DynamoDB 的多對多關聯
一個學生選修多門課;一門課收容多名學生。在 SQL 裡你會伸手去拿
一張 join 表,加上四路的 JOIN。
DynamoDB 沒有 join,所以關聯必須存在於 key 中 — 而
訣竅是把每條註冊邊以一種讓兩邊都能直接 Query 的形狀儲存。
本指南從頭到尾走過 students ↔ courses 問題:存取模式、解決它們的 鄰接清單模式、一份你可以照抄的原始 key schema,以及如何讀回雙向, 而完全不掃描整張表。
如何在 DynamoDB 中建立多對多關聯的資料模型?
DynamoDB 沒有 join,所以你要用模式來建立多對多關聯的資料模型:把每條連結儲存為以一端為 key 的獨立 edge item,再加上一個交換 key 的反轉 GSI。一條邊只寫一次,就能從兩個方向廉價地回應查詢。
- 把每筆註冊當成它自己的 edge item 儲存,而非任一邊上的清單屬性。
- 以學生為 key 來建這條邊(
PK = STU#…、SK = ENROLL#CRS#…),讓一個Query回傳某學生的整份課程清單。 - 加上一個反轉的 GSI,把角色對調(
GSI1PK = CRS#…),讓同一條邊 也能回答「誰在這門課裡?」。 - 一條邊,寫一次,雙向都讀得便宜 — 這就是整場遊戲。
先框定存取模式
DynamoDB 建模是存取模式優先:你在挑選任何單一屬性名稱之前,先決定 讀取。一個多對多關聯幾乎都有 兩個 對稱的 讀取,加上實體查詢:
- 取得某學生的個人資料,並 列出該學生選修的每一門課。
- 取得某門課的中繼資料,並 列出選修該課的每一名學生。
- 查詢單一註冊邊 — 用來更新成績或退選。
痛點:兩個列表讀取在同一組邊上指向相反方向。一個天真的
設計把其中一邊服務得很便宜,卻逼另一邊用 Scan — 正是
Query vs Scan 涵蓋的那個地雷。
任務是讓 兩個 方向都成為單一 Query。
使用鄰接清單模式
DynamoDB 自己針對關聯的指引就是 鄰接清單:把每個 關聯建模成一個 item,其 partition key 是一個端點、sort key 是 另一個端點。
AWS 在 DynamoDB 開發人員指南的 Best Practices for Managing Many-to-Many Relationships 頁面記載了這一點。
為什麼用 key 而不是第二張表?因為 DynamoDB 給你的原語是對單一
partition 的 Query。
一個 Query 在一個 partition key 底下讀取 sort-key 值的連續範圍,於一個
計費操作中完成 — 那是引擎提供的唯一「join」。
要得到一個能從 兩邊 都讀得便宜的關聯,你把這條邊複製一份: 以學生為 key 寫一次,然後用次要 index 把同一條邊以課程為 key 投影出來。
這就是 Single-Table Design 那套 overloaded-key 思維,套用到一個關聯而非父子階層上。
形狀就是同一條邊的兩個堆疊檢視 — base table 以學生為 key、 反轉的 GSI 以課程為 key:
每條邊在 base table 上寫一次,並以 key 對調的方式投影進 GSI,
這樣對任一 partition 的 Query 都能便宜地讀取該關聯。
這脈絡可追溯到 2007 年 Amazon 的 Dynamo 論文: partition key 是分散的單位,而單一 key 存取是快速路徑。
DynamoDB 中的關聯,就是一場把多對多讀取折進那條快速 路徑的練習。
演練範例:students ↔ courses
使用一張表搭配通用 key PK 與 SK,並把實體類型編碼進
