DynamoDB 的鄰接列表模式
一張圖不過是節點和邊,而鄰接列表模式把兩者都當作一張表裡的普通項目來存。每條邊變成一列,它的分割鍵是來源節點,排序鍵是目標。查詢一個分割就列出每一個鄰居——這是 DynamoDB 對連接表上 JOIN 的替身。
什麼是 DynamoDB 的鄰接列表模式?
鄰接列表模式把一張圖建模成一張表裡的邊項目:每個關係(A 追蹤 B)都是一列,分割鍵放來源、排序鍵放目標。查詢一個分割就列出每一個鄰居,而一個翻轉過的 GSI 會反轉這個關係——沒有 join、沒有掃描,兩個方向都在單一查詢裡完成。
- 邊就是項目。 把每個關係(使用者 A 追蹤使用者 B)建模成它自己的項目,分割鍵放來源、排序鍵放目標。
- 一個方向免費;另一個方向需要 GSI。 基礎表回答「A 追蹤了誰?」。一個翻轉過的索引回答「誰追蹤 A?」。
- 沒有 join,沒有掃描。 兩個方向都是針對一個已知分割的單一
Query——絕不是一次全表Scan。 - 它是多對多的基本元件。 追蹤、成員身份、按讚、好友關係——任何一個實體連到許多其他實體的圖,都合這個形狀。
把它框成存取模式
從 SQL 過來,一張追蹤圖是一張連接表:follows(follower_id, followee_id)。要列某人的追蹤者你索引一個欄;要列他追蹤了誰你索引另一個欄。DynamoDB 沒有 join,所以你設計鍵來直接服務每一次讀取。
先把那些讀取寫下來。對一張社群追蹤圖:
- 使用者 A 追蹤了誰?(他的追蹤中列表)
- 誰追蹤了使用者 A?(他的追蹤者列表)
- A 有追蹤 B 嗎?(一次單點查找)
鍵的存在,只是為了回答那份列出。把它們設對,每一次讀取就是一次 Query 或 GetItem。
把邊建模成項目
用通用的鍵名稱,好讓表能裝下不只一種實體類型,並把節點類型編碼進值裡。一條追蹤邊長這樣:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
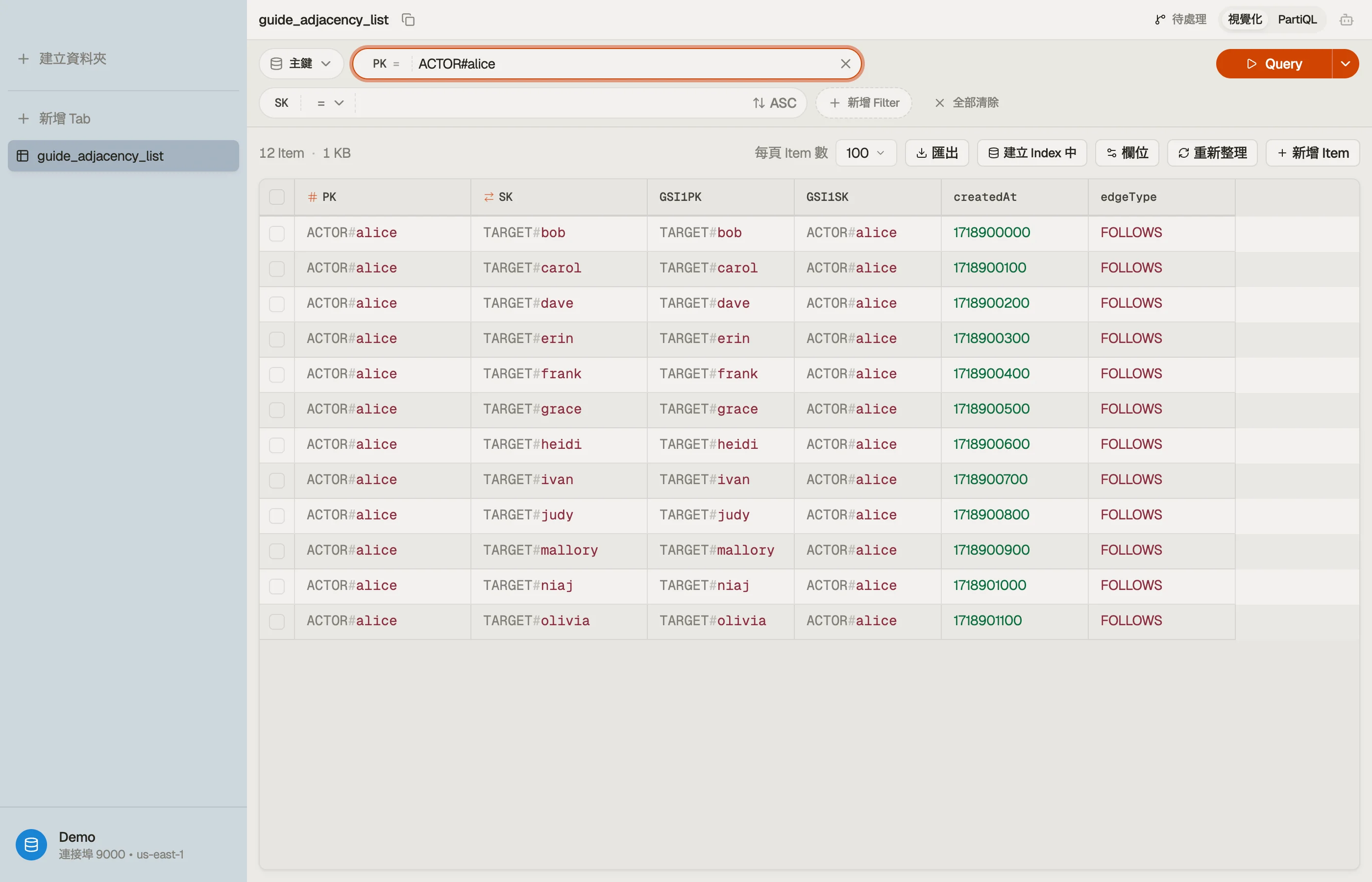
PK = ACTOR#alice 是邊的來源;SK = TARGET#bob 是她追蹤的對象。一次 Query PK = "ACTOR#alice" 在一次計費的讀取裡回傳 Alice 追蹤的每一個帳號——她整份追蹤中列表,沒有 join。
每條邊只寫一次,方向是「我追蹤誰」。反方向(「誰追蹤我」)是基礎表回答不了的部分——目前還不行。
用 GSI 走訪另一個方向
基礎表是來源優先設鍵的,所以它沒辦法不掃描就回答「誰追蹤 Bob?」。加一個全域次要索引來翻轉鍵:把目標投影到索引分割鍵,把來源投影到索引排序鍵。
