DynamoDB 中的一对多关系
SaaS 控制平面几乎总有一层包含层级:一个工作区拥有多个项目。在 SQL
里,你会在项目表上放一个 workspace_id 外键,然后 JOIN。
DynamoDB 没有连接,也没有外键,所以这种关系必须存在于键 schema 本身之中。做对了,
"加载一个工作区及其内部的每个项目"就变成单次 Query,而不是一次读取加上后续的扫描。
如何在 DynamoDB 中建模一对多关系?
让父项及其所有子项共享同一个分区键,使它们落入同一个项集合,再用排序键加以区分。DynamoDB 没有连接也没有外键,所以关系必须体现在键 schema 本身之中。这样一来,加载父项及其所有子项就变成单次 Query,而不是一次连接。
- 建模读取,而非实体。 一对多关系存在的唯一目的就是服务于"列出某个工作区的项目" ——围绕这个查询来塑造键。
- 把父项编码进子项的分区键。 让工作区及其所有项目共享同一个分区键值,使它们落入 同一个项集合。
- 于是列表读取就是一次
Query。 父项加上任意数量的子项在单次计费调用中全部返回 ——没有连接,没有第二次往返。 - 当心热分区。 一个巨大的租户会把它的全部流量集中在一个分区上;一个超大的工作区 可能需要分片键和扇出读取。
先看访问模式
DynamoDB 建模是访问模式优先,而非实体优先——这与 单表设计背后的纪律一致。在选择任何键之前,先写下 应用真正会发出的读取:
- 获取某个工作区的设置。
- 列出某个工作区中的每个项目,最新优先。
- 通过 id 获取某个特定项目。
"一个工作区、多个项目"这种关系之所以重要,完全是因为读取 #2。如果你从不需要把一个 工作区的项目一起列出,你根本就不会去建模这种关系——你会把项目独立存储。
所以问题从来不是抽象地"我该怎么表示一对多?",而是"这种关系必须服务哪些查询?"。 回答它,然后围绕它塑造键。
为什么外键在这里帮不上忙
在 DynamoDB 中,每个 GetItem 和 Query 都针对一个分区键,服务会对该键做哈希,
以定位持有该项的分区。
AWS 在 Core Components 文档里直接讲明了这一点:分区键值是一个内部哈希函数的输入,由它决定数据存放在哪里。
这种基于哈希的放置,继承自最初 2007 年的 Dynamo: Amazon's Highly Available Key-value Store 论文,论文中用一致性哈希把键分布到各个节点。
项目项上一个光秃秃的 workspace_id 属性 对那套机制是不可见的——DynamoDB
没法"跟着它走"。
要在一次请求中取回相关项,父项的身份必须被编码进项目的分区键,这样一个工作区的
所有项才会哈希到同一个分区,一次 Query 就能把它们一扫而尽。
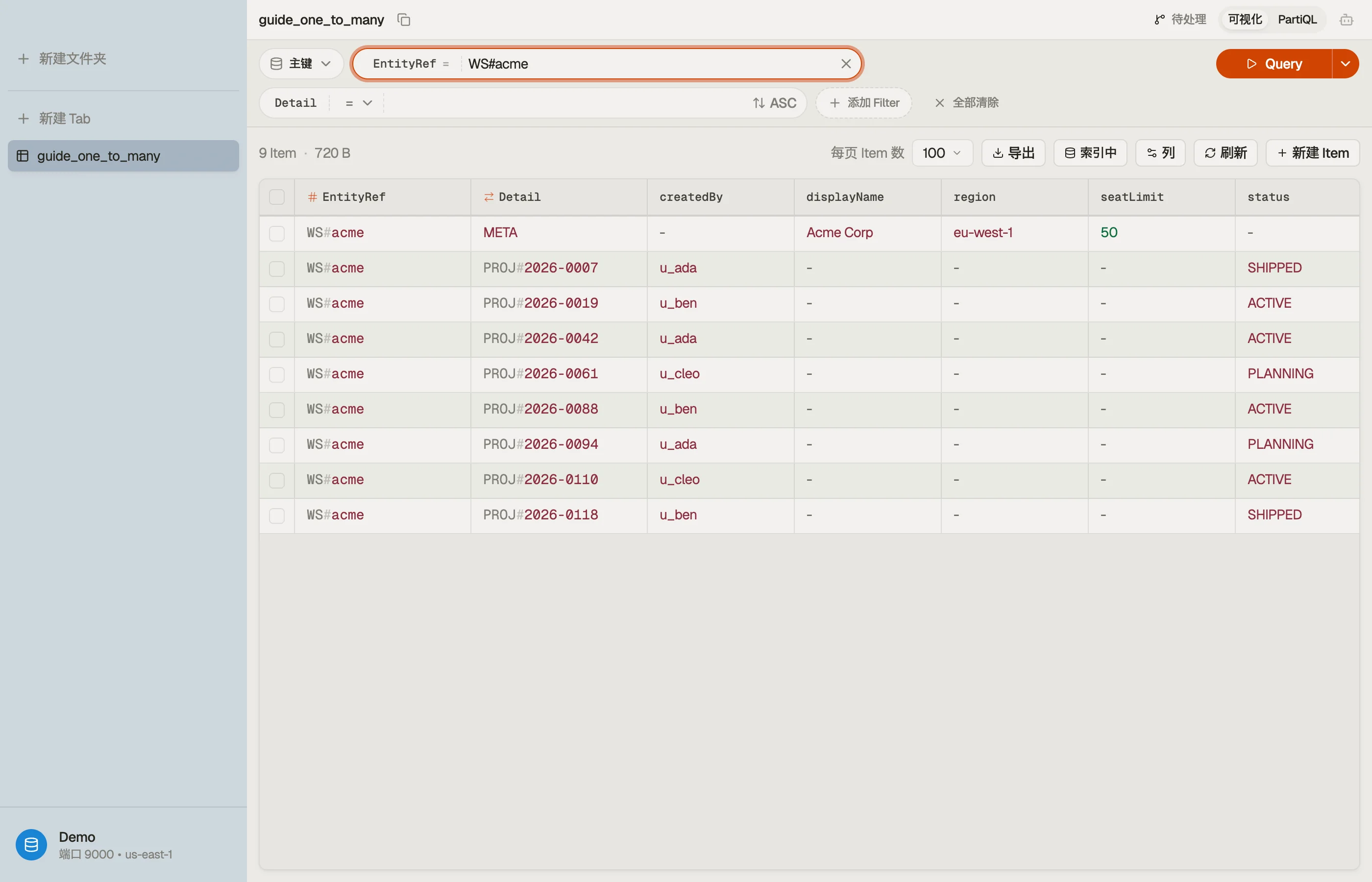
实例演练:工作区与项目
使用一个通用的、重载的键 schema。把分区键叫作 EntityRef,排序键叫作 Detail。
工作区的身份既进入工作区项的 EntityRef,也进入其下每个项目项的 EntityRef:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
工作区及其所有项目共享 EntityRef = "WS#acme",因此它们构成一个单一的项集合,
