DynamoDB 稀疏索引
稀疏索引是一个只持有带有其键属性的项的二级索引——于是一张巨表中一小份、火热的子集就成了 它自己的、预先过滤好、随时可查询的集合。
你有数百万行,但你整天都在跑的查询只触及很薄的一片:未关闭的工单、未付的发票、被标记待审的账户。
过滤那一片仍然会扫描整张表,并为每一次读取向你计费。稀疏索引转而让索引本身变小。
DynamoDB 中的稀疏索引是什么?
稀疏索引是一种只持有带有其键属性的项的二级索引。由于 DynamoDB 会跳过缺少该键的项,你只需在想要的项上写入这个键——未关闭的工单、未付的发票——索引便成为那个精确的子集。查询时只读取它,无需过滤,不浪费读取容量。
- 一个二级索引只索引带有它的键的项。 在某个项上省略键,它就永远不会进入索引——没有占位符, 没有空行。
- 所以你发明一个只有想要的项才带的键。 把它写到你要查询的项上,从其余项上移除。索引就变成 恰好是那个子集。
- 查询只读取那个子集,无过滤。 它的大小跟随那个小小的热集,而不是表的总量。
REMOVE才是杠杆,而不是清空。 一个空字符串仍然是一个值,仍然会被索引——你必须删除属性。
问题:过滤并不节省读取
从 SQL 过来,你假设 WHERE 子句会缩小工作量。DynamoDB 的 FilterExpression 不会。它在项被
读取之后才运行,而不是之前。
依据 AWS 开发者指南, 过滤"不会减少所消耗的读取容量"——你为每一个被检查的项付费,然后把不匹配的丢掉。
所以如果你 500 万张工单里有 50 张是未关闭的,一次过滤的 Query/Scan 会读穿数百万张,
才把那 50 张交给你。
这就是每一个"我的扫描为什么这么贵"的帖子背后的坑;Query 与 Scan 有完整的成本图景。
稀疏索引通过让索引本身变小来绕开它。
稀疏性是怎么工作的
一个二级索引只索引实际带有该索引键属性的项。
AWS 关于全局二级索引的文档 说得直白:“全局二级索引只包含那些带有为该索引定义的键属性的项。”
某个项缺了 GSI 的分区键(或排序键),DynamoDB 就根本不把它写入索引。没有占位符,没有空行 ——该项就是缺席。
那种"默认缺席"就是全部窍门。别去索引一个每个项都带的 status 属性。发明一个只有你想查询的项
才会带上的属性。
于是索引就变成恰好是那些项的一份干净列表,针对它的一次 Query 只读取它们——无过滤,无浪费的容量。
想象基础表喂给索引,只有带键的项才会越界过去:
只有带键的(未关闭的)项复制到索引;已关闭的项永远不会进入它。
这与单表设计是同一种塑键心态:键是你为特定访问模式打造的工具, 而不是你数据的忠实镜像。
演练实例:"仅未关闭工单"
拿一张支持工单表。基础表设键是为了按 id 取出某张工单,以及列出某个客户的工单:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
在表的生命周期里,大多数工单最终都会关闭。但你的客服整天敲打的仪表盘查询是"给我看每一张 未关闭工单,最旧优先"——数百行藏在数百万行之中。
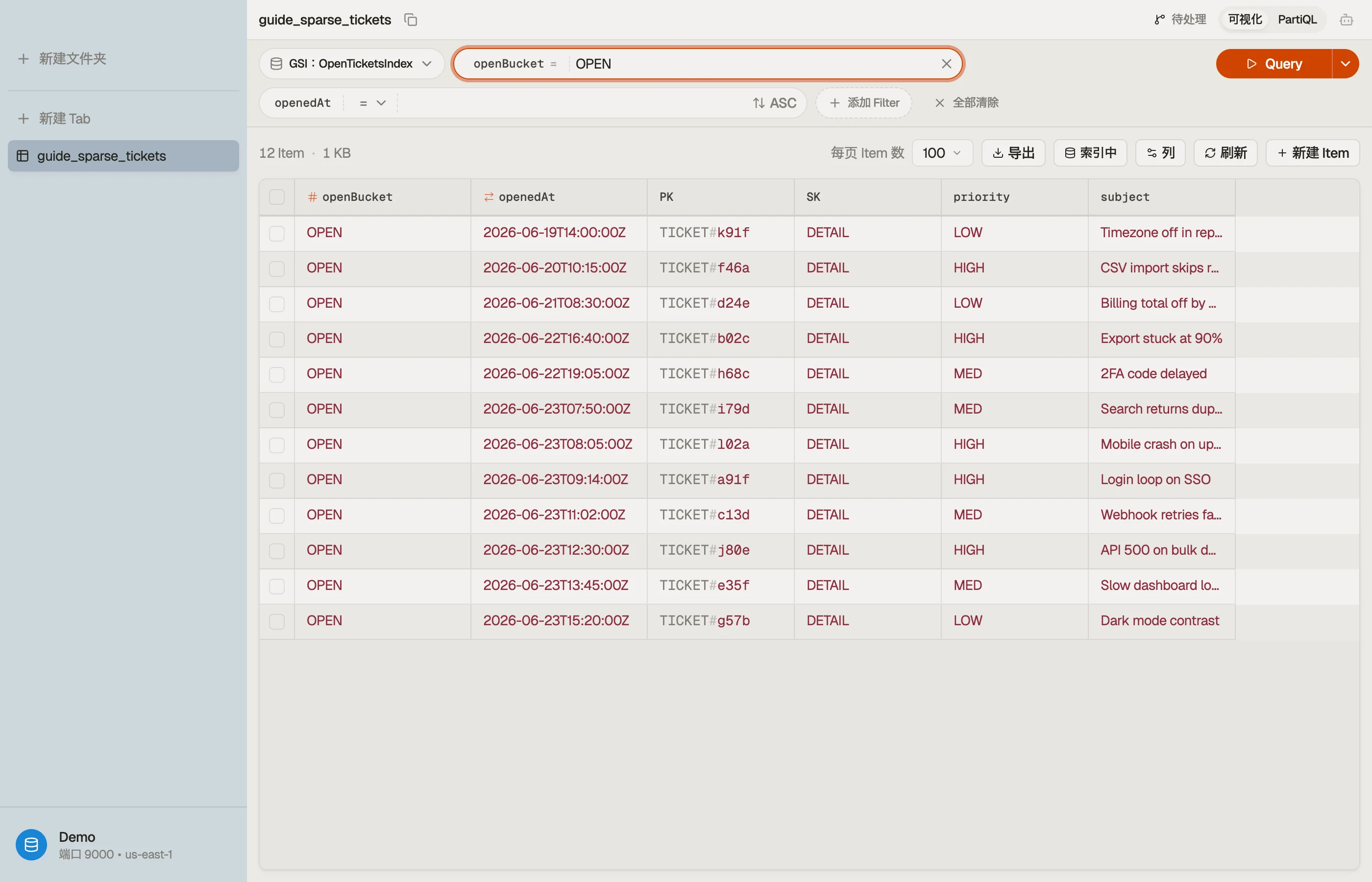
稀疏索引的动作:定义一个分区键为 openBucket、排序键为 openedAt 的 GSI,并只在未关闭工单上