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
現在 Query GSI1 WHERE GSI1PK = "TARGET#bob" 在一次讀取裡列出所有追蹤 Bob 的人——alice 和 dave。同一個邊項目同時服務兩個方向:基礎表是追蹤中,索引是追蹤者。你把每條邊只寫一次,就免費拿到兩個查詢。
這正是 AWS 在它的 DynamoDB 最佳實務指南裡,為了建模多對多關係與圖資料所記載的模式——把邊存成項目,再用一個 GSI 把關係反轉。
便宜地檢查單一條邊
「Alice 有追蹤 Bob 嗎?」不需要任何一份列表。因為那條邊以 PK = ACTOR#alice、SK = TARGET#bob 設鍵,它是一次直接的 GetItem——DynamoDB 所提供最便宜的讀取,沒有 Query,沒有索引。
要冪等地寫入這個追蹤並避免重複計數,用一個「該邊尚不存在」的條件來守衛 PutItem:
attribute_not_exists(PK)你可以用 DynamoDB expression builder 組出那個條件——以及那些 marshalled 過的鍵值——而不必手寫 ConditionExpression 與 ExpressionAttributeValues。
在 DynoTable 裡做
當你瀏覽這張表時,一個 actor 的那些邊會堆在單一個分割鍵之下、成為一個項目集合,而切換到 GSI 檢視則顯示反轉過的追蹤者列表——關係的兩半並排在一起。


陷阱
名人分割。 一個有數百萬追蹤者的使用者,會把每一條追蹤者邊都集中在單一個 GSI1PK = TARGET#<star> 分割之下。讀取那個集合會被分頁,而且可能跑得很熱。對扇出繁重的圖,把熱鍵分片(例如 TARGET#bob#0..N),或反正規化計數,這樣你就不必每次都重讀整份列表。
把計數存在邊上。 一個追蹤者計數不是一條邊——別靠每次看個人檔案就讀取並計數整個分割來推導它。在使用者項目上維護一個計數器屬性,並在交易裡跟邊一起更新它。
別忘了這裡不需要反向寫入。 一個經典的鄰接列表變體,會把邊用對調的 id 寫兩次。有了翻轉鍵的 GSI,你只寫一次,讓索引去把反向具現化——更少的寫入,兩份複本之間也沒有漂移。
下一步
鄰接列表是單表設計的關係積木;那個反轉的索引是一個 GSI,不是 LSI,因為分割鍵變了。而這裡的每一次讀取都是針對一個已知鍵的 Query 或 GetItem——絕不是那個 Scan 地雷。
用 DynamoDB expression builder 建好條件與鍵表達式,然後下載 DynoTable,對你自己的表建模一張追蹤圖,看著兩個方向在一次讀取裡解析出來。