DynamoDB 參照計數
參照計數 是一個你存在父項目上的數字,用來追蹤有多少子項目 指向它——貼文上的按讚、工作區裡的成員、留言上的回覆。你保留它, 是因為在每次讀取時去數子項目太昂貴了。
如何在 DynamoDB 中維護計數?
把跑動的總數以數字形式存在父項目上,並在建立子項目的同一次寫入中一併更新它。 確保兩者同時落地或同時不落地;對子項目寫入加上條件,可防止重試造成重複計數——如此一來,單一一次 GetItem 就能回傳正確的計數。
- 別在讀取時去數子項目。 一次用來數按讚的
Query會為它掃過的每個 按讚項目付費。把總數存在貼文上,改為讀一個項目。 - 在子項目被寫入的地方維護計數,而不是事後。把它和建立子項目的 同一個操作一起遞增,這樣兩者永遠不會漂移。
- 當寫入與遞增碰到不同項目時,用交易。 一個按讚是一個項目,
計數住在另一個上——
TransactWriteItems讓兩者同時落地,否則都不落地。 - 地雷是重複計數。 一個被重試或重複的按讚,重跑了遞增,就會 把數字灌大。用一個條件來護衛子項目的寫入。
為什麼要計數
從 SQL 過來,你絕不會去存按讚數——你會 SELECT COUNT(*) FROM likes WHERE post_id = ?,讓索引把它變便宜。DynamoDB 沒有那種能
跳過讀取項目的 COUNT(*)。
一次對某貼文按讚的 Query 會讀取——並計費——那個分區裡的每個
按讚項目,即使你只想要那個數字。在一篇爆紅貼文上,那就是幾千個
RCU 才能回答「有幾個讚?」那正是參照計數存在要殺掉的讀取地雷。
所以你反正規化:把跑動的總數存在貼文本身上。讀取這個計數
變成單一一次 GetItem。代價是你現在得自己負責讓它保持準確。
為項目建模
兩種項目類型共用一個分區,這樣貼文和它的按讚就坐在同一個 項目集合裡。虛構的鍵:
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
META 項目上的 likeTally 屬性就是參照計數。每個 LIKE#
項目是一個子項。把兩者都放在 PK = "POST#a91f" 底下,意味著當你真的
想要那份清單時,單一一次 Query 就能一起取出貼文和它的按讚者。
原子地遞增計數
DynamoDB 用 ADD(或 SET x = x + :n)update 運算式遞增一個數字——
這是一個原子計數器:DynamoDB 在伺服器端套用差量,不需要你先
讀取當前值,所以並行的遞增不會互相覆蓋。
(AWS:原子計數器)
問題:對一篇貼文按讚是對兩個項目的兩次寫入——建立 LIKE#
項目,並把 META 上的 likeTally 加 1。如果按讚落地了但遞增失敗,那麼
計數就永遠錯了。你需要兩者皆有,或兩者皆無。
那正是 TransactWriteItems 保證的——跨多個項目的全有或全無,
而且若任一項目被並行修改,它會取消整筆交易
(AWS:用交易做悲觀鎖定):
