DynamoDB 中的多对多关系
一个学生选修多门课程;一门课程容纳多名学生。在 SQL 里,你会动用一张连接表和一个四向 JOIN。
DynamoDB 没有连接,所以这种关系必须存在于键之中——窍门是把每条选课边以一种两侧都能
直接 Query 的形态存储起来。
本指南从头到尾走一遍学生 ↔ 课程问题:访问模式、解决它们的邻接表模式、一个你可以照抄的 原创键 schema,以及如何在从不扫描表的前提下双向读回。
如何在 DynamoDB 中建模多对多关系?
DynamoDB 没有连接,所以你要用邻接表模式来建模多对多关系:把每条链接存为以某一侧为键的独立边项,再添加一个调换键顺序的反转 GSI。一条边,写入一次,即可双向廉价地响应查询。
- 把每条选课存为它自己的边项,而不是任一侧的列表属性。
- 以学生为边项设键(
PK = STU#…,SK = ENROLL#CRS#…),这样一次Query就返回一个学生的整份课程列表。 - 加一个反转的 GSI,调换角色(
GSI1PK = CRS#…),让同一条边也回答"谁在这门课里?"。 - 一条边,写入一次,两个方向都读得便宜——这就是全部的游戏。
先框定访问模式
DynamoDB 建模是访问模式优先:你在挑选任何一个属性名之前先确定读取。多对多关系几乎总有 两个对称读取,外加实体查找:
- 获取一个学生的资料,并列出该学生选修的每一门课程。
- 获取一门课程的元数据,并列出选修该课程的每一名学生。
- 查找单条选课边——用于更新成绩或退课。
痛点在于:这两个列表读取指向同一组边的相反方向。一个朴素的设计会便宜地服务其中一个,却
逼迫另一个去 Scan——正是 Query 与 Scan 里讲到的那个坑。
任务是让两个方向都是单次 Query。
使用邻接表模式
DynamoDB 自己对关系的指引就是邻接表:把每段关系建模为一个项,它的分区键是一个端点, 排序键是另一个端点。
AWS 在 DynamoDB 开发者指南的 管理多对多关系的最佳实践 页面记录了这一点。
为什么用键而不是第二张表?因为 DynamoDB 给你的原语就是针对单个分区的 Query。
