DynamoDB 的项大小上限(400 KB)
单个 DynamoDB 项最多能容纳 400 KB 的数据。从 MongoDB(16 MB 文档)或一行没有实际上限的
关系型数据过来,那个天花板会让人觉得低 —— 而你往往是吃了苦头才发现它的:一次跑了好几个月的写入
突然以 ValidationException 失败,只因某个项终于长得太大了。
这个上限不是随意定的,也不是一个你能提升的配额。它是一个建模约束,而撞上它的那些项,通常正在 告诉你数据建模错了。
DynamoDB 中项的最大大小是多少?
DynamoDB 将单个项的上限固定为 400 KB —— 这是一个你无法提升的硬上限。该大小同时计入属性名和属性值,包括每一个嵌套的列表、映射和集合元素。项通常是因无界增长而触及上限的,比如一个不断膨胀的内嵌列表;解法是建模,把集合拆成独立的项,而不是压缩。
- 每项 400 KB,硬上限。 不可调整,也不是软配额。
- 大小 = 属性名 + 值,二者合计。 长属性名也算,在每一个项上都算。
- 嵌套和集合同样计入。 列表、映射及其嵌套值都会累加。
- 常见原因是无界增长 —— 在父项上嵌入一个无限制增长的列表。
- 解法是建模,而非压缩。 把那个不断增长的集合拆成它自己的项,挂在一个共享分区键之下。
问题所在:永远长大的项
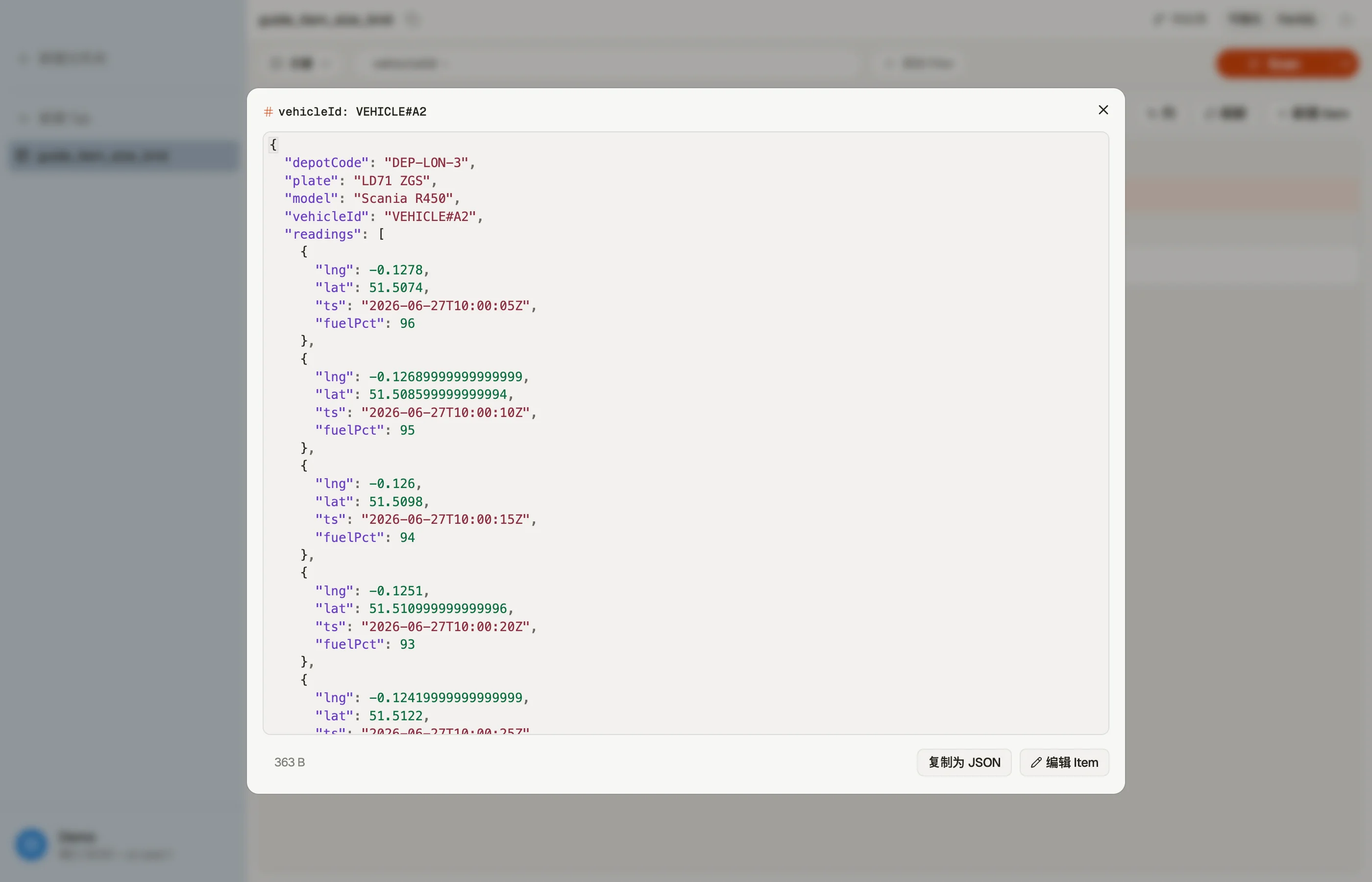
假设你跟踪一支车队,并决定把每辆车的遥测读数作为一个列表存在车辆项上:
PK: VEHICLE#A1 readings: [ {ts, lat, lng, fuel}, {ts, lat, lng, fuel}, ... ]头一两天没问题。但读数每隔几秒就到达,且永不停歇,于是列表无界地增长。最终某个车辆项跨过了 400 KB,对它的每一次写入都失败 —— 你再也无法为那辆车记录遥测了,因为每次更新都要重写整个 (如今已超大的)项。
bug 不是那个大小上限。是把一个无界的一对多关系建模成了内嵌列表。那只有在「多」的一侧有界 且很小时才行得通。
究竟什么计入 400 KB
DynamoDB 把项的总大小衡量为以下各项之和:
- 每一个属性名,按 UTF-8 编码。一个 20 字符的名字重复出现在数百万个项上,既是大小、也是你 要为之付费的存储 —— 这正是经验丰富的建模者把属性名保持简短的原因。
