DynamoDB 稀疏 Index
一個 稀疏 index 是只保留帶有其 key 屬性的 item 的次要 index — 這樣一個巨大表中一小撮熱門子集,就變成它自己預先過濾好、 可立即查詢的 collection。
你有數百萬列,但你整天跑的查詢只觸及極小一片: 開啟中的支援工單、未付的發票、被標記待審查的帳戶。
過濾那一片仍會掃描整張表,並就每次讀取對你計費。一個 稀疏 index 改成讓 index 本身變小。
DynamoDB 中的稀疏 index 是什麼?
稀疏 index 是一種只保留帶有其 key 屬性的 item 的次要 index。由於 DynamoDB 會跳過任何缺少該 key 的 item,你只需在想要的 item 上寫入一個專屬 key — 例如開啟中的工單、未付的發票 — index 就會精準地成為那個子集。Query 便只讀取它,不需過濾,不浪費讀取容量。
- 次要 index 只會索引帶有其 key 的 item。 在某個 item 上省略那個 key, 它就永遠不會進入 index — 沒有佔位、沒有 null 列。
- 所以你發明一個只有想要的 item 才會帶的 key。 在你查詢的 item 上寫它, 在其餘的上移除它。index 就剛好成為那個子集。
- 查詢只讀那個子集,不用過濾。 它的大小追蹤那一小撮熱門 集合,而非表的總量。
REMOVE才是槓桿,而非清空。 空字串仍是一個值,仍會 被索引 — 你必須刪除那個屬性。
問題:過濾不會省下讀取
從 SQL 過來,你假設一個 WHERE 子句會縮窄工作量。DynamoDB 的
FilterExpression 不會。它在 item 被讀取 之後 才執行,而非之前。
依據 AWS 開發人員指南, 過濾「不會減少消耗的讀取容量」 — 你為每個被檢視的 item 付費, 然後把不符合的丟掉。
所以如果你 500 萬筆工單中有 50 筆開啟中,一個過濾的 Query/Scan 會
讀過數百萬筆,才把那 50 筆交給你。
那就是每個「為什麼我的 scan 這麼貴」討論串背後的地雷; query vs. scan 有完整的成本全貌。
一個稀疏 index 透過讓 index 本身變小來繞開它。
稀疏性如何運作
一個次要 index 只會索引實際帶有 index key 屬性的 item。
AWS 關於 global secondary index 的文件 講得很白:「global secondary index 只包含帶有為該 index 定義的 key 屬性的 item。」
某個 item 上漏掉 GSI 的 partition key(或 sort key),DynamoDB 就乾脆不把 它寫進 index。沒有佔位、沒有 null 列 — 那個 item 缺席。
那個「預設缺席」就是整個訣竅。別去索引 每個 item 都帶有的 status
屬性。發明一個 只有你想查詢的 item 才會帶 的屬性。
index 於是成為剛好是那些 item 的一份乾淨清單,而對它的一個 Query
只讀它們 — 不用過濾、不浪費容量。
想像 base table 餵給 index,只有帶 key 的 item 越過去:
只有帶 key(開啟中)的 item 複製到 index;已關閉的 item 從不進入它。
這跟 single-table design 是同一套塑造 key 的 心態:key 是你為特定存取模式打造的工具,而非你資料的 忠實鏡像。
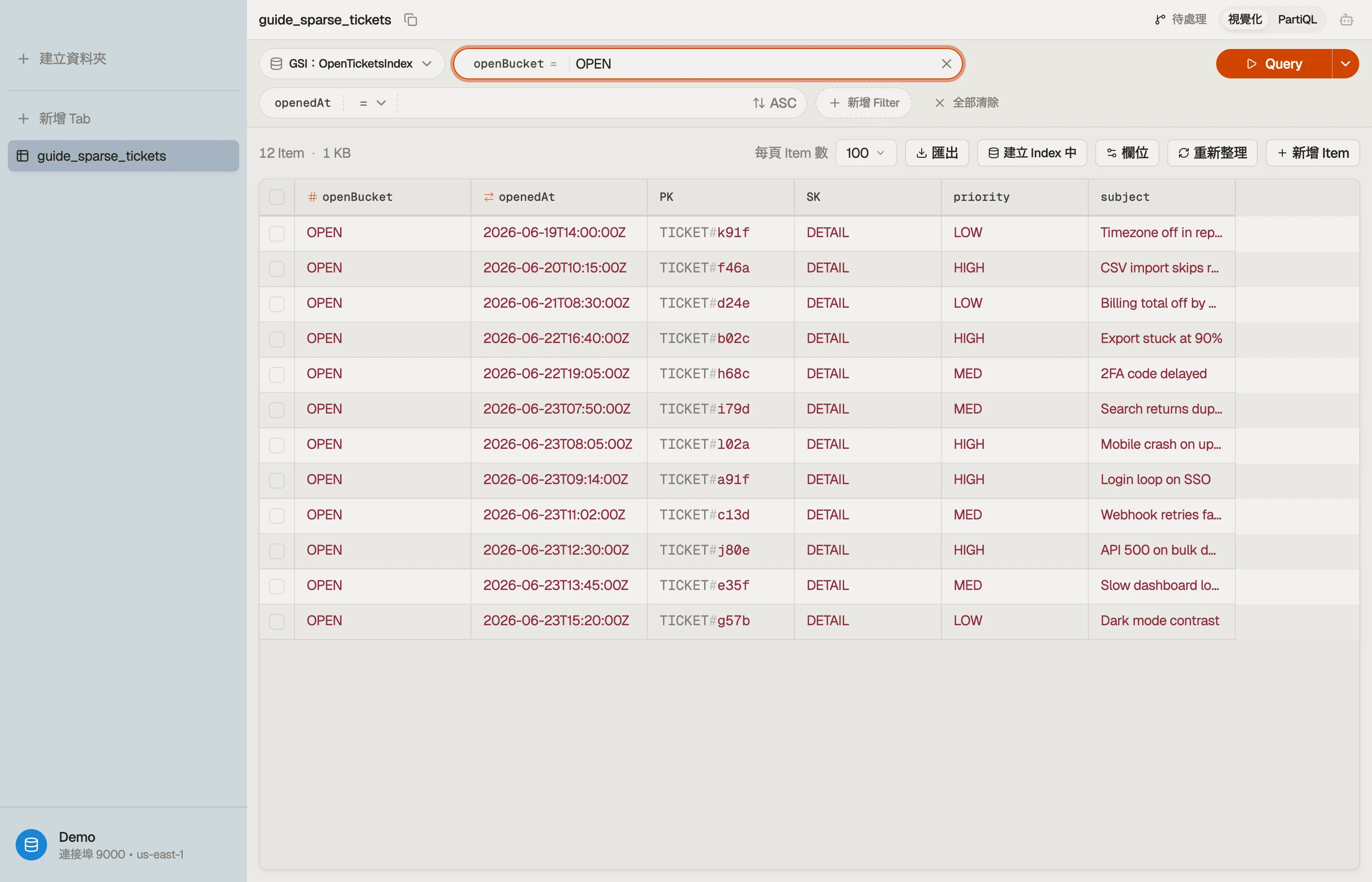
演練範例:「僅開啟中的工單」
拿一張支援工單表。base table 的 key 設計用於依 id 取得一筆工單, 以及列出某客戶的工單:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
