DynamoDB 邻接表模式
一张图无非就是节点和边,而邻接表模式把两者都作为普通的项存在一张表里。每条边变成一行,它的分区键是源节点,排序键是目标节点。查询一个分区就列出每一个邻居 —— 这是连接表上 JOIN 在 DynamoDB 里的替身。
什么是 DynamoDB 邻接表模式?
邻接表模式把一张图建模为一张表里的边项:每段关系(A 关注 B)都是一行,源放在分区键、目标放在排序键。查询一个分区就列出每一个邻居,而一个翻转的 GSI 反转这段关系 —— 没有连接,没有扫描,两个方向都在一次查询里完成。
- 边即项。 把每段关系(用户 A 关注用户 B)建模成它自己的项,源放在分区键、目标放在排序键。
- 一个方向免费;另一个需要一个 GSI。 基表回答“A 关注了谁?”。一个翻转的索引回答“谁关注 A?”。
- 没有连接,没有扫描。 两个方向都是对一个已知分区的单次
Query—— 绝非一次全表Scan。 - 它是多对多的原语。 关注、成员关系、点赞、好友关系 —— 任何一个实体连接到许多其他实体的图,都适配这个形态。
把它框定成访问模式
从 SQL 过来,关注图是一张连接表:follows(follower_id, followee_id)。要列出某人的关注者,你索引一列;要列出他们关注了谁,你索引另一列。DynamoDB 没有连接,所以你设计键去直接服务每一次读取。
先把读取写下来。对一个社交关注图:
- 用户 A 关注了谁?(他们的 关注中 列表)
- 谁关注用户 A?(他们的 关注者 列表)
- A 关注 B 吗?(一次单点查找)
键存在的唯一目的就是回答那份清单。把它们设计对,每一次读取就是一次 Query 或 GetItem。
把边建模为项
用通用的键名,好让这张表能容纳不止一种实体类型,并把节点类型编码进值里。一条关注边长这样:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice 是边的源;SK = TARGET#bob 是她关注的对象。一次 Query PK = "ACTOR#alice" 在一次计费读取里返回 Alice 关注的每一个账号 —— 她完整的 关注中 列表,没有连接。
每条边写入一次,方向是“我关注谁”。反方向(“谁关注我”)是基表回答不了的那部分 —— 暂时还回答不了。
用一个 GSI 遍历另一个方向
基表是源优先建键的,所以不扫描就回答不了“谁关注 Bob?”。加一个全局二级索引来翻转键:把目标投影到索引分区键、把源投影到索引排序键。
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
