DynamoDB 索引投影:KEYS_ONLY、INCLUDE 與 ALL
當你建立一個次要索引時,DynamoDB 不會自動把整個 item 複製進去。 你要選擇哪些會被複製——也就是這個索引的投影。選太少,你的 查詢就得付出第二次讀取去取回其餘部分;全選,你則在每次更新時付出 額外的儲存與寫入成本。這是一個你在建立索引時設定一次、然後就得一直 承受的取捨。
(別把這個跟投影運算式(projection expression)搞混,後者是修剪 單次讀取所回傳的屬性。本頁談的是索引實際儲存了什麼——關於 另一個概念,請見投影運算式。)
什麼是 DynamoDB 索引投影?
投影就是 DynamoDB 從 base table 複製進次要索引的那組屬性。你要從三種類型中擇一:KEYS_ONLY(只有索引鍵)、INCLUDE(索引鍵加上一份指名的屬性清單),或 ALL(整個 item)。投影越多,需要回到 base table 取資料的次數越少,但儲存與寫入成本也越高。
- 一個投影就是被複製進一個次要索引的那組屬性。
KEYS_ONLY— 只有資料表與索引的索引鍵。最小、最便宜。INCLUDE— 索引鍵,加上一份你指定的額外屬性清單。ALL— item 的每一個屬性。最大;查詢永遠不需要 base table。- 對 GSI 讀取一個未被投影的屬性,會強制從 base table 取回它——這是 一筆無聲的額外成本。(一個 LSI 可以 替你取回未投影的屬性,但要 付出額外的讀取成本。)
- 投影越多 = 越多儲存 + 越多寫入成本,因為每一次 base-table 寫入 都會傳播到索引。
問題:那個害你讀兩次的索引
假設你經營一個客服中心,用一個 GSI 讓你能依優先順序列出未結工單。
你投影 KEYS_ONLY 以保持精簡。查詢回傳得很快——但它只給你工單 ID,
而你的佇列畫面需要每張工單的主旨、受指派人與存在時間。
於是現在你的程式碼要對 base table 做第二輪讀取,來把每一筆結果補齊。 你設計的那「一次查詢」其實是一次查詢外加 N 次 get,而你原本想省下 的延遲與成本又全回來了。對這個存取模式來說,那個投影太單薄了。
各種投影類型會複製什麼