- 每一个属性值。 字符串和二进制按其字节长度计;数字按一种紧凑编码计;布尔值和空值按一份很小 的固定成本计。
- 嵌套结构。 一个列表或映射既计入它自身的开销,又计入其内部每个元素和键的大小,一直递归 到底。
没有单独的每属性上限要去规划 —— 是整个项对着那条 400 KB 的线。 AWS 服务配额 详细说明了确切的字节计算方式。
这个上限为何存在
大项搬动起来昂贵。DynamoDB 的读取以 4 KB 为单位计量,所以一个 400 KB 的项强一致读取要花 100 RCU —— 而随着项变大,读取、写入和复制都会变得更慢、更贵。这个上限 推动你 走向小而精准的项,远离 NoSQL 新手出于关系型习惯而抓取的那种「一次取回一个巨大数据块」的反模式。
围绕它来建模
对于车队这个例子,别再内嵌了。给每个读数它自己的项,放在与车辆相同的分区里,按排序键上的 时间戳排序:
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:05Z lat, lng, fuel
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:10Z lat, lng, fuel现在没有单个项会增长,写入永远不会撑破上限,而一次对 VEHICLE#A1 的 Query 仍然能把一辆车的
读数作为一个排好序的项集合拉回来。有界的子列表(少量标签、
一个固定的配置块)内嵌是可以的;无界的则要变成项。
在 DynoTable 中检查项大小
在你定下一种形态之前,先掂量一个有代表性的项。在 DynoTable 中,用 Quick View 打开一个项, 它会在属性旁边显示该项的字节大小 —— 这样你就能在浏览真实数据时,于设计阶段逮住过重的形态, 而不是在写入失败时。
更喜欢在浏览器中操作?DynamoDB 项大小计算器 从粘贴的样本中完成同样的事情,报出确切的 KB 数以及每次读取和写入将花费的 RCU/WCU。


坑与后续步骤
- 盯住随流量增长的内嵌列表 —— 它们是经典的 400 KB 定时炸弹。给它们设界或把它们拆出来。
- 缩短属性名 —— 在高基数的项上,这是白捡回来的大小和存储。
- 大值该放进 S3。 把大数据块(图片、文档)存进 S3,只在项上保留键。
- 相关:反规范化和 一对多关系讲了何时该内嵌、何时该拆分。
想一眼看遍一张表里真实的项大小? 下载 DynoTable,直接检视你的数据。