DynamoDB 索引投影:KEYS_ONLY、INCLUDE 与 ALL
当你创建一个二级索引时,DynamoDB 不会自动把整个项复制进去。你来选择什么被复制进去——索引的投影。选得太少,你的查询就要付一次额外读取去取回其余部分;什么都选,你就要在每次更新时付出额外的存储和写入成本。这是一个你在索引创建时设定一次、然后就要一直承受的取舍。
(别把这个和投影表达式混淆,后者裁剪的是单次读取所返回的属性。本页讲的是一个索引物理上存储什么——另一个请参见投影表达式。)
什么是 DynamoDB 索引投影?
投影是指 DynamoDB 从基础表复制到二级索引中的那一组属性。你要从三种类型中选择一种:KEYS_ONLY(只有键)、INCLUDE(键再加上一个命名的属性列表)或 ALL(整个项)。投影越多,回基础表取数的次数就越少,但存储和写入成本也越高。
- 一个投影是被复制进一个二级索引的那一组属性。
KEYS_ONLY——只有表键和索引键。最小、最便宜。INCLUDE——这些键再加上一个你选定的额外属性命名列表。ALL——项的每一个属性。最大;查询永远不需要回到基础表。- 读取一个未被投影的属性会强制对一个 GSI 从基础表取数——一项隐性的额外成本。(一个 LSI 可以替你取回未被投影的属性,代价是额外的读取成本。)
- 投影越多 = 存储越多 + 写入成本越高,因为每一次基础表写入都会传播到索引。
问题:那个让你读两遍的索引
假设你运营一个支持工单台,有一个 GSI 让你按优先级列出未关闭的工单。你投影 KEYS_ONLY 以保持精简。查询返回得很快——但它只给你工单 ID,而你的队列界面需要每个工单的主题、负责人和时长。
于是现在你的代码要对基础表做第二轮读取,去为每一条结果补全数据。你设计的那"一次查询"实际上是一次查询外加 N 次取数,你本想省下的延迟和成本又原样回来了。这个投影对该访问模式来说太单薄了。
每种投影类型复制什么
