決定那個 partition 內 item 的 順序 — 而那個
排序正是讓 Query 強大的東西。
挑錯 sort key,你仍能寫入資料,但你就失去了範圍讀取、 排序,以及從一個 collection 得來的數個存取模式。
從 SQL 過來,你會在事後伸手去拿一個 ORDER BY 或一個次要
index。在 DynamoDB 中,你預先把順序烤進 key 裡,否則就得不到它。
DynamoDB sort key 是如何運作的?
DynamoDB sort key 在 partition 內排序 item,讓 Query 能執行範圍讀取 — >=、between、begins_with — 而非每次只能取得一個 item。排序是依編碼後 key 的位元組順序,因此設計時(例如 ISO-8601 時間戳、零填補數字)需確保位元組順序符合你想讀取的順序。
- sort key 是你 partition 內的 index。 它在磁碟上排序 item
collection,所以
Query能做範圍讀取(>=、between、begins_with)而非 單一GetItem。 - 排序是編碼後 key 的位元組順序。 設計 key,讓位元組順序
等於你想讀的順序 — 一個 ISO-8601 時間戳、一個零填補的
數字,絕不是原始 UUID 或
6/23/2026。 - 一個塑造良好的 sort key 服務多個存取模式。 一個複合 key
(
EVT#<timestamp>)同時是前綴與範圍 — 不需要 GSI。 - 方向是免費的。
ScanIndexForward = false以相同成本從最新讀起; 別存反轉的時間戳去假造它。
為什麼 sort key 是那個槓桿
沒有 sort key,partition 中每個 item 只能用它完整的
主鍵定址 — 頂多是一個 GetItem。加上一個 sort key,DynamoDB 就
在 partition 內 依它排序 來儲存 item,這解鎖了 Query。
那意味著範圍條件(>=、between)、前綴比對(begins_with),
以及一個讀升序或降序的 ScanIndexForward 旗標。
依據 AWS DynamoDB 開發人員指南,所有共用同一 partition key 的 item 組成一個 item collection,在磁碟上依 sort key 排序。
所以 sort key 不只是第二個識別子。它是你在 partition 內查詢 的 index。
那個排序是編碼後 sort key 的位元組順序:字串依 UTF-8 位元組比較,數字依數值比較。這一個事實驅動了下面幾乎每個 策略。
如果你想讓範圍查詢有意義,位元組順序就必須符合你想讀的 順序。
策略 1:讓 sort key 可排序
最常見的錯誤是一個沒有有意義排序的 sort key。一個隨機 UUID 給你唯一性,但沒有有用的範圍查詢 — 「給我最後 20 筆」 變得不可能,因為位元組順序是任意的。
改成把你排序與過濾所依據的值編碼 進 sort key,採用一種 位元組順序等於其邏輯順序的表示法。對時間戳而言,那 意味著一種字典序可排序的格式:一個 ISO-8601 字串或一個零填補的 epoch。
ISO-8601 的設計就是讓字串比較等於時間序比較 —
正是範圍查詢所需的。避免像 6/23/2026 這種格式;它們在月份
翻轉的當下就排錯了。
如果你依數字排序(一個版本計數器、一個分數),用 DynamoDB 原生的
Number 型別而非字串,這樣 42 才排在 9 之後而非
之前。
如果一個數字必須住在複合字串 sort key 內,把它零填補到固定 寬度。
策略 2:複合 sort key 表達階層
一個 sort key 能用一個分隔符(最常見是 #)串接多個區段來編碼
一個階層。一個 begins_with 條件就能選出一整個子樹:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") 只回傳六月的事件;更廣的
begins_with(SK, "EVENT#") 回傳全部。
區段順序是一個設計決定。由粗到細(年 → 月 → 日)會讓 相關 item 保持連續,所以一次範圍讀取仍是一個便宜查詢,而非在 partition 上四散。
策略 3:用 ScanIndexForward 控制方向