一个 Query 在一次计费操作中读取单个分区键下排序键值的一个连续范围——这是引擎提供的
唯一一种"连接"。
要得到一种从两侧都读得便宜的关系,你需要复制这条边:以学生设键写一次,然后用二级索引 以课程设键投影同一条边。
这是来自单表设计的重载键思路,只不过应用在一段关系上, 而不是父子层级上。
它的形态是同一条边的两个堆叠视图——基础表以学生设键,反转的 GSI 以课程设键:
每条边在基础表上写一次,并以调换后的键投影进 GSI,于是针对任一分区的 Query
都读得便宜。
它的渊源可追溯到 2007 年的 Amazon Dynamo 论文: 分区键是分布的单位,而单键访问是快速路径。
DynamoDB 中的关系,就是把多对多读取扭进那条快速路径的一项练习。
演练实例:学生 ↔ 课程
用一张表配通用键 PK 和 SK,把实体类型编码进值里。选课边是它的核心:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
单次 Query PK = "STU#a91" 在一次读取中返回该学生的资料以及每一条选课记录。用
SK begins_with "ENROLL#" 收窄它,只取课程边。这就解决了"列出一个学生的课程"。
但"列出一门课程的学生"指向另一个方向——基础表回答不了,因为学生 id 在分区键里, 不在排序键里。
加一个反转的全局二级索引来调换角色。给边项一对通用的 GSI1PK/GSI1SK,让课程在分区侧、
学生在排序侧:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
现在 Query GSI1 WHERE GSI1PK = "CRS#math204" 列出该课程中的每名学生——这正是基础表
服务不了的读取。一条边项,写入一次,两个方向都能回答。
它必须是 GSI,而不是 LSI:课程分区与学生分区完全不同,而 LSI 共享基础表的分区键。
这个索引跨越多个分区,所以它必须是全局的——参见 GSI 与 LSI。