KEYS_ONLY只儲存 base-table 鍵以及索引鍵。當查詢只需要 知道哪些 item 符合、而你會在別處取回細節(或根本不取)時,就用它。INCLUDE儲存索引鍵,加上一份你指名的固定屬性清單。最佳 平衡點:剛好投影你的查詢要繪製所需的欄位,不多不少。ALL複製整個 item。查詢完全從索引自給自足,代價是把整個 item 的儲存與寫入輸送量都複製進索引。
對這個客服佇列來說,用 INCLUDE 搭配 subject、assignee 與 age
才是對的選擇——佇列只靠索引就能繪製,不需要第二次讀取,也不必把
工單龐大的 body 複製進索引。
你正在權衡的成本
你投影的每一個屬性都會被
儲存第二份,
而且每當 base item 變動時就在索引裡被重寫一次。所以在一張頻繁
更新的表上採用大方的 ALL 投影,會讓儲存與寫入容量雙雙倍增。紀律
是:投影查詢會讀的東西,而不是「全部都來,以防萬一」。
一個值得知道的細節:在一個稀疏索引上,投影仍然只容納那些帶有
索引鍵的 item——所以在一個稀疏索引上
採用 INCLUDE/ALL 仍會維持很小,因為索引本身就很小。用
DynamoDB pricing calculator 衡量你投影
的儲存與寫入倍率,並用
DynamoDB expression builder 組裝索引
查詢本身。
在 DynoTable 中看見投影
DynoTable 會列出一張表的每一個次要索引,並讓你直接透過其中一個來 查詢。對 base table 與對一個 GSI 跑相同的存取模式,再比較結果——索引 結果中缺少的那些屬性,正是它沒有投影的那些,所以一個投影的效果不用 重讀資料表定義就看得見。

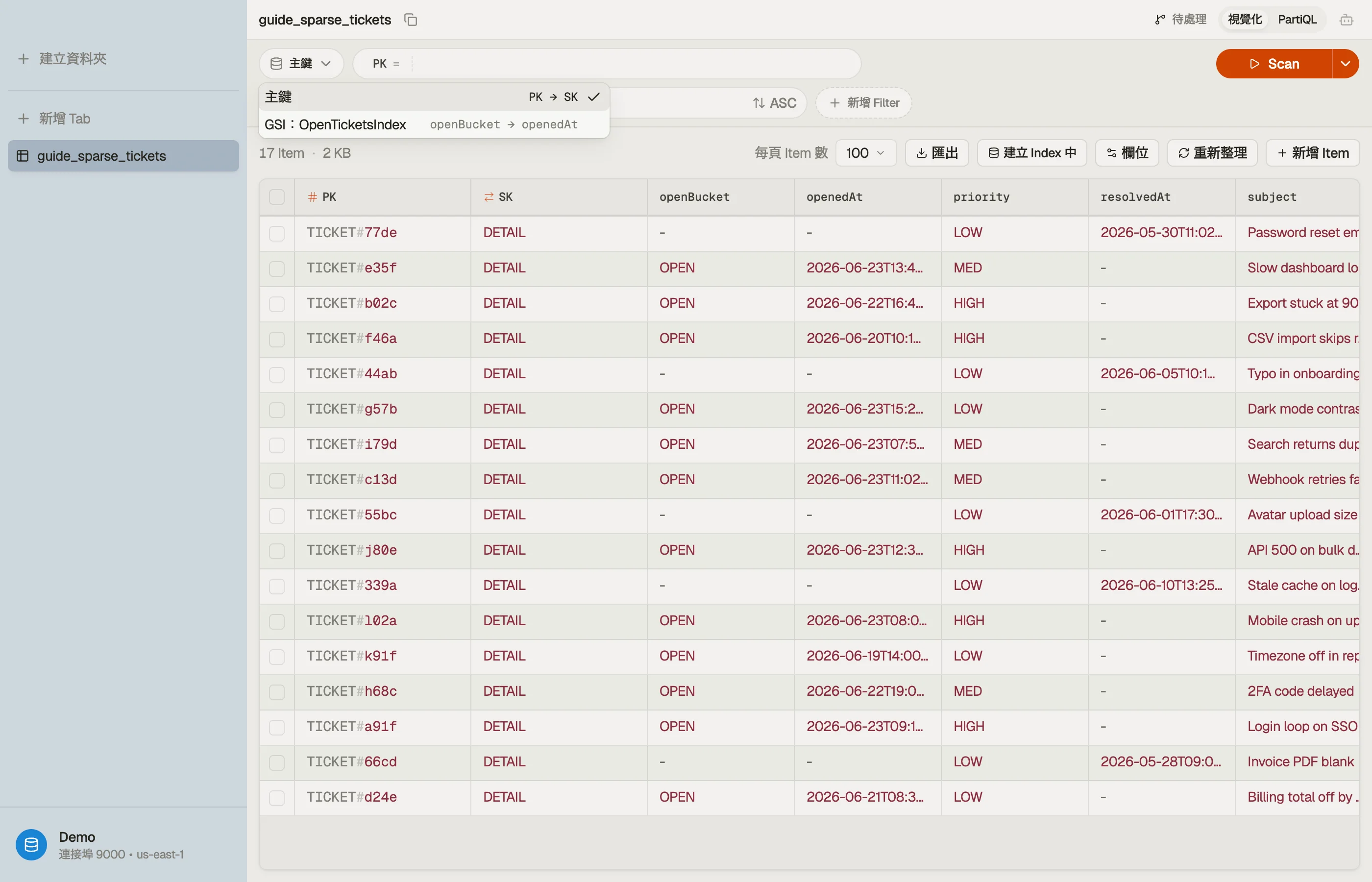

陷阱與下一步
- GSI 上一個未投影的屬性,意味著一次 base-table 讀取 — 圍繞查詢 所繪製的內容來設計投影。
ALL很少是免費的 — 它會讓儲存與寫入成本翻倍;除非索引真的 需要每一個欄位,否則預設用INCLUDE。- 投影大致上是固定的。 你之後無法不重建索引就自由編輯一個 GSI 的投影——一開始就要審慎選擇。
- 相關: GSI vs LSI 與 稀疏索引決定了一個投影實際上儲存多少。
想在重新設計之前,看看你每一個索引實際回傳什麼嗎? 下載 DynoTable,直接查詢你的表格。