DynamoDB 中的复合排序键
复合主键是一个分区键加一个排序键。让它强大的诀窍在于你往排序键 里 放什么:把一个层级编码成一个带分隔符的字符串,单次 Query 就能按排序顺序读出整棵子树 —— 没有连接,没有递归,没有第二次往返。
复合排序键在 DynamoDB 中是如何工作的?
复合排序键把一个层级打包进一个带分隔符的字符串 —— root/photos/2026/ —— DynamoDB 按 UTF-8 字节顺序存放它。由于这个布局本就与树相符,单次配合 begins_with(SK, "root/photos/") 的 Query 就能按路径顺序读出整棵子树。没有连接,没有递归,没有第二次往返 —— 只是对一段连续切片的前缀扫描。
- 排序键是一个可排序的字符串,而不只是一个 ID。 把一条路径打包进去 ——
root/photos/2026/—— DynamoDB 就会自动按 UTF-8 字节顺序存放该分区的各项。 - 一个分隔符把前缀匹配变成子树读取。
begins_with(SK, "root/photos/")在一次查询里返回那个文件夹的每一个后代。 - 排序键支持范围条件,而非任意筛选。 你能用
begins_with、between、>、<—— 把键设计成你需要的读取是一个前缀或一个范围,而不是一次Scan。 - 分隔符是承重的。 挑一个不可能出现在路径片段里的,否则两条不相干的分支会撞在一起。
为什么排序键是整盘棋
从 SQL 过来,你会用一个 parent_id 自连接来建模文件夹树,并递归地遍历它 —— 每层一次查询。在 DynamoDB 里,对着一个没有连接的键值存储,那是一个 N+1 暗坑。
DynamoDB 把每一个项存在某个分区键之下、按它的排序键排序,对字符串而言按 UTF-8 字节顺序(AWS:Query 键条件)。所以如果你的排序键 就是 路径,物理布局就已经与树相符了。一次读取变成对一段连续切片的前缀扫描 —— 而非一次图遍历。
转变就在这里:排序键不是一个你要精确匹配的标识符。它是一个可排序的地址。把它设计好,查询就免费地浮现出来了。
给文件系统树建模
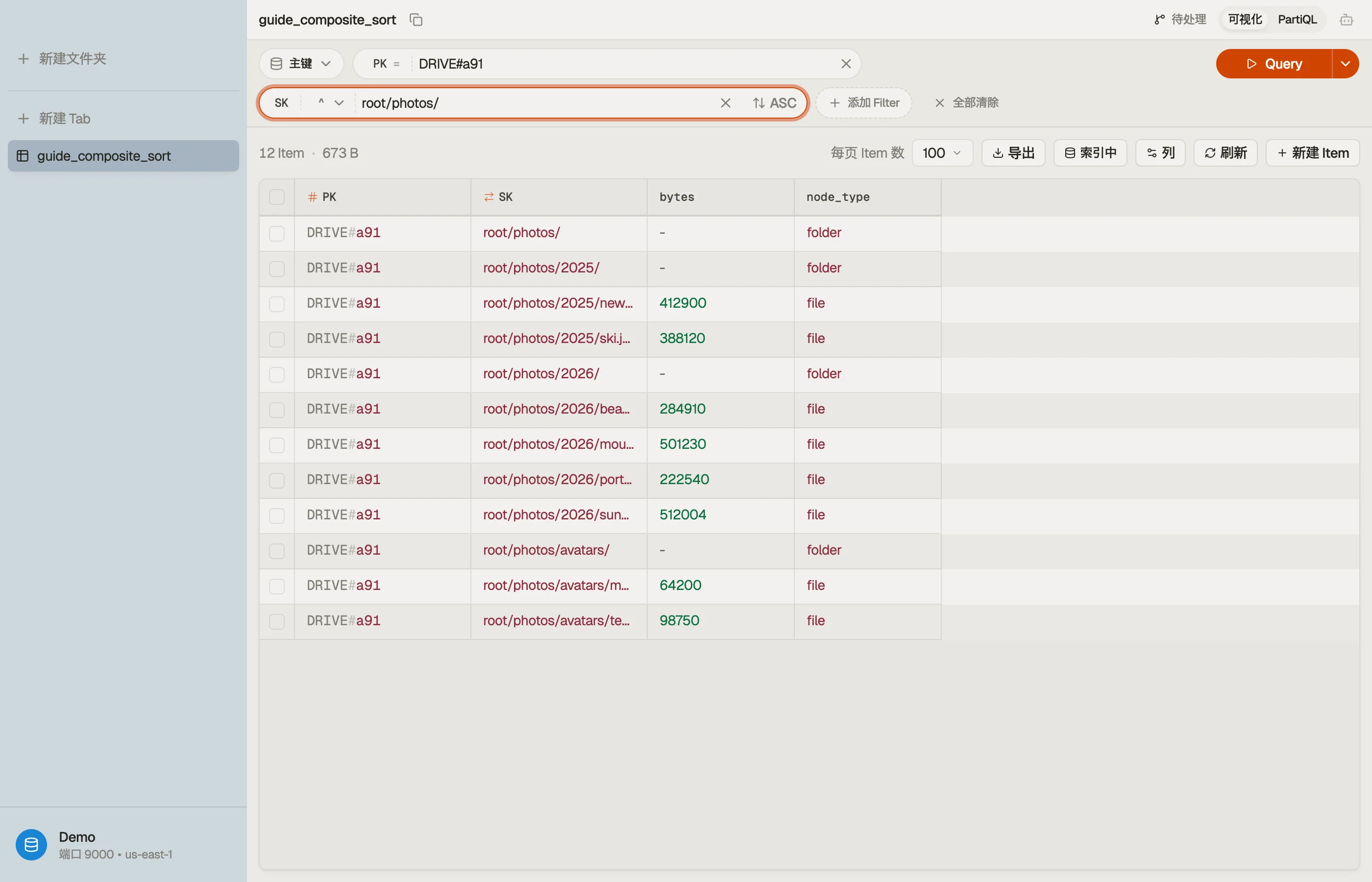
假设你在存储按账户划分的文件树。每个账户一个盘是天然的分区;盘里面的路径是排序键。
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
这里有两个原创约定在干活:
PK = DRIVE#<account>把一个账户的整棵树保持在单一项集合里,于是任何子树读取都是一次单分区Query。SK是完整路径,文件夹带一个末尾/。那个末尾斜杠是刻意的 —— 它让一个文件夹排在它自己的子项 之前,并让root/photos/与一个名为root/photos的同级文件区分开。
一次查询读出一棵子树
列出 root/photos/ 之下的所有东西 —— 文件夹、子文件夹和文件,递归地:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"那会返回 root/photos/、root/photos/2026/、beach.jpg 和 sunset.jpg —— 按路径顺序,在一次计费读取里。你只为那段切片里的项付费,而不是整个盘。