现在 Query GSI1 WHERE GSI1PK = "TARGET#bob" 在一次读取里列出关注 Bob 的每一个人 —— alice 和 dave。同一个边项服务两个方向:基表是 关注中,索引是 关注者。你把每条边写一次,就免费拿到两个查询。
这正是 AWS 在它的 DynamoDB 最佳实践指南里为多对多关系和图数据建模所记录的模式 —— 把边存为项,然后用一个 GSI 反转这段关系。
廉价地检查单条边
“Alice 关注 Bob 吗?”不需要任一份列表。因为这条边建键为 PK = ACTOR#alice、SK = TARGET#bob,它就是一次直接的 GetItem —— DynamoDB 所能提供的最便宜的读取,没有 Query,没有索引。
要幂等地写入这次关注、避免重复计数,给 PutItem 加一个条件,要求这条边尚不存在:
attribute_not_exists(PK)你可以用 DynamoDB 表达式构建器来组装那个条件 —— 以及被 marshalled 的键值 —— 而不必手写 ConditionExpression 和 ExpressionAttributeValues。
在 DynoTable 中实操
当你浏览这张表时,一个 actor 的各条边会堆叠在单个分区键之下、作为一个项集合,而切换到 GSI 视图则显示那份翻转过来的关注者列表 —— 这段关系的两半并排呈现。

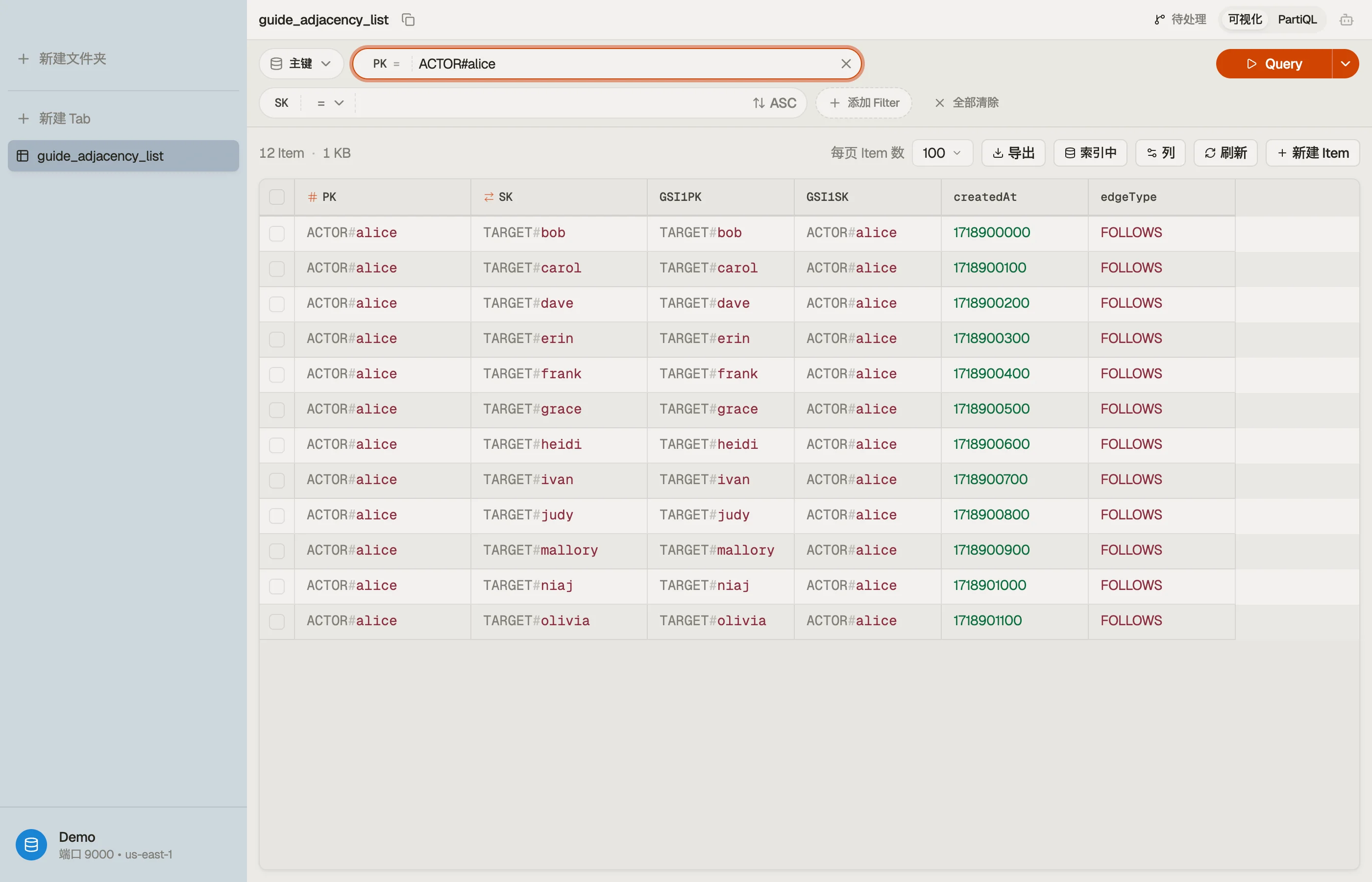

暗坑
明星分区。 一个有数百万关注者的用户,会把每一条关注者边都集中在一个 GSI1PK = TARGET#<star> 分区下。读取那个集合是分页的,而且可能跑得很热。对扇出密集的图,给热键分片(例如 TARGET#bob#0..N),或者反范式化计数,这样你就不必重读整张列表。
把计数存在边上。 一个关注者 数 不是一条边 —— 别靠在每次资料页访问时读取并统计整个分区来推导它。在用户项上维护一个计数器属性,并与边一起事务性地更新它。
忘了这里并不需要反向写入。 一种经典的邻接表变体把边写两次、id 调换。有了翻转键 GSI,你只写一次,让索引去物化反向 —— 更少的写入,两份副本之间没有漂移。
下一步
邻接表是单表设计的关系构件;那个翻转的索引是一个 GSI,而非 LSI,因为分区键变了。而且这里每一次读取都是对一个已知键的 Query 或 GetItem —— 绝非那个 Scan 暗坑。
用 DynamoDB 表达式构建器构建条件和键表达式,然后下载 DynoTable,对着你自己的表给一个关注图建模,看两个方向在一次读取里都解析出来。