值。註冊邊是核心所在:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
單一 Query PK = "STU#a91" 會在一次讀取中回傳該學生的個人資料 以及
每筆註冊。用 SK begins_with "ENROLL#" 縮窄,就只取得課程邊。
這解決了「列出某學生的課程」。
但「列出某門課的學生」指向另一邊 — 而 base table 無法回答 它,因為學生 id 在 partition key 裡,不在 sort key 裡。
加上一個反轉的 global secondary index,把角色對調。給 edge item 一組
通用的 GSI1PK/GSI1SK,partition 邊放課程、sort 邊放
學生:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
現在 Query GSI1 WHERE GSI1PK = "CRS#math204" 會列出那門課的每一名學生 —
base table 無法服務的讀取。一個 edge item,寫一次,回答了
雙向。
它必須是 GSI,而非 LSI:課程 partition 與學生 partition 完全 不同,而 LSI 共用 base table 的 partition key。
這個 index 橫跨多個 partition,所以必須是 global — 請見 GSI vs LSI。
一個要注意的點:DynamoDB 中的 GSI 是非同步填入的。一筆全新的註冊
可能需要片刻才會在 CRS#… 方向出現。
把課程名單讀取當成最終一致 — 開發人員指南針對 global secondary index 明確點出這一點。
在 DynoTable 中寫入並讀取
寫入註冊意味著設定四個 key 屬性,加上邊本身的資料。阻止
學生在同一門課重複註冊的條件,是對複合 key 的一個
attribute_not_exists(PK) 守衛。
這正是你可以用 DynamoDB Expression Builder
視覺化組裝的那種條件,而不必手寫
ExpressionAttributeNames 與佔位符值。
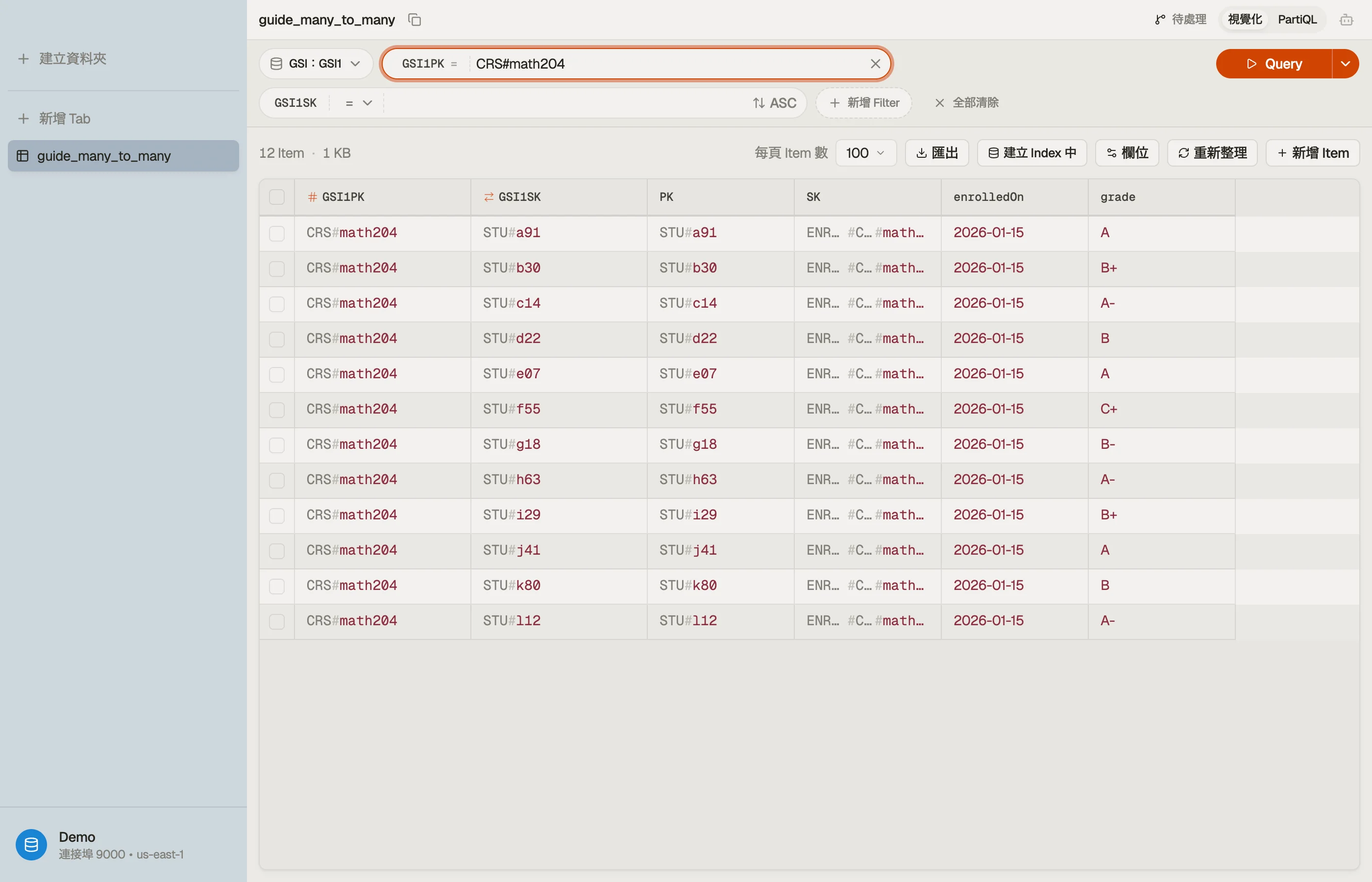
在 DynoTable 裡,你把一個 Query 指向 GSI1、設定 GSI1PK = "CRS#math204",
名單就以一張你能讀、能排序、能就地編輯的表回傳 — 關聯的雙向
都能從一個 schema 瀏覽。


陷阱與下一步
- 別把其中一邊存成清單屬性。 學生 item 上的
courseIds陣列 感覺很整齊,直到某門課需要它的名單、陣列撞上 400 KB item 上限,或 兩筆註冊競爭並互相覆蓋。離散的 edge item 能各自獨立地 擴展與更新。 - 把邊的資料留在邊上。 註冊的
grade與enrolledOn屬於 edge item,而非重複複製到學生或課程上 — 每個 (學生, 課程) 配對剛好有一列要更新。 - 留意 GSI 傳播。 反轉 index 的方向是最終一致,所以一筆在 註冊後立刻進行的讀取,可能會落後幾分之一秒。
- 只投影名單需要的東西。 當名單檢視只需要 id 時,一個
KEYS_ONLY或 狹窄的投影能讓 GSI 保持小巧。
要深入周邊模式,請讀 Single-Table Design 了解 overloaded key,以及 GSI vs LSI 了解何時反轉 index 必須是 global。
然後 下載 DynoTable 真正地把 students ↔ courses schema 建模 — 寫下這些邊、用 Expression Builder 建立條件,並查詢關聯的 雙向,連一次掃描都不用。