DynamoDB 中的补零排序键
一个 DynamoDB 字符串排序键按字典序排序 —— 从左到右,一个字符一个字符 —— 而非按数值。所以 "10" 落在 "2" 之前,因为 "1" 排在 "2" 之前。补零到一个定宽,就是你让字符串顺序与数值顺序相符的办法。
为什么 DynamoDB 排序键里 "10" 排在 "2" 之前?
因为 DynamoDB 字符串排序键按 UTF-8 字节顺序进行字典序比较,而非数值比较。"1" 的字节值小于 "2",所以 "10" 排在 "2" 之前。将每个数字用前导零补到定宽 —— "2" 变为 "0000000002" —— 字符串顺序就与数值顺序完全一致了。
- 陷阱: 存成字符串的数字像单词一样排序。
"100"、"11"、"2"就是 DynamoDB 给你的顺序 —— 而非你想要的。 - 修复: 用前导零把每个数字补到一个定宽,于是
"2"变成"0000000002"。现在字典序和数值序一致了。 - 一次选定宽度: 按你将来会存的最大值来定它,然后再多加几位。日后改宽度意味着重写每一个键。
- 降序免费: 要从高到低排序(排行榜那种情形),就存
maxValue - value,同样补零 —— DynamoDB 没有按属性的排序方向。
为什么字符串排序键会背叛你
从 SQL 过来,一个整数列上的 ORDER BY score DESC “直接就好用” —— 引擎知道那一列是数值的。对一个不是 Number 类型的排序键,DynamoDB 没有这种奢侈。
DynamoDB 按 UTF-8 字节顺序比较字符串(S)排序键,依据 AWS 排序键文档。是字节,不是大小。"9"(0x39)压过 "10",因为它的首字节胜过 "1"(0x31)。长度无关紧要 —— 只有第一个不同的字节说了算。
那就是暗坑:一个数字一住进字符串排序键,每一次遍历范围的 Query 都会以一个看起来乱套的顺序返回行。
构建一个排行榜排序键
拿一个赛季制街机排行榜。每个赛季一个项集合,容纳每位玩家的成绩,而你想要最高分在前。
用一个复合键在单一项集合里给它建模:
leaderboardId(分区键)—— 例如SEASON#2026-SPRING。rankKey(排序键)—— 补零的分数加一个决胜局。
一个朴素的初次尝试把原始分数存成字符串:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "9" | quickdraw |
