DynamoDB 引用计数
引用计数 是你存在父 item 上的一个数字,记录有多少子 item 指向它——一篇帖子的点赞、 一个 workspace 的成员、一条 comment 的回复。你之所以保留它,是因为每次读取都去数一遍 子项太贵了。
如何在 DynamoDB 中维护一个计数?
将运行中的总数作为数字存在父 item 上,并在创建子项的同一次写入中更新它。一个 保证两者要么都落地、要么都不落,而子项写入上的条件表达式能阻止重试导致的重复计数——这样一次 GetItem 就能返回准确的计数。
- 别在读取时去数子项。 一次
Query去数点赞,会为它扫到的每个点赞 item 付钱。把 总数存在帖子上,改为读一个 item。 - 在写入子项的地方维护计数,而不是写完之后。在创建子项的同一次操作里把它加上,这样 两者永远不会漂移。
- 当写入和递增触及不同 item 时,用事务。 一个点赞是一个 item,计数住在另一个上——
TransactWriteItems让两者要么都落地、要么都不落。 - 自坑是重复计数。 一个被重试或重复的点赞重新跑了递增,就把数字撑大了。用一个 condition 给子项写入加护栏。
为什么要计数
从 SQL 过来,你绝不会去存一个点赞数——你会
SELECT COUNT(*) FROM likes WHERE post_id = ? 并让索引把它变便宜。DynamoDB 没有可以
跳过读取 item 的 COUNT(*)。
一次对帖子点赞的 Query 会读取——并计费——那个分区里的每一个点赞 item,哪怕你只想要那个
数字。在一篇爆款帖上,回答"有多少点赞?"要花掉数千个 RCU。这就是引用计数存在要消灭的那个
读取自坑。
所以你 反规范化:把运行中的总数存在帖子本身上。读取计数就变成一次 GetItem。代价是
你现在要自己负责保持它准确。
给 item 建模
两种 item 类型共享一个分区,让帖子和它的点赞坐在同一个 item 集合里。杜撰的 key:
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
META item 上的 likeTally 属性就是引用计数。每个 LIKE# item 是一个子项。把两者都
放在 PK = "POST#a91f" 下,意味着当你确实想要那个列表时,一次 Query 就能把帖子和它的
点赞者一起取出来。
原子地递增计数
DynamoDB 用一个 ADD(或 SET x = x + :n)update 表达式来递增一个数字——这是一个
原子计数器:DynamoDB 在服务端施加这个增量,你不用先读当前值,所以并发的递增不会互相
覆盖。
(AWS:原子计数器)
问题在于:给帖子点赞是对 两个 item 的 两次 写入——创建 LIKE# item,并给 META
上的 likeTally 加 1。如果点赞落地了但递增失败了,这个合计就永远错了。你需要两者皆有
或两者皆无。
这正是 TransactWriteItems 所保证的——跨多个 item 全有或全无,并且只要任一 item 被并发
修改,它就取消整个事务
(AWS:用事务做悲观锁):
