DynamoDB 排序键策略
一个 DynamoDB 主键是一个或两个属性:单独一个分区键,或者一个分区键加一个排序键。 分区键决定哪个物理分区持有一个项。
排序键决定那个分区内部各项的顺序——而正是这个排序让 Query 强大起来。
挑错排序键,你照样能写入数据,但你失去了范围读取、排序,以及一个集合里的若干访问模式。
从 SQL 过来,你会在事后动用 ORDER BY 或一个二级索引。在 DynamoDB 里,你提前把顺序烤进键里,
否则就拿不到它。
DynamoDB 排序键是如何工作的?
DynamoDB 排序键对分区内的项进行排序,使 Query 能够执行范围读取——>=、between、begins_with——而不是每次只获取一个项。排序基于编码后键的字节序,因此设计键时(如 ISO-8601 时间戳、零填充数字)需确保字节序与你期望的读取顺序一致。
- 排序键是你的分区内索引。 它在磁盘上给项集合排序,所以
Query能做范围读取 (>=、between、begins_with),而不只是单次GetItem。 - 排序是对编码后键的字节序。 设计键,让字节序等于你想读取的顺序——一个 ISO-8601 时间戳、
一个零填充的数字,绝不是裸 UUID 或
6/23/2026。 - 一个塑造良好的排序键服务多种访问模式。 一个复合键(
EVT#<timestamp>)同时是一个前缀和一个 范围——无需 GSI。 - 方向是免费的。
ScanIndexForward = false以同样的成本最新优先读取;别为了伪造它而存储反转的 时间戳。
为什么排序键是杠杆
没有排序键,一个分区里的每个项只能由它完整的主键来寻址——顶多一次 GetItem。加一个排序键,
DynamoDB 就在分区内按它排序地存储项,这解锁了 Query。
那意味着范围条件(>=、between)、前缀匹配(begins_with),以及一个用来升序或降序读取的
ScanIndexForward 标志。
依据 AWS DynamoDB 开发者指南,共享一个分区键的所有项构成一个项集合,在磁盘上按排序键排序。
所以排序键不只是第二个标识符。它是你在一个分区内查询所针对的索引。
那个排序是对编码后排序键的字节序:字符串按 UTF-8 字节比较,数字按数值比较。这一个事实驱动了下面 几乎每一条策略。
如果你想让范围查询有意义,字节序就必须与你想读取的顺序一致。
策略 1:让排序键可排序
最常见的错误是一个没有有意义排序的排序键。一个随机 UUID 给你唯一性,却给不了有用的范围查询 ——"给我最后 20 条"变得不可能,因为字节序是任意的。
相反,把你要排序和过滤的值编码进排序键,用一种字节序等于其逻辑序的表示。对时间戳来说,那意味着 一种字典可排序的格式:一个 ISO-8601 字符串或一个零填充的纪元值。
ISO-8601 的设计就是让字符串比较等于时间顺序比较——正是范围查询所需要的。避开像 6/23/2026 这样的
格式;月份一翻它们就排错了。
如果你在数字上排序(一个版本计数器、一个分数),用 DynamoDB 原生的 Number 类型,而不是字符串,
这样 42 排在 9 之后而不是之前。
如果一个数字必须住在一个复合字符串排序键里,把它零填充到固定宽度。
策略 2:用复合排序键表达层级
一个排序键可以通过用分隔符(最常见是 #)连接各段来编码层级。一个 begins_with 条件随即就选出
整个子树:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") 只返回六月的事件;更宽的 begins_with(SK, "EVENT#") 返回全部。
各段的顺序是一个设计决定。由粗到细(年 → 月 → 日)让相关项保持连续,使一次范围读取保持为一次便宜的 查询,而不是在分区里四处散落。