| SEASON#2026-SPRING | "10" | ace_pilot |
| SEASON#2026-SPRING | "1500" | nightowl |
| SEASON#2026-SPRING | "240" | bytecrash |
对 SEASON#2026-SPRING 的一次 Query 以这个字节顺序返回它们:"10"、"1500"、"240"、"9"。那次 9 分的成绩垫了底,而 1500 分的成绩埋在中间。对排行榜毫无用处。
补到一个定宽
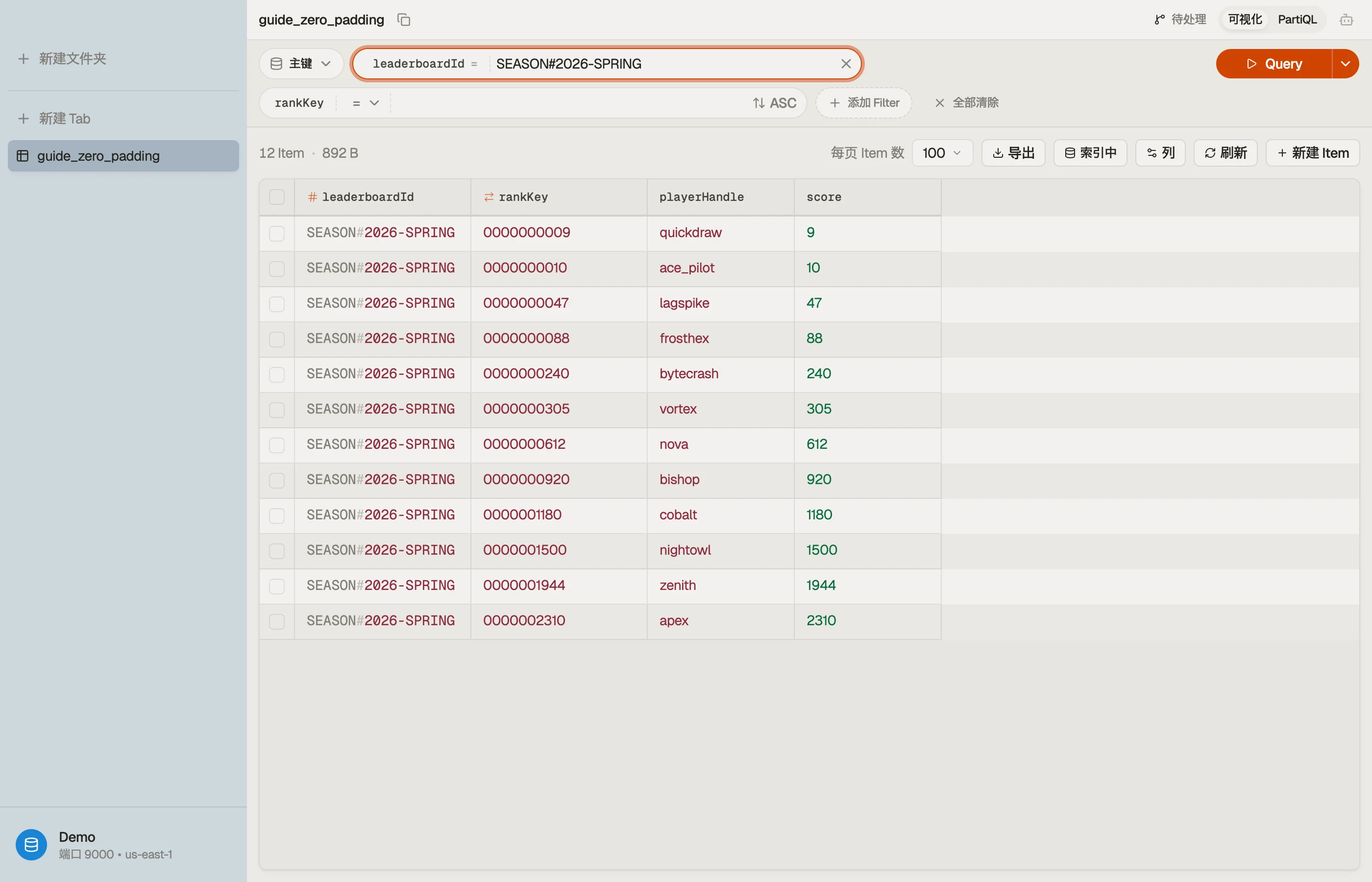
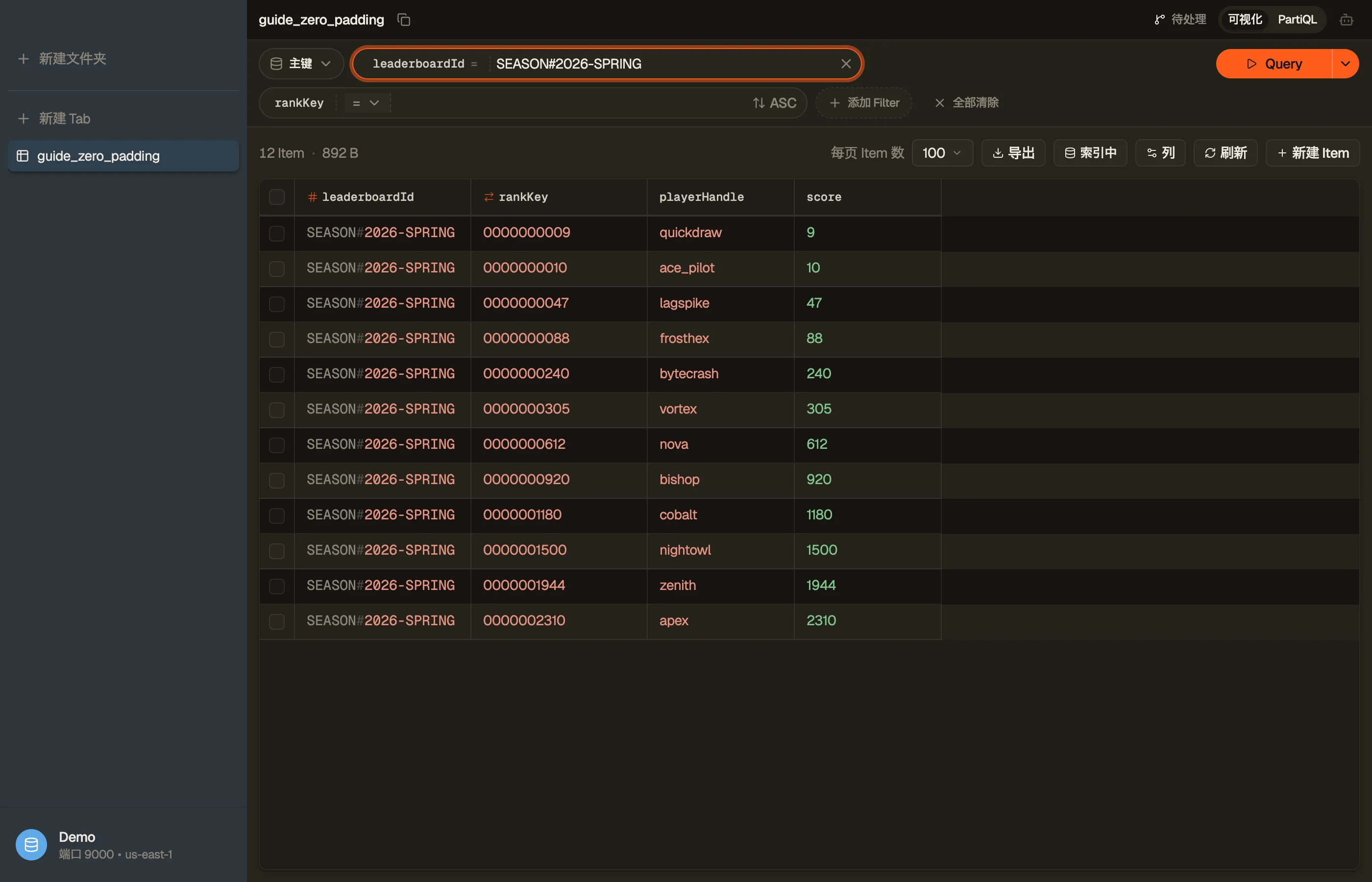
挑一个宽到足以容纳你将来会记录的最大分数的宽度,然后用零左补。假设分数封顶在一千万 —— 那是八位,所以用十位留出余量:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "0000000009" | quickdraw |
| SEASON#2026-SPRING | "0000000010" | ace_pilot |
| SEASON#2026-SPRING | "0000000240" | bytecrash |
| SEASON#2026-SPRING | "0000001500" | nightowl |
现在每一个键都是同样的长度,所以逐字节比较和数值比较产生相同的顺序。升序 Query 给出 9, 10, 240, 1500。数学终于和字节相符了。
宽度是一道单向门。如果你补到十位、而某个分数后来超过了那个,那么一个 11 位的值会排在一个 10 位的 之前 —— 把一切重新弄坏 —— 而修它意味着重写每一个现存的 rankKey。把宽度超额预留;代价是寥寥几个字节。
降序排序:存差值
排行榜想要最高分在前。DynamoDB 能用 ScanIndexForward: false 正向或反向读取一个排序键,所以降序通常是一个读取时的标志 —— 先够这个。
但当一个项集合必须服务混合的排序方向时,或者你想让最高分物理上在前、无论读取标志如何,就把数字本身翻转。存 maxValue - score,补零到同样的宽度:
score inverted (9999999999 - score) rankKey