有一个坑:DynamoDB 中的 GSI 是异步填充的。一条全新的选课记录可能要过一会儿才会在
CRS#… 方向出现。
把课程花名册读取当作最终一致——开发者指南对全局二级索引明确指出了这一点。
在 DynoTable 中写入并读取
写入选课意味着设置四个键属性外加边自身的数据。阻止一个学生在同一门课重复选课的条件是对
复合键的 attribute_not_exists(PK) 守卫。
这恰恰是你可以用 DynamoDB Expression Builder
可视化地拼出的那类条件,而不必手写 ExpressionAttributeNames 和占位值。
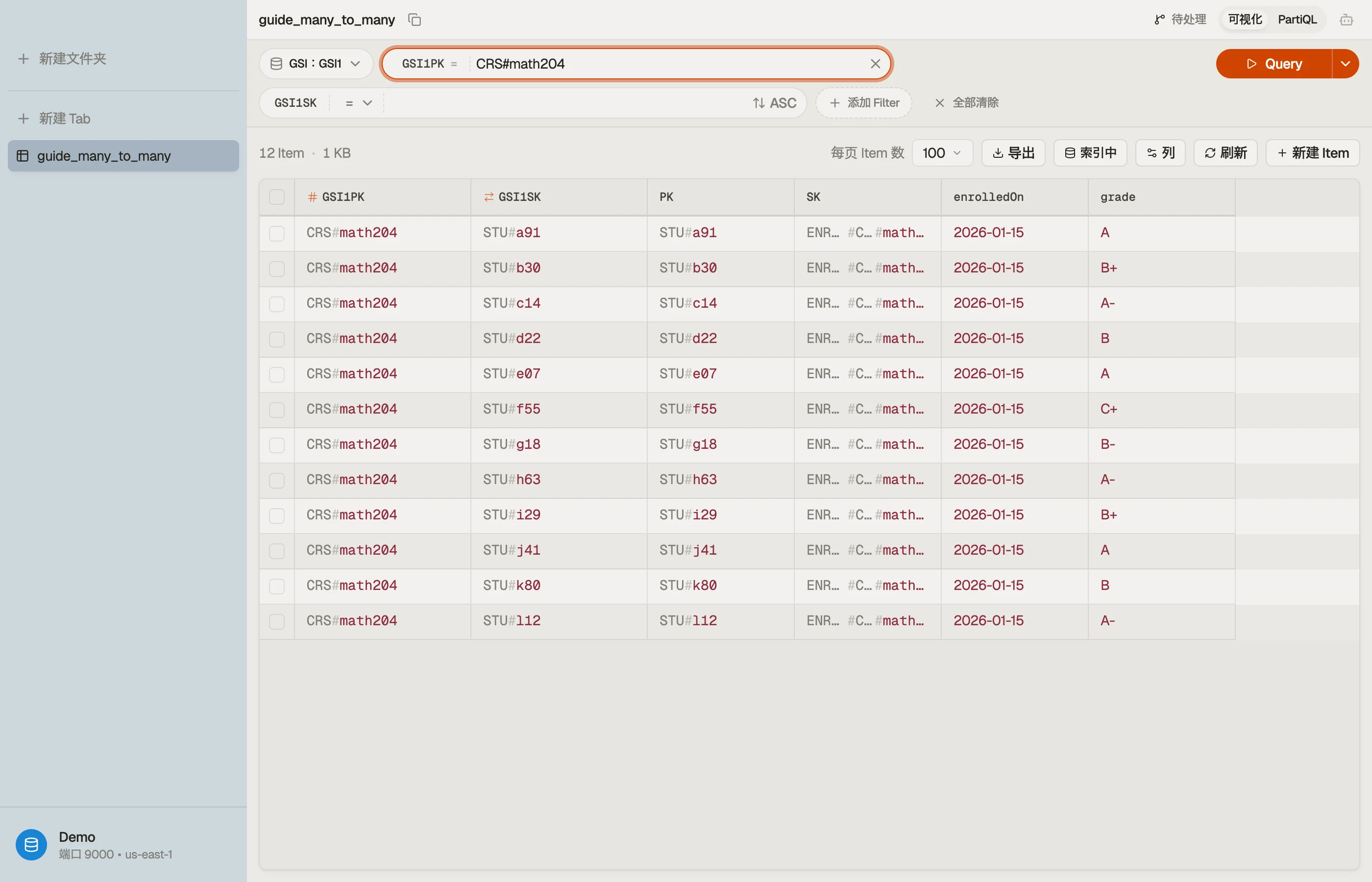
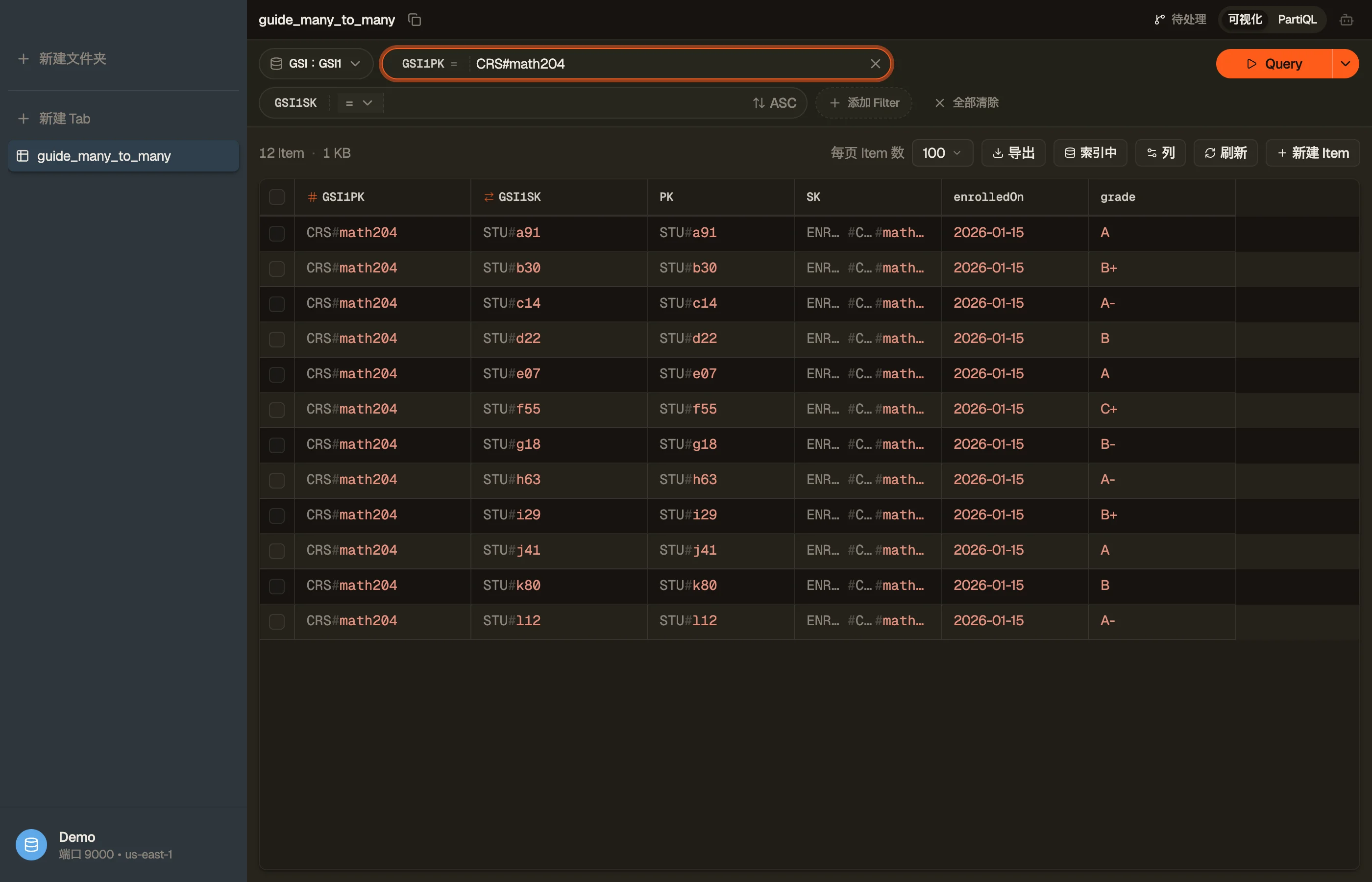
在 DynoTable 中,你把一个 Query 指向 GSI1,设 GSI1PK = "CRS#math204",花名册就以
一张你可以读取、排序、原地编辑的表返回——关系的两个方向都能从一个 schema 浏览。


陷阱与下一步
- 别把一侧存为列表属性。 在学生项上放一个
courseIds数组看着整洁,直到某门课需要它的 花名册、数组撞上 400 KB 的项上限,或者两次选课竞争并互相覆盖。离散的边项独立地扩展和更新。 - 把边数据留在边上。 选课的
grade和enrolledOn属于边项,而不该重复到学生或课程上 ——每一对(学生、课程)恰好只有一行要更新。 - 留意 GSI 传播。 反转索引的方向是最终一致的,所以紧接选课之后的一次读取可能滞后几分之一秒。
- 只投影花名册需要的东西。 当花名册视图只需要 id 时,
KEYS_ONLY或窄投影能让 GSI 保持精简。
要更深入地了解周边模式,读 单表设计了解重载键,读 GSI 与 LSI了解反转索引何时必须是全局的。
然后下载 DynoTable真正建模学生 ↔ 课程的 schema——写入边、用 Expression Builder 构建条件,并在没有一次扫描的情况下查询关系的两个方向。