写 openBucket。在工单创建时设置它;在工单解决时 REMOVE 它。
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← open: in the index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← open: in the index |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← closed: NOT in the index |
工单 a91f 和 b02c 带有 openBucket,所以它们住在 GSI 里。工单 77de 已解决并被移除了
openBucket,所以它悄悄地掉了出去。仪表盘现在就是一次便宜的查询:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest first这只读取未关闭工单。随着工单关闭,索引自行缩小——它的大小跟随未关闭的群体,永远不是总量。
一个静态分区值("OPEN")在这里没问题,恰恰因为这个集合保持很小。一个庞大的未关闭集会需要分片
分区键,但"小子集"索引正是单一一个值是正确选择的地方。
让它生效的转变是一条单一的更新表达式——在工单解决时移除该属性。
在 DynamoDB Expression Builder 里原型化那条 REMOVE 子句
以及读取侧的有类型键条件,而不是自己手工拼装 ExpressionAttributeNames 和 :val 占位符。
在 DynoTable 中做
稀疏索引难的不是读取——而是看清哪些项进了索引、哪些悄悄掉了出去。
DynoTable 让你把表视图切换到二级索引,看到恰好是被填充的那个子集。于是你可以确认一张已解决的工单
是真的离开了 open-tickets-index,而不是带着陈旧的键逗留。


陷阱与下一步
有几点要留意:
- 移除键,而不是清空它。 一个空字符串仍然是一个值,DynamoDB 会索引一个
openBucket为""的项。要把一个项从索引中剔除,你必须REMOVE该属性——把它设为一个假值会让它留在里面。 - 索引是最终一致的。 GSI 异步更新,所以一张刚解决的工单可能短暂地仍然出现——GSI 读取 只支持最终一致。 别用它来判断"这张工单现在是否未关闭"。
- 留意被投影的属性。 对索引的一次
Query只返回投影进它的属性。如果仪表盘需要主题和优先级, 就投影它们——否则就为完整的基础项多付一次GetItem。 - 这是 GSI 的长处,不是 LSI 的。 本地二级索引共享基础表的分区键,无法这样有选择地剔除项。 GSI 与 LSI 拆解了这个取舍。
稀疏索引是这个模型里最古老的想法之一。最初的 2007 年 Amazon Dynamo 论文 把这个存储围绕着便宜地服务已知的、高容量的访问模式来构建。
稀疏索引正是如此:塑造键,让常见查询不读取任何它不需要的东西。
要真正构建并查看一个,下载 DynoTable,把它指向你的表,并把数据视图翻到你的稀疏 GSI ——看着子集随着项获得和失去索引键而更新。