在 DynoTable 中,你直接对路径排序键执行这个 begins_with 查询,文件夹及其后代就会按路径顺序返回 —— 无需手写占位符语法。
需要为自己的代码准备原始的 KeyConditionExpression(名称、值和 begins_with)?在 DynamoDB 表达式构建器里构建并拷贝即可。


只列一层,而非整棵子树
begins_with 给你的是 递归 读取。要做一次非递归的目录列举 —— root/photos/ 的直接子项、不再往深 —— 就存一个深度属性,再加一个排序键范围外加一个筛选,或者把路径拆进一个 parent GSI。最简单的版本:保留一个 parent 属性(root/photos/),并建一个以它为键的 GSI。
要点是:排序键廉价地回答前缀和范围问题。“仅直接子项”是另一个问题 —— 把它显式建模,而不是指望一个 FilterExpression 能让它高效。筛选在读取 之后 运行,而它丢弃的每一个项你都要付费。
谨慎挑选分隔符
分隔符是你数据契约的一部分。两条规则:
- 它绝不能出现在某个路径片段内部。 如果文件名可以包含
/,那么/就是错误的分隔符 —— 一个名为a/b的文件与一个装着b的文件夹a无从分辨。挑一个保留字节(有些团队用#或一个控制字符),并在片段里禁用它。 - 留意边界处的排序顺序。
/(0x2F)排在数字和字母之前,对树的顺序而言这通常正是你想要的。换了分隔符,你就改变了排序 —— 拿真实数据去验证它。
复合排序键 vs. 单独的排序属性
复合排序键(root/photos/2026/x) | 纯 ID 排序键 + parent 属性 | |
|---|---|---|
| 子树读取 | 一次 begins_with 查询 | 递归查询(N+1)或一次 GSI 遍历 |
| 排序 | 路径顺序,免费 | 必须加一个显式的排序属性 |
| 移动 / 重命名 | 重写所有后代 | 更新一个 parent 指针 |
| 直接子项列举 | 需要深度属性或 GSI | 天然(parent = x) |
当读取是子树形且排序重要时,复合键胜出;当树持续变动时,扁平 ID 模型胜出。大多数读取密集型的层级 —— 文件树、分类树、组织架构图 —— 都倾向复合。
暗坑与下一步
- 别把键塞得太满。 你编码进去的一切都是不可变的、且只能按前缀索引。你要按相等性查询的属性应当放在它们自己的字段里或一个 GSI 里,而不是硬塞进排序键。
- 排序键做不了任意
WHERE。 只有begins_with、between和比较。如果你发现自己在伸手去够FilterExpression,那你多半把键建错了 —— 参见 Query 对比 Scan。 - 更深入的键设计在单表设计里;至于何时一次子树读取需要的是索引而非基表,参见 GSI 对比 LSI。
用表达式构建器构建那个 begins_with 键条件,然后下载 DynoTable,对着你自己的表运行这些前缀查询,看一棵子树按路径顺序回来。