1500 9999998499 "9999998499"
240 9999999759 "9999999759"
10 9999999989 "9999999989"
9 9999999990 "9999999990"对翻转后的值的升序字节顺序,现在产出原始分数的从高到低:1500, 240, 10, 9。这个诀窍秉承了 2007 年 Amazon Dynamo 论文的精神 —— 键是不透明的字节,所以你把意图编码 进 那些字节里。
加一个决胜局
两个玩家可能打平。一个光秃秃的补零分数会在排序键上相撞,而第二次写入会覆盖第一次(相同的 PK + SK)。追加一个唯一后缀,让每次成绩都是一个不同的项,且平局可以确定地裁决:
rankKey = "<paddedScore>#<paddedTimestamp>#<playerId>"例如 "0000001500#0000001719100800#p_8842"。同样的分数,更早的时间戳赢得更高的位次 —— 把时间戳也补零,否则它会重新引入你刚刚修掉的那个一模一样的 bug。
在 DynoTable 中,你可以浏览按补零的 rankKey 排序的赛季排行榜,亲眼看到补零后的值将各行正确对齐——这是在发布之前确认宽度无误的有力证明。
手工组装那个复合键时,很容易把一个宽度敲错。在表达式构建器里为一次”赛季顶端”的 Query 生成 KeyConditionExpression,能在你拿宽度做实验时让 begins_with / between 语法保持诚实。


要避开的暗坑
- 补得太窄。 整套方案在某个值第一次溢出宽度时就垮掉。按最坏情况来定大小,然后再加几位。
- 忘了读取标志。 如果你只会降序读取,
ScanIndexForward: false也许就是你所需的全部 —— 当一个标志就能搞定时别去够翻转键。 - 一个集合里混用宽度。 共享一个排序范围的每一个键都必须用同样的宽度。一次只给新行补零、不给旧行补零的迁移,会把它们错误地交错起来。
- 补错了片段。 在一个复合键里,给参与排序的 每一个 数字片段补零 —— 分数和时间戳都要,而不只是分数。
下一步
补零是更广的排序键设计工具箱里的一件工具;当你重载一个键去服务好几种模式时,把它与项集合配对,并在排序对了之后,倚靠一次精确的 Query 而非一次 Scan。
试用 DynoTable,去浏览一张真实的表,在你上线模式之前看你的补零排序键落入数值顺序。