DynamoDB 以 升序 sort-key 順序儲存 item,並預設那樣讀。
要從最新讀起 — 活動動態的自然順序 — 在 Query 上設定
ScanIndexForward = false。
這是一個讀取期旗標,不是 schema 決定:同一個 collection 以相同成本 服務兩個方向。別反轉你的時間戳(存一個「反向 epoch」)只為了得到降序讀取。
一個 item collection,以升序儲存一次,兩種讀法:
相同 item、相同 partition、相同成本 — 只有讀取方向不同。
唯一例外:當你特別需要降序也同時是某個稀疏 index 或
分頁游標前進的順序時。除此之外,
ScanIndexForward 是更簡單的槓桿。
演練範例:以行為者為範圍的 audit log
假設你在一個 SaaS 產品中記錄由行為者 — 使用者、服務、API key — 產生的帶時間戳事件,而你有兩個讀取:
- 某個行為者的活動串流,最新事件在前。
- 某個行為者在某時間窗口內的事件(例如「兩次部署之間的 一切」),用於調查。
兩個讀取都以單一行為者為範圍,所以行為者是 partition key,而 事件時間是 sort key。用通用的 key 名稱,讓同一張表稍後能容納其他 實體:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
EVT# 前綴加上一個 ISO-8601 時間戳給出一個可排序的 sort key。讀取 1 是
Query PK = "ACTOR#u_8814" 搭配 ScanIndexForward = false 取得最新在前。讀取
2 用 sort key 上的一個 between 條件縮窄同一個 partition:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"一個 collection、兩個存取模式、不需要 GSI — 因為 sort key 同時是一個前綴
(EVT#)與一個範圍(時間戳)。降序讀取與窗口讀取是
相同的 item、相同的順序;只有參數不同。
手寫那個 key condition,很容易搞砸 between 的邊界,或
屬性名稱上保留字的逸出。
DynamoDB Expression Builder
會為一個 begins_with 或 between sort-key 條件產生
KeyConditionExpression、ExpressionAttributeNames 與
ExpressionAttributeValues。
把它直接複製進你的 SDK 呼叫,而不必在執行期除錯逸出。
在 DynoTable 中做它
設計一個 sort key 是反覆的:寫幾個有代表性的 item、跑範圍 查詢、檢查列以你預期的順序回來。在一個 GUI 中對一張真實表這麼做, 勝過繞著程式碼來回往返。

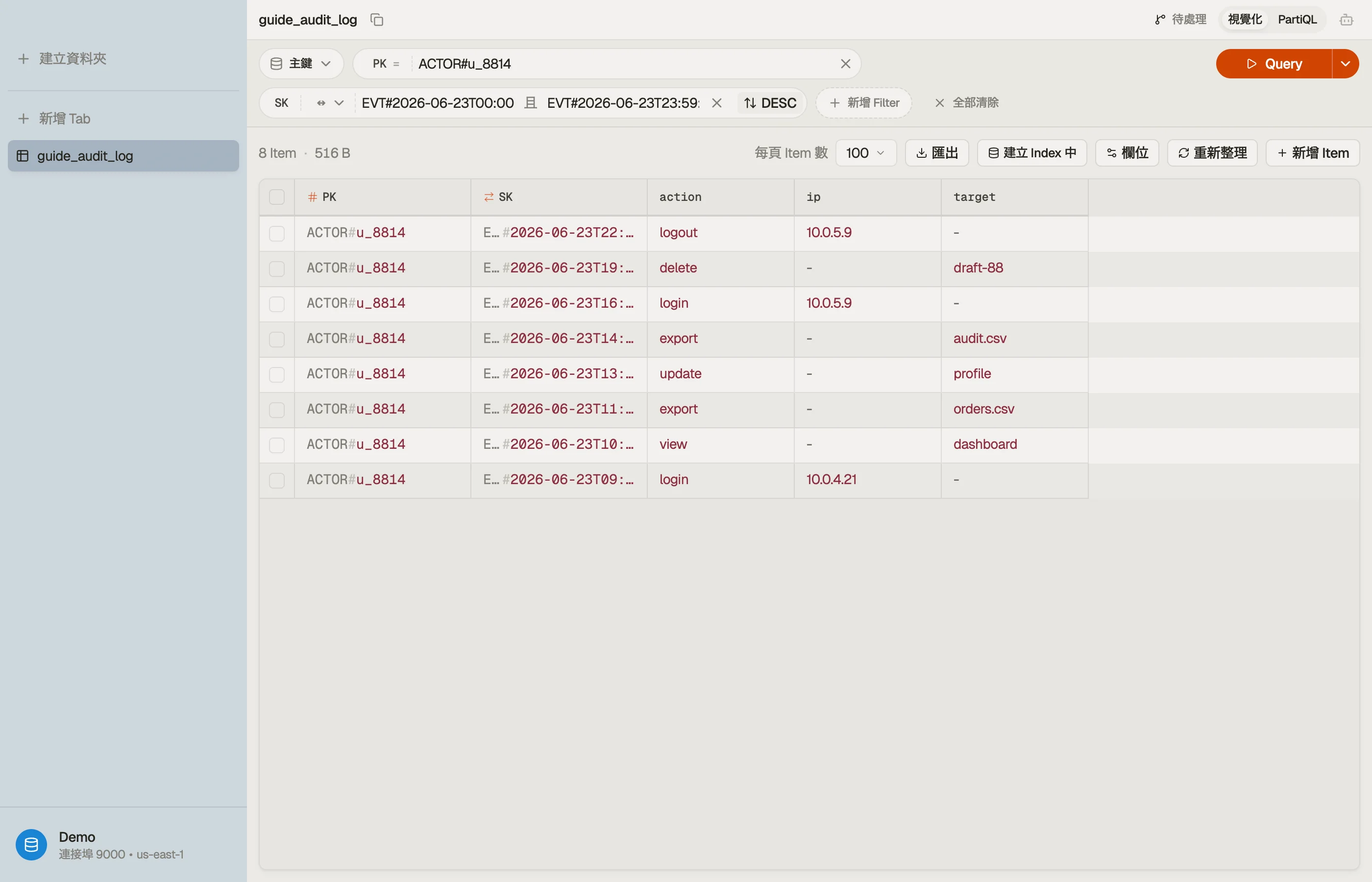

翻轉排序方向、收緊 between 邊界,看著回傳的
collection 變化,而不寫一行程式碼 — 在你定下一個 sort-key 設計
之前確認它最快的方式。
陷阱與下一步
- sort key 在一個 partition 內必須唯一。 如果兩個事件可能共用一個 時間戳,在 sort key 上附加一個區別子(一個序號或短 id), 讓複合鍵保持唯一。
- 熱 partition 無法靠排序繞過。 如果某個行為者產生遠多於 其他人的事件,sort key 救不了你 — 你需要一個能散開負載的 partition-key 設計。請見 single-table design。
- 第二種排序順序需要第二個 index。 base table 的 sort key 給出 一種排序。要以不同方式(例如依事件類型)排序同一批 item,加一個 sort key 不同的 GSI — 並權衡 local vs global secondary index 的取捨。
- 別為了「稍後再排序」而伸手去拿
Scan。 在Scan之後做客戶端 排序會讀整張表並丟掉排序;那就是 Scan 地雷。改成把順序推進 sort key。
一旦 key condition 對了,試試 DynoTable 去建模那個 collection、並排跑升序與降序查詢,並在它出貨前對真實資料 驗證你的 sort-key 策略。