策略 3:用 ScanIndexForward 控制方向
DynamoDB 以升序排序键顺序存储项,并默认那样读取它们。要最新优先读取——活动流的自然顺序——在
Query 上设 ScanIndexForward = false。
这是一个读取时的标志,不是一个 schema 决定:同一个集合以同样的成本服务两个方向。别为了得到降序读取 而反转你的时间戳(存一个"反向纪元")。
一个项集合,以升序存储一次,两种方式都能读:
同样的项,同样的分区,同样的成本——只有读取方向不同。
唯一的例外:如果你特别需要降序也正好是一个稀疏索引或分页游标前进的顺序。除此之外,
ScanIndexForward 是更简单的杠杆。
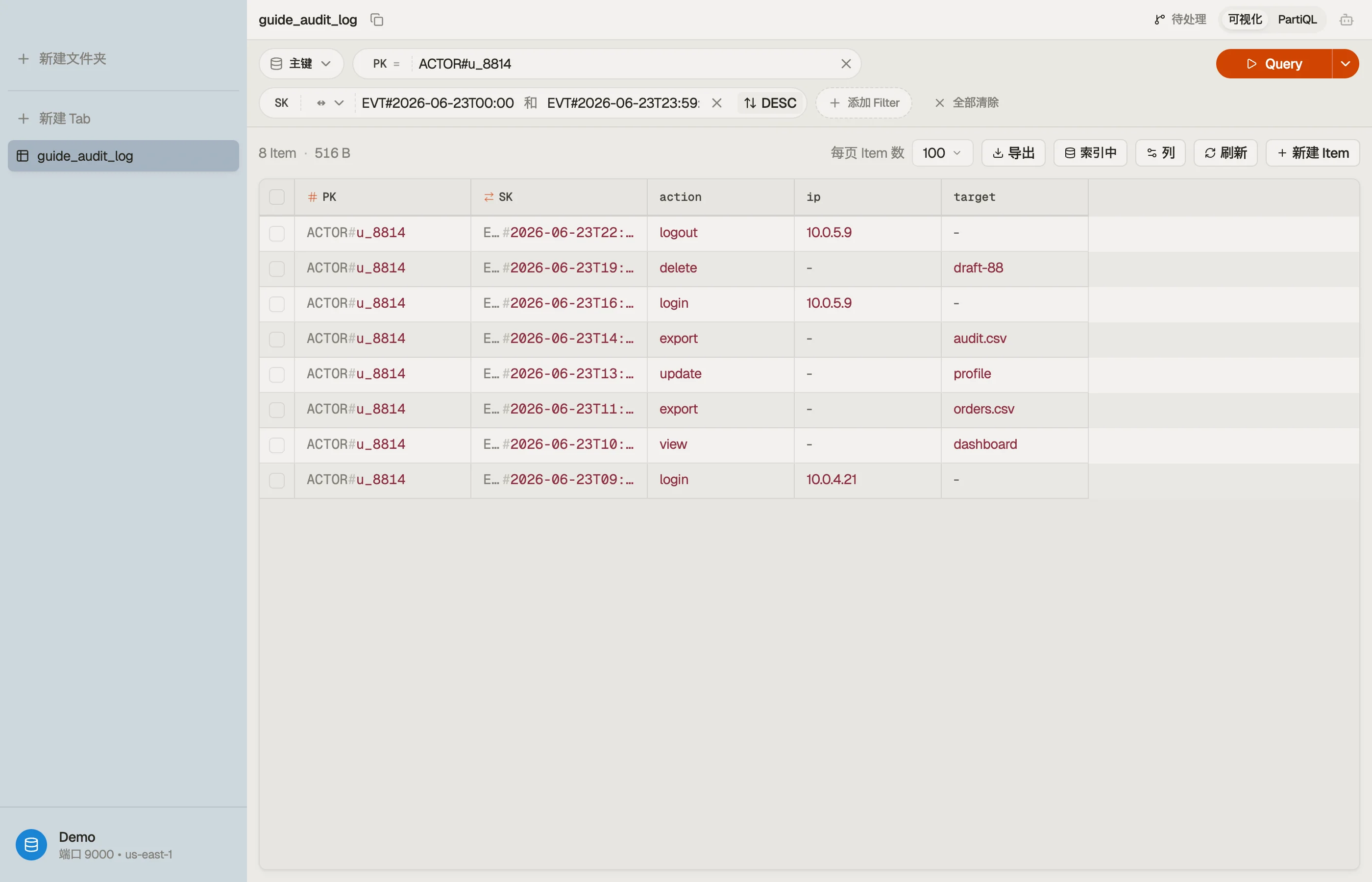
演练实例:一个按行为者限定的审计日志
假设你在一个 SaaS 产品中记录由行为者——用户、服务、API 密钥——产生的带时间戳的事件,并且你有两个读取:
- 某个行为者的活动流,最新事件优先。
- 某个行为者在一个时间窗口内的事件(例如"两次部署之间的所有事情"),用于一次调查。
两个读取都限定在单个行为者上,所以行为者是分区键,事件时间是排序键。用通用的键名,这样同一张表 以后还能容纳其他实体:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
EVT# 前缀加一个 ISO-8601 时间戳给出一个可排序的排序键。读取 1 是
Query PK = "ACTOR#u_8814" 配 ScanIndexForward = false 以最新优先。读取 2 用排序键上的一个
between 条件收窄同一个分区:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"一个集合,两个访问模式,无 GSI——因为排序键既是一个前缀(EVT#)又是一个范围(时间戳)。
降序读取和窗口读取是同样的项、同样的顺序;只是参数不同。
手工构建那个键条件,很容易把 between 的边界弄错,或把属性名上保留字的转义弄错。
DynamoDB Expression Builder 会为一个
begins_with 或 between 排序键条件生成 KeyConditionExpression、ExpressionAttributeNames
和 ExpressionAttributeValues。
把它直接复制到你的 SDK 调用里,而不是在运行时调试转义。
在 DynoTable 中做
设计一个排序键是迭代的:写几个有代表性的项,运行范围查询,检查行是否按你预期的顺序返回。在一个 GUI 里针对一张活的表做这件事,胜过在代码里来回往返。


翻转排序方向、收紧 between 边界,看着返回的集合变化而不写一行代码——这是在你提交一个排序键设计
之前确认它的最快方式。
陷阱与下一步
- 排序键在一个分区内必须唯一。 如果两个事件可能共享一个时间戳,给排序键追加一个消歧符 (一个序号或短 id),让这个复合键保持唯一。
- 一个热分区是排序绕不过去的。 如果一个行为者产生的事件远多于其余,排序键救不了你——你需要一个 分散负载的分区键设计。参见单表设计。
- 第二种排序顺序需要第二个索引。 基础表的排序键给一种排序。要把同样的项以不同方式排序(比如按 事件类型),加一个排序键不同的 GSI——权衡 本地与全局二级索引的取舍。
- 别为了"以后再排序"而动用
Scan。 在Scan之后做客户端排序会读取整张表并把排序扔掉; 那就是 Scan 的坑。把顺序推进排序键里。
一旦键条件对了,试试 DynoTable 来建模集合、并排运行升序和降序查询,在上线之前对照 真实数据验证你的排序键策略。