如何在 DynamoDB 中建模数据
在 SQL 里,你先建模实体和关系,然后信任查询规划器随后去拼装你要的任何东西。DynamoDB 把它反过来。 你建模你已经知道自己会做的读取,键的存在就是为了服务它们。
这里没有连接引擎,也没有在运行时挑选策略的规划器。一个 Query 沿一个键读取一个分区,而那就是
全部的性能契约。所以你为已知的访问模式设计键,而不是为一个工整的 schema。
AWS 在它的最佳实践指南 里讲得直白:“在你知道 schema 需要回答哪些问题之前,你不该开始设计它。”
本指南在一个领域上走一遍完整流程:一个多人对战游戏排行榜,追踪玩家、他们打的比赛,以及他们 的赛季排名。我们从一份问题清单出发,做到一个可用的键 schema。
如何在 DynamoDB 中建模数据?
先建模读取,而不是表。列出应用发出的每一个查询,然后设计分区键和排序键,使每个问题都能解析为单次 Query 或 GetItem。把一起读取的项共置在同一个分区键下,在排序键中做范围遍历,并为基础表无法服务的任何访问模式添加 GSI。
- 先列读取,而不是表。 问题才是规约;名词是干扰。
- 每个问题都必须是一次
Query或GetItem。 如果一个问题需要Scan,那模型就错了。 - 共置的项共享一个分区键;任何你要范围遍历的东西放进排序键。
- 基础表回答不了的问题加一个 GSI——绝不用带过滤的
Scan。
第 1 步——把问题框定为问句,而不是表
抵制住画出 players、matches 和 scores 表的冲动。那种本能是 SQL 的习惯,而在这里它是错的。
相反,写下应用真正执行的每个读取。对我们的排行榜:
- 通过 id 获取某个玩家的资料。
- 列出某个玩家最近的比赛,最新优先。
- 显示给定赛季按评分排名的前 N 名玩家。
- 通过公开昵称查找一个玩家(比如用于资料 URL)。
这四个问题——而不是那些名词——才是规约。每一个都必须解析为单次 Query(或 GetItem),
因为那是 DynamoDB 唯一能在规模下便宜服务的访问形态。
如果一个问题只能靠扫描表来回答,那模型就错了,你会在延迟和成本上感受到它——参见
Query 与 Scan 了解为什么 Scan 是要避开的坑。
整套方法是一条简短、有序的流水线,你每个领域跑一次:
下面每一步都映射到一个框:列出、枚举、设计键、为其余的加索引,然后验证。
第 2 步——理解你正在用来建模的原语
一张表有一个分区键(PK),它挑选一个项住在哪个物理分区上,还有一个可选的排序键(SK), 它在那个分区内部给项排序。
AWS 的核心组件文档
把这一对称为项的主键。一个 Query 始终针对恰好一个 PK 值,并且能对 SK 做范围扫描或过滤
——那就是全部工具箱。
正是这种单分区设计,让 DynamoDB 能交付 2007 年 Amazon Dynamo 论文中首次描述的那种可预测、 低延迟、横向分区的读取。
有两个后果驱动下面的每个决定:
- 被一起读取的项应该共享一个分区键,这样一次
Query就在单次计费请求中返回它们。 - 任何你想范围遍历的东西(最近的比赛、最高的评分)必须住在排序键里,因为那是
Query唯一能排序和设边界的属性。
当一个问题需要的访问形态与基础表提供的不同时,你加一个全局二级索引——表在不同 PK/SK 下的一次重新投影。
(关于 GSI 与本地二级索引,参见 GSI 与 LSI。)
第 3 步——一次设计一个问题的键
我们用一张表配通用、重载的键属性——单表方法——因为一个玩家 和他们的比赛是被一起读取的。
发明你自己的前缀;这里 PLAYER#、MATCH# 和 SEASON# 在原本通用的键里标记实体类型。