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Put 和 Update 一起提交。若任一失敗,DynamoDB 會把兩者一起回滾,
並回傳一個 TransactionCanceledException。
防範重複計數
真正的 bug 不是寫了一半的按讚——交易已經防住那個。它是
同一位使用者按兩次讚,或一次用戶端重試重播了請求。每次重播都加
另一個 1,而 likeTally 就悄悄漂移到真實計數之上。
Put 上的 ConditionExpression: attribute_not_exists(SK) 就是那個護衛。如果
那位使用者的 LIKE# 項目已經存在,Put 的條件就失敗、整筆
交易被取消,而且——關鍵地——ADD 永遠不會執行。每位使用者一個讚,
由鍵來強制。
在 DynamoDB 運算式建構器裡建立並複製這些
update 和 condition 運算式——附上正確的
ExpressionAttributeValues 與 attribute_not_exists 護衛——而不是
手動拼湊那段 JSON。
取消讚,以及成本
移除一個讚是鏡像:Delete 那個 LIKE# 項目,附上
ConditionExpression: attribute_exists(SK),並在同一筆交易裡 ADD likeTally :minusOne。
這個條件阻止重複取消讚把計數壓成負數。
要知道價碼。對於最大 1 KB 的項目,一次交易式寫入每個項目花 2 WCU—— 一個用來準備、一個用來提交——而一次普通寫入是 1 WCU。一個讚是兩個項目, 所以每個讚大約是四個 WCU。每個動作很便宜,但在一篇名人貼文 引發按讚風暴前,值得先知道。
在 DynoTable 裡看它
當你懷疑某個計數已經漂移,你會想把存下的 likeTally
和實際的 LIKE# 子項數量做比對——而不必在正式環境跑一次計數查詢。

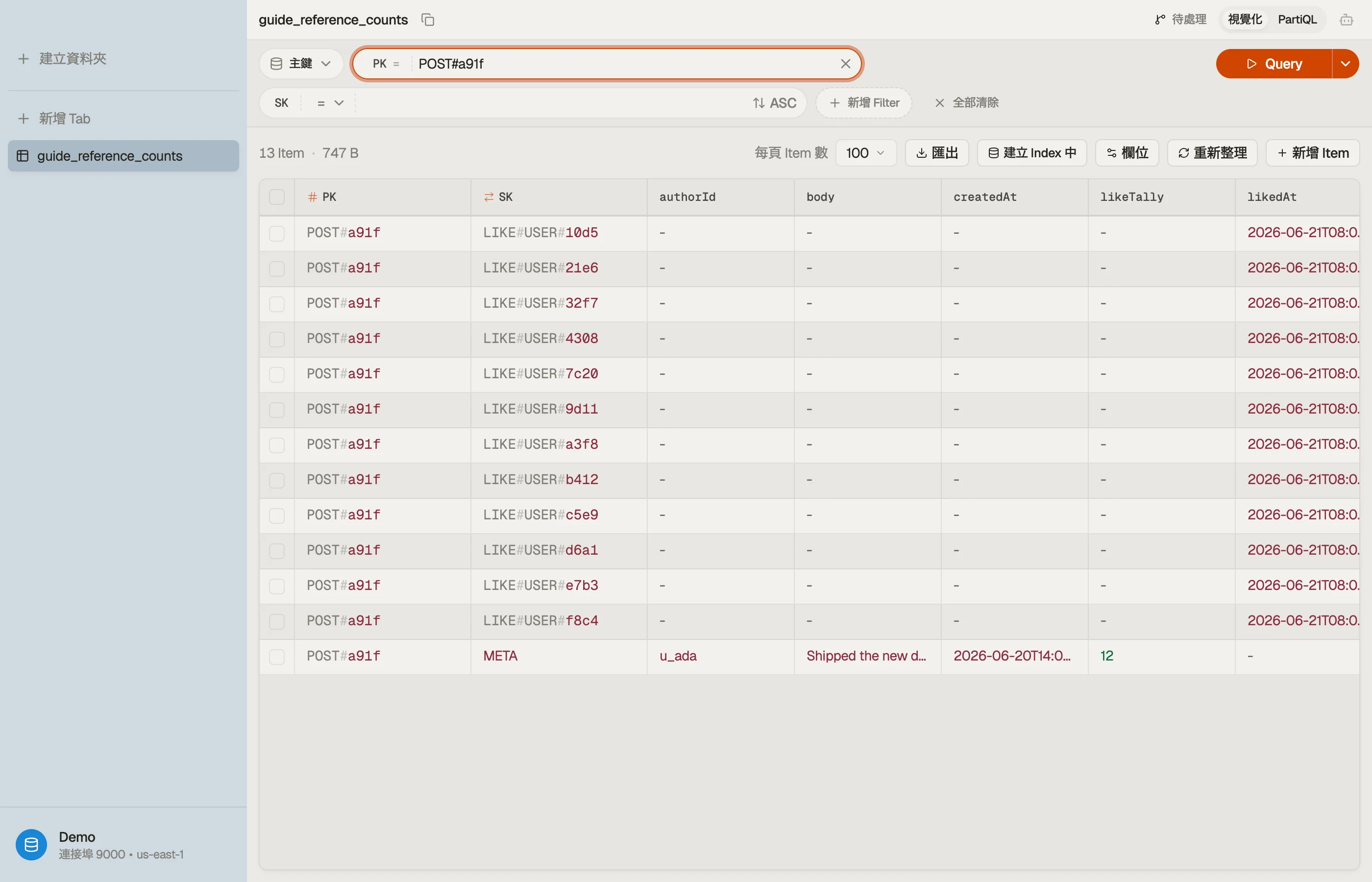

要對一組有界的貼文做真正的對帳——「哪些計數和它們的
子項數量對不上?」——DynoTable 的 SQL Workbench 會在你已載入的列上,於
用戶端跑那個 GROUP BY 和 join,而那是純 PartiQL 表達不出來的。
陷阱與後續步驟
- 別在帶外維護計數(一個每晚重新計數的 Lambda)。那是替一條 本該從一開始就交易式的寫入路徑貼 OK 繃。
- 小心熱分區。 一篇瘋狂爆紅的貼文會把每個讚—— 和每次計數遞增——集中到單一分區鍵上。計數是正確的;分區 卻可能仍然節流。
- 少對帳、外科式修補。 如果每個變更都加了條件,漂移應該近乎零。 把不一致當成一個要找出的 bug,而不是一個要覆寫的數字。
延伸閱讀:單一資料表設計了解為什麼貼文 和按讚共用一個分區;以及 Query 與 Scan了解為什麼 在讀取時去數子項,正是你在避開的那個模式。
接著下載 DynoTable來檢查這些項目集合,並對著你自己的 資料表驗證你的計數。