一起住在同一个分区上。
Detail 排序键把它们区分开:META 是工作区记录,每个项目带一个 PROJ# 前缀,配上
零填充、按时间排序的 id,使项目自然有序。
直观地看,父项及其子项在一个分区内堆叠起来,按排序键排序:
对 EntityRef = "WS#acme" 的一次 Query 在单次读取中扫遍整个堆栈——父项加上每个子项。
现在这三种访问模式各自都坍缩成一次调用:
- 工作区设置 ——
GetItem(EntityRef="WS#acme", Detail="META")。 - 列出项目,最新优先 ——
Query(EntityRef="WS#acme")配上Detail begins_with "PROJ#",以降序运行(ScanIndexForward = false)。 - 单个项目 ——
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042")。
第二种才是关键所在:父项加上任意数量的子项在一次计费的 Query 中返回,没有连接,
也没有第二次往返。这正是用外键属性加 Scan 做不到的动作。
手写那个 begins_with 条件很繁琐——键条件和投影表达式的语法会咬人。
DynamoDB Expression Builder 会生成
KeyConditionExpression、#name/:value 占位符映射,以及一段可直接运行的 SDK 代码片段,
让你不必跟语法较劲:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }在 DynoTable 中查看项集合
这种布局的好处是可视化的:每一行共享同一个 EntityRef,就是工作区加上它的子项,彼此相邻而坐。
DynoTable 会把它们分组,让你把一对多关系看作一个连续的整块,而不必跨越多张表去猜测。


陷阱与替代形态
有几点要留意:
- 热分区。 一个工作区的每个项都住在一个分区上,所以单个非常大或非常繁忙的租户会把
流量集中起来。AWS 描述的自适应容量
行为能吸收中等程度的倾斜,但一个有数百万个项目的工作区可能需要分片键
(例如
WS#acme#01 … #10)和扇出读取。 - 项集合大小。 在存在本地二级索引时,单个分区的项集合上限为 10 GB;没有 LSI 则没有 这种限制。如果你正在这里权衡索引类型,参见 GSI 与 LSI。
- 优先
Query,绝不用Scan。 整个设计存在的意义就是让你能Query一个分区。退回到 用过滤的Scan去"找某个工作区的项目",等于把模型扔掉,并读取整张表——这正是 Query 与 Scan 里讲到的陷阱。
如果你确实需要跨工作区列出项目(比如全局所有 status = ACTIVE 的项目),基础表回答不了
——它的分区键是按工作区限定的。
那是一个需要二级索引按不同属性对项目重新分区的活儿,而不是去重塑这种关系。
下一步
建模访问模式,把父项编码进子项的分区键,一对多读取就是一次 Query。用
DynamoDB Expression Builder 构建并验证键条件。
然后下载 DynoTable加载这个 schema,实时浏览工作区→项目的项集合,并确认 每个查询恰好只做一次读取。