问题 1 和 2(资料 + 最近比赛)共享一个分区,所以两者都挂在同一个 PK 下:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" 在一次读取中返回资料和每一场比赛。只要资料,用 GetItem。
对于最近的比赛,rangeId begins_with "MATCH#" 配上 ScanIndexForward = false 以最新优先遍历它们
——排序键里的时间戳免费完成排序。
问题 3 和 4无法从那个分区回答——它们围绕赛季排名和昵称转,而两者都不是基础 PK。各得一个 GSI。
我们加两个通用索引属性 gsiPartition / gsiSort,让每个项用那个索引所需要的任何东西去填充它们:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
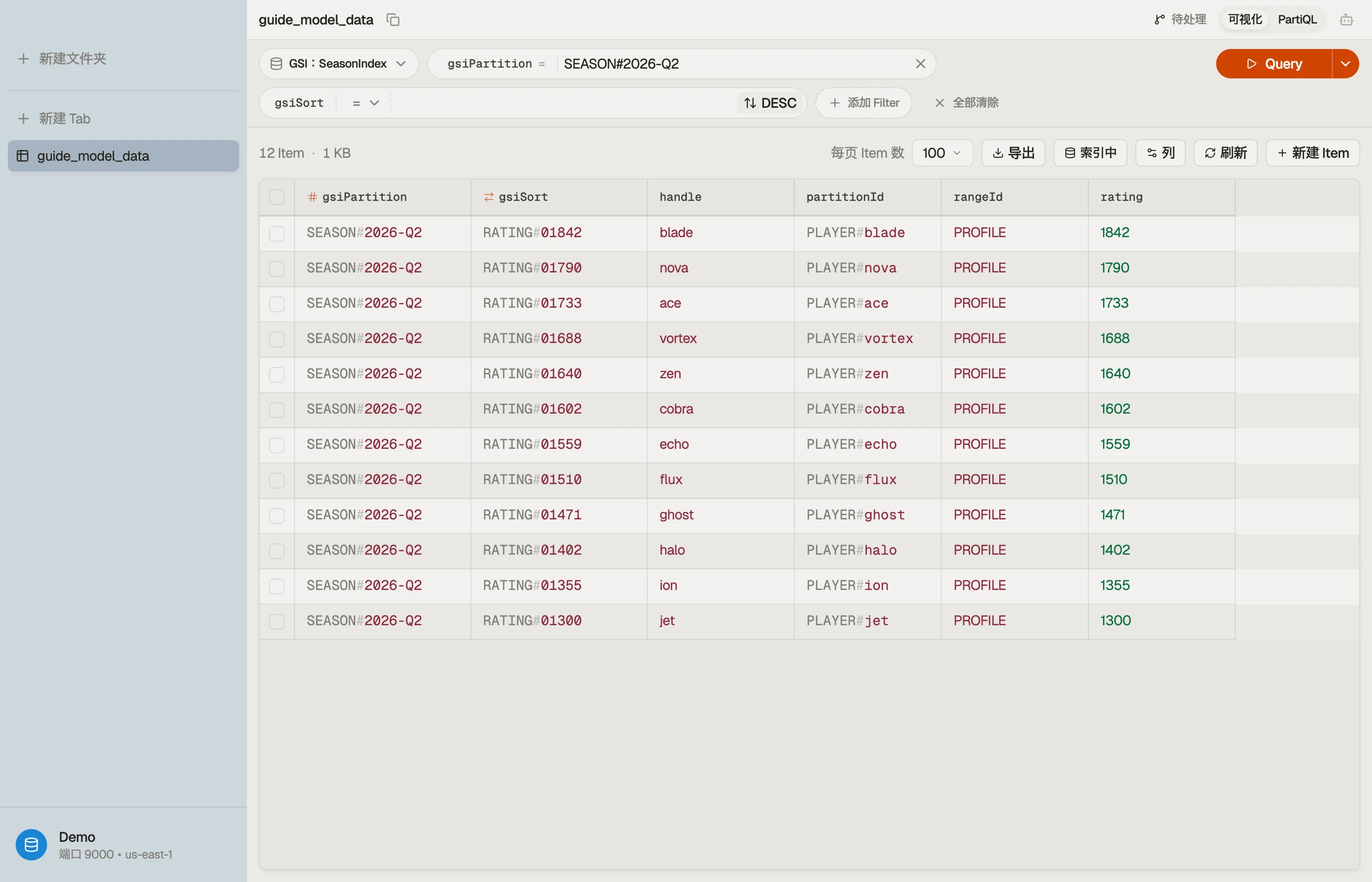
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
现在 Query 赛季索引 WHERE gsiPartition = "SEASON#2026-Q2" 配 ScanIndexForward = false
返回按评分排名的玩家——这就是排行榜。
第二个以 HANDLE#… 设键的索引在一次读取中把公开昵称解析为玩家 id。一张物理表,四个单 Query
访问模式。
关于
RATING#1842的零填充提醒:DynamoDB 对排序键按字典序排序,而不是按数值,所以一个评分 必须零填充到固定宽度(RATING#01842),否则9会排在1000之后。这是一个值得在一开始就弄对的 经典建模坑。
第 4 步——在 DynoTable 中验证模型
只有当你亲眼看到一次真实的 Query 恰好返回你预期的那些项、再无其他时,一个键 schema 才赢得信任。
在 DynoTable 中打开表,针对赛季索引运行排行榜查询,确认分区返回时已排名并设了边界——没有 Scan,
没有客户端排序。


当你为这些查询构建条件表达式时——那个 begins_with、那个 gsiPartition = :p、那个占位符 :p
绑定——让 DynamoDB Expression Builder 来做。
它会生成 KeyConditionExpression、ExpressionAttributeNames 和 ExpressionAttributeValues,
让像 result 这样的保留字或一个打错的占位符永远不会悄悄破坏一次读取。
第 5 步——陷阱与下一步
在上线模型之前要检查的几个坑:
- 别去建模你从不一起读取的关系。 每个问题一个 GSI 很便宜;一个浪费的 GSI 是经常性成本。 从问题清单出发加索引,而不是投机性地加。
- 留意分区热度。 如果一个 PK(一个明星玩家、一个火热赛季)吸收了大部分流量,那个分区可能限流。 当一个键被证明确实很热时,用后缀分片来分散写入——AWS 在 分区键设计 下涵盖了这一点。
- 对排序键里任何数值或时间值做零填充和 ISO-8601,让字典序与你想要的顺序一致。
- 一个新问题 = 一个新键或索引,绝不是
Scan。 当一个真正全新的访问模式后来出现时,扩展键; 别用一个过滤把它糊弄过去。
先建模问题,设计键让每个问题都是一次 Query,然后证明它。
试试 DynoTable 浏览你的表,对基础表和各 GSI 并排运行这些查询,看着你设计的访问模式 恰好返回你计划的东西。