KEYS_ONLY只存储基础表键和索引键。当查询只需要知道哪些项匹配、而你会在别处取明细——或者根本不取——时使用它。INCLUDE存储这些键再加上一个你命名的固定属性列表。最佳平衡点:恰好投影你的查询渲染所需的字段,别的一概不要。ALL复制整个项。查询完全由索引自给自足,代价是把整个项的存储和写入吞吐都复制进它里面。
对于这个支持工单队列,带 subject、assignee 和 age 的 INCLUDE 是正确的选择——队列单凭索引就能渲染,无需第二次取数,也不必把工单庞大的 body 复制进索引。
你在用什么做交换
你投影的每一个属性都会被存储第二遍,并且每当基础项变更时在索引里重写一遍。所以在一张频繁更新的表上一个大手大脚的 ALL 投影会同时成倍放大存储和写入容量。要守的纪律是:投影查询所读取的,而不是"一切,以防万一"。
一个值得知道的细微之处:在一个稀疏索引上,投影仍然只持有那些携带索引键的项——所以在一个稀疏索引上用 INCLUDE/ALL 仍然很小,因为索引本身就很小。用 DynamoDB 定价计算器权衡你这个投影的存储与写入乘数,并用 DynamoDB Expression Builder 把索引查询本身组装起来。
在 DynoTable 中看一个投影
DynoTable 列出一张表的每个二级索引,并让你直接通过其中之一查询。对基础表和对一个 GSI 跑同一个访问模式并比较结果——索引结果中缺失的那些属性,正是它没有投影的那些,所以一个投影的效果无需重新阅读表定义就清晰可见。

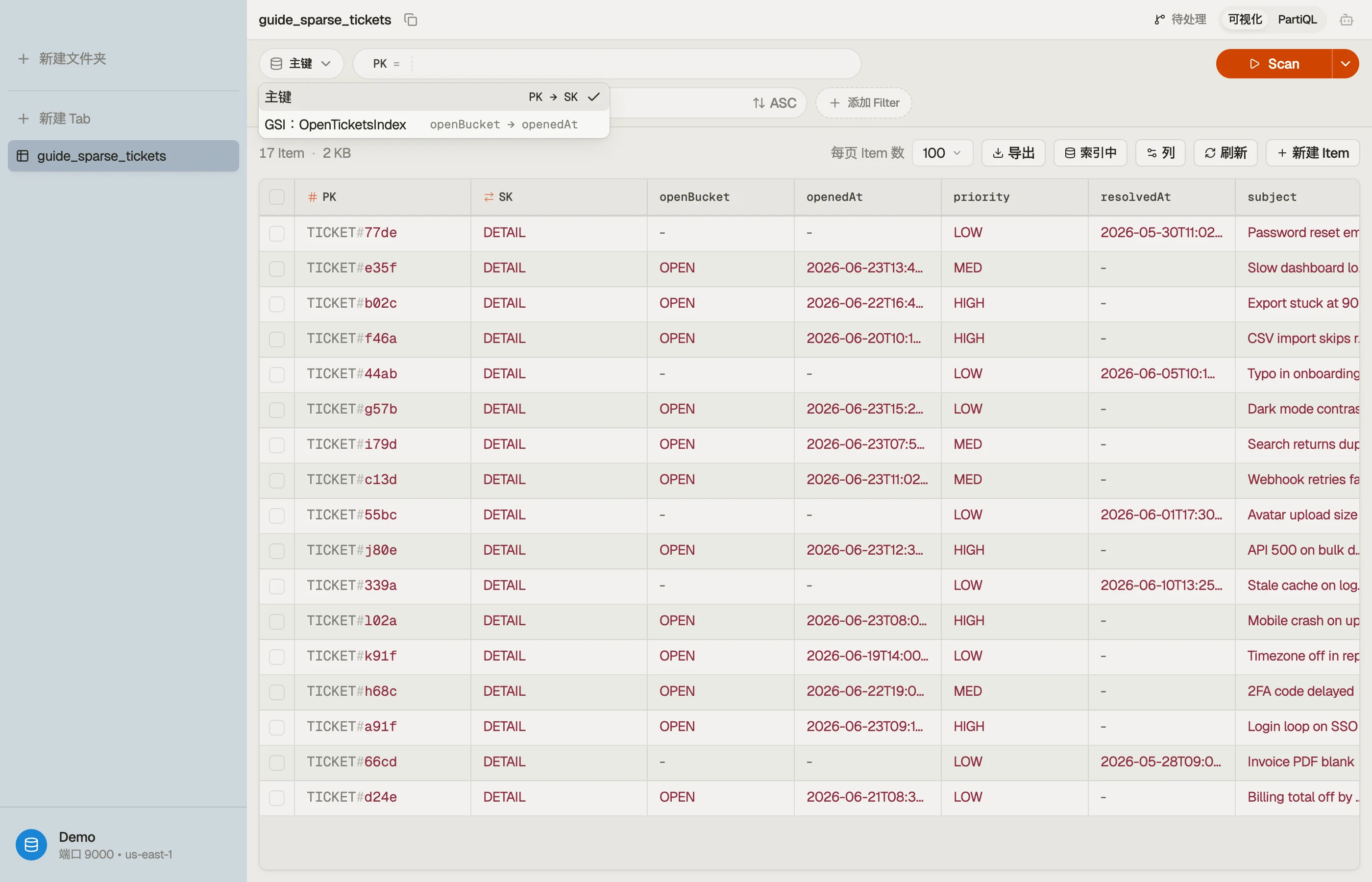

陷阱与下一步
- 一个未被投影的属性在 GSI 上意味着一次基础表取数——围绕查询渲染什么来设计投影。
ALL很少是免费的——它会复制存储和写入成本;默认用INCLUDE,除非索引确实需要每一个字段。- 投影大体上是固定的。 你以后无法在不重建索引的情况下自由编辑一个 GSI 的投影——一开始就要审慎选择。
- 相关:GSI 与 LSI和稀疏索引塑造了一个投影实际存储多少。
想在重新设计你的索引之前看看它们实际返回什么?下载 DynoTable 直接查询你的表。