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Put 和 Update 一起提交。如果任一失败,DynamoDB 把两者都回滚,并返回一个
TransactionCanceledException。
防范重复计数
真正的 bug 不是一个写了一半的点赞——事务把那个挡住了。它是 同一个用户点了两次,或者
一次客户端重试重放了请求。每次重放都再加一个 1,likeTally 就悄悄漂移到真实计数之上。
Put 上的 ConditionExpression: attribute_not_exists(SK) 就是那道护栏。如果那个用户的
LIKE# item 已经存在,Put 的 condition 就失败,整个事务被取消,而且——关键地——那个
ADD 从不运行。每个用户一个点赞,由 key 强制执行。
在
DynamoDB 表达式构建器里构建并复制这些 update 和
condition 表达式——带上正确的 ExpressionAttributeValues 和 attribute_not_exists
护栏——而不是手工拼那段 JSON。
取消点赞,以及它的成本
移除一个点赞是镜像操作:Delete 那个 LIKE# item,带
ConditionExpression: attribute_exists(SK),并在同一个事务里 ADD likeTally :minusOne。
这个 condition 阻止一次双重取消点赞把合计压到负数。
要清楚价格。一次事务性写入对最多 1 KB 的 item 花 每个 item 2 个 WCU——一个用于准备, 一个用于提交——相比之下一次普通写入是 1 WCU。一个点赞是两个 item,所以每个点赞大约是四个 WCU。每个动作很便宜,但在一篇名人帖招来点赞风暴之前值得知道。
在 DynoTable 里看它
当你怀疑一个合计漂移了,你想把存着的 likeTally 和实际的 LIKE# 子项数量比一比——而不用
在生产环境跑一个计数 query。

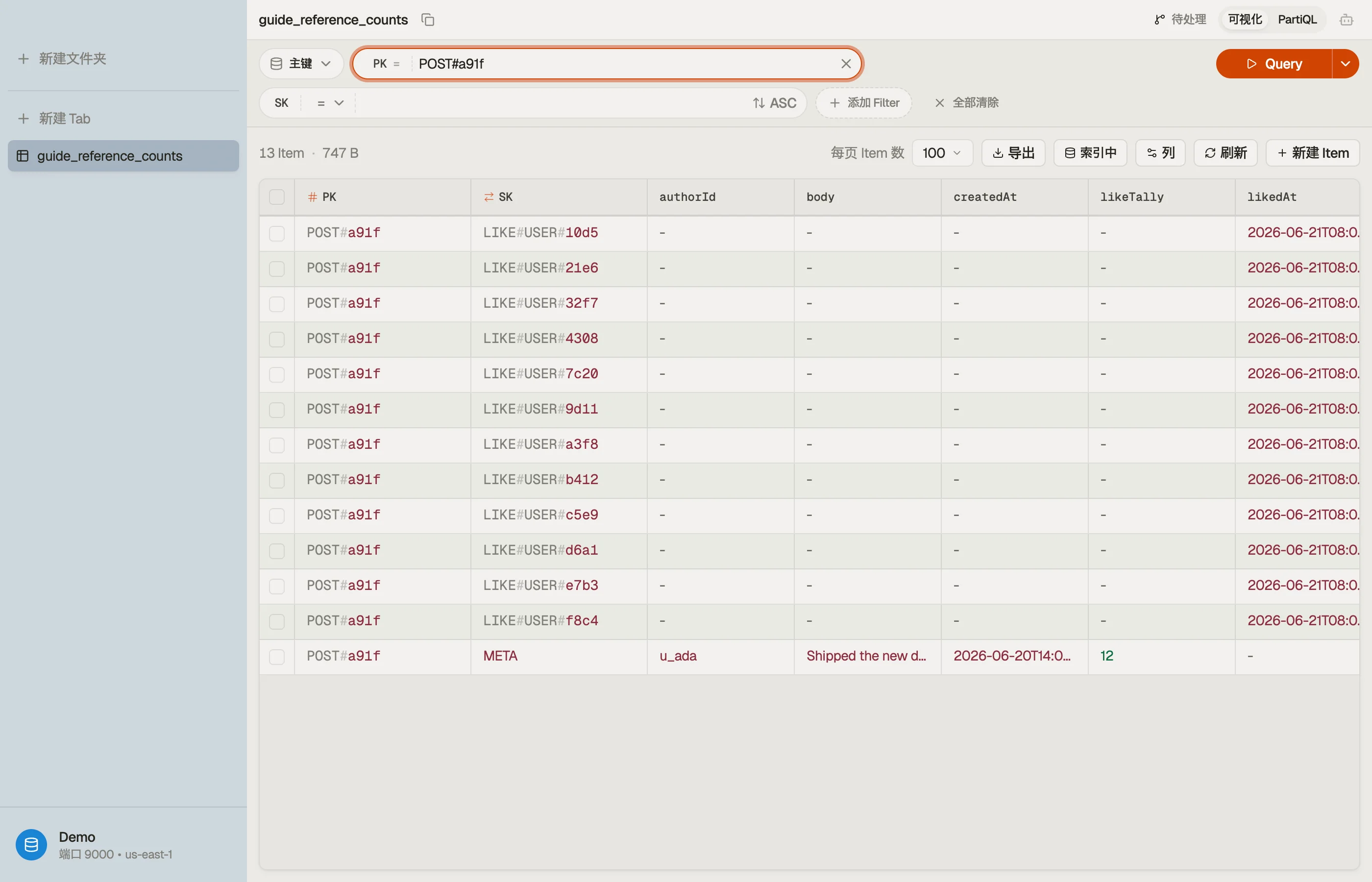

要在一组有界的帖子上做一次真正的对账——"哪些合计和它们的子项数对不上?"——DynoTable 的
SQL Workbench 在你已加载的行上于客户端跑 GROUP BY 和 join,而这正是普通 PartiQL 表达
不了的。
坑与下一步
- 别在带外维护计数(一个每晚重数一遍的 Lambda)。那是给一条本应从一开始就用事务的写入 路径打的创可贴。
- 盯住热分区。 一篇红得发紫的帖子会把每一个点赞——以及每一次合计递增——都集中到一个 partition key 上。计数是对的;分区可能仍然被限流。
- 少对账,外科手术式地修。 如果每次改动都加了 condition,漂移应该接近零。把一次对不上 当作一个要去找的 bug,而不是一个要去覆盖的数字。
延伸阅读:单表设计了解为什么帖子和点赞共享一个分区,以及 Query vs Scan了解为什么在读取时去数子项正是你要避开的那个模式。
然后 下载 DynoTable,去检查这些 item 集合,并对照你自己的表核验你的合计。