在表的生命週期裡,大多數工單最終都會 關閉。但你的客服整天打的 儀表板查詢是「給我每筆開啟中的工單,最舊在前」 — 數百 列藏在數百萬筆之中。
稀疏 index 的招式:定義一個 partition key 為 openBucket、sort key 為
openedAt 的 GSI,並 只在開啟中的工單上寫 openBucket。在
工單建立時設定它;在工單解決時 REMOVE 它。
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← 開啟中:在 index 內 |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← 開啟中:在 index 內 |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← 已關閉:不在 index 內 |
工單 a91f 與 b02c 帶有 openBucket,所以它們住在 GSI 裡。工單
77de 已解決且 openBucket 被移除,所以它悄悄掉了出去。
儀表板現在是一個便宜的查詢:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # 最舊在前這只讀開啟中的工單。隨著工單關閉,index 會自行縮小 — 它的 大小追蹤 開啟中 的數量,從不追蹤總量。
一個靜態的 partition 值("OPEN")在這裡沒問題,正因為集合保持
小巧。一個龐大的開啟集合會需要分片的 partition key,但「小子集」
index 正是一個值才是對的選擇之處。
讓它運作的轉換,是單一的 update expression — 在工單解決時 移除那個屬性。
在 DynamoDB Expression Builder 中原型
那個 REMOVE 子句與讀取端的型別化 key condition,而不必自己
手動組裝 ExpressionAttributeNames 與 :val 佔位符。
在 DynoTable 中做它
稀疏 index 的難點不在讀取 — 而在 看見 哪些 item 進了 index、哪些悄悄掉了出去。
DynoTable 讓你把表格檢視切換到一個次要 index,看見剛好就是那個
被填入的子集。這樣你就能確認一筆已解決的工單真的離開了
open-tickets-index,而不是帶著陳舊的 key 還滯留著。


陷阱與下一步
幾件要留意的事:
- 移除那個 key,別清空它。 空字串仍是一個值,而
DynamoDB 會索引一個
openBucket為""的 item。要把一個 item 從 index 移除,你必須REMOVE那個屬性 — 把它設為一個假值會讓它留下來。 - index 是最終一致。 GSI 非同步更新,所以一筆 剛解決的工單可能會短暫地仍然出現 — GSI 讀取 僅支援最終一致。 別信任它去判斷「這筆工單現在是否開啟中」。
- 留意投影的屬性。 對 index 的一個
Query只回傳 投影進它的屬性。如果儀表板需要 subject 與 priority,就 投影它們 — 否則為完整的 base item 多付一次GetItem。 - 這是 GSI 的強項,而非 LSI 的。 local secondary index 共用 base table 的 partition key,無法這樣選擇性地丟掉 item。 GSI vs. LSI 拆解了這個權衡。
稀疏 index 是這套模型中最古老的點子之一。原始的 2007 Amazon Dynamo 論文 把這個 store 圍繞著便宜地服務已知、高流量的存取模式來打造。
一個稀疏 index 正是如此:塑造 key,讓常見查詢不讀任何 它不需要的東西。
要真正建立並檢視一個,下載 DynoTable,把它指向 你的表,並把資料檢視翻到你的稀疏 GSI — 看著子集隨 item 取得與失去 index key 而更新。