DynamoDB 项集合
项集合是一张表(或索引)中共享同一分区键值的所有项的集合。它不是你打开的某个功能 ——它是你的键 schema 涌现出来的属性。
只要两个项带有相同的分区键,它们就构成一个集合,而这个集合就成了 DynamoDB 允许你在
单次 Query 中一起读取的单位。
把这件事做对,你的读取就在一次往返中返回。做错了,你就被困在 Scan 里。
什么是 DynamoDB 项集合?
DynamoDB 项集合是共享同一分区键值的所有项的集合,它们一起存储并按排序键排序。它不是你打开的某个功能——它是你的键 schema 涌现出来的属性。这个集合就是单次 Query 高效读取的单位,而 Scan 则要走遍每个分区。
- 一个集合不过是"相同分区键"。 两个或更多带有相同分区键值的项一起存储,按排序键排序。
- 它是高效
Query的单位。Query读取一个集合;Scan走遍每个分区。这就是全部的 性能故事。 - 没有排序键,就没有集合。 一张只有分区键的表每个键只持有一个项——没什么可集合的。
- 两个限制会咬人: 存在 LSI 时每集合 10 GB 的上限,以及低基数键带来的热分区。
问题:把相关项一起读出来
假设你运营一支车队,每辆车每隔几秒就流式上报遥测数据——车速、冷却液温度、油位。主导读取是
"给我车辆 V-7741 最近的读数"。
从 SQL 过来,你会给 vehicle_id 列建索引,让规划器替你干活。一个朴素的键值存储没有这种奢侈。
它把每条读数当作孤立的记录,所以那个问题意味着扫描整张表并过滤。又慢、又贵,而且随着车队 增长越来越糟。
DynamoDB 的回答是把"一辆车的所有读数"变成一个物理上分组、可直接寻址的东西。那个分组就是 项集合。
一个集合究竟是什么
DynamoDB 把项存储在分区中,并通过对分区键做哈希把每个项路由到一个分区。因此每个带有 相同分区键值的项都落到同一个分区,按排序键排序。
AWS 开发者指南就是这么命名的:共享一个分区键值的各项是一个项集合,一起存储并按排序键排序。
这与 2007 年 Amazon Dynamo 论文引入的思想一致——用一致性哈希把键分配到节点——并扩展了一个 排序维度,让相关项在磁盘上相邻而坐。
因为它们相邻且有序,DynamoDB 只用一次寻道就返回它们的一段连续区间。这就是为什么 Query
便宜而 Scan 不便宜:Query 读取单个集合;Scan 走遍每个分区。
要构成一个集合,你需要一个复合主键——一个分区键和一个排序键。仅以分区键设键的表每个键值 恰好有一个项,所以没什么可集合的。
我们的演练实例:车辆 → 遥测读数
用复合键建模遥测流。分区键标识车辆;排序键是读数的时间戳,它让读数在集合内从新到旧排序。
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPct这里住着两个集合——每辆车一个。META 项(车辆元数据)和 V-7741 的所有读数构成一个集合;
V-7742 的各项构成另一个。
注意这个窍门:给元数据一个排在任何 TS#... 值之前的排序键(META),那么对
PK = "VEH#V-7741" 的单次 Query 就会把这辆车的资料和它的读数一起返回。
这就是单表设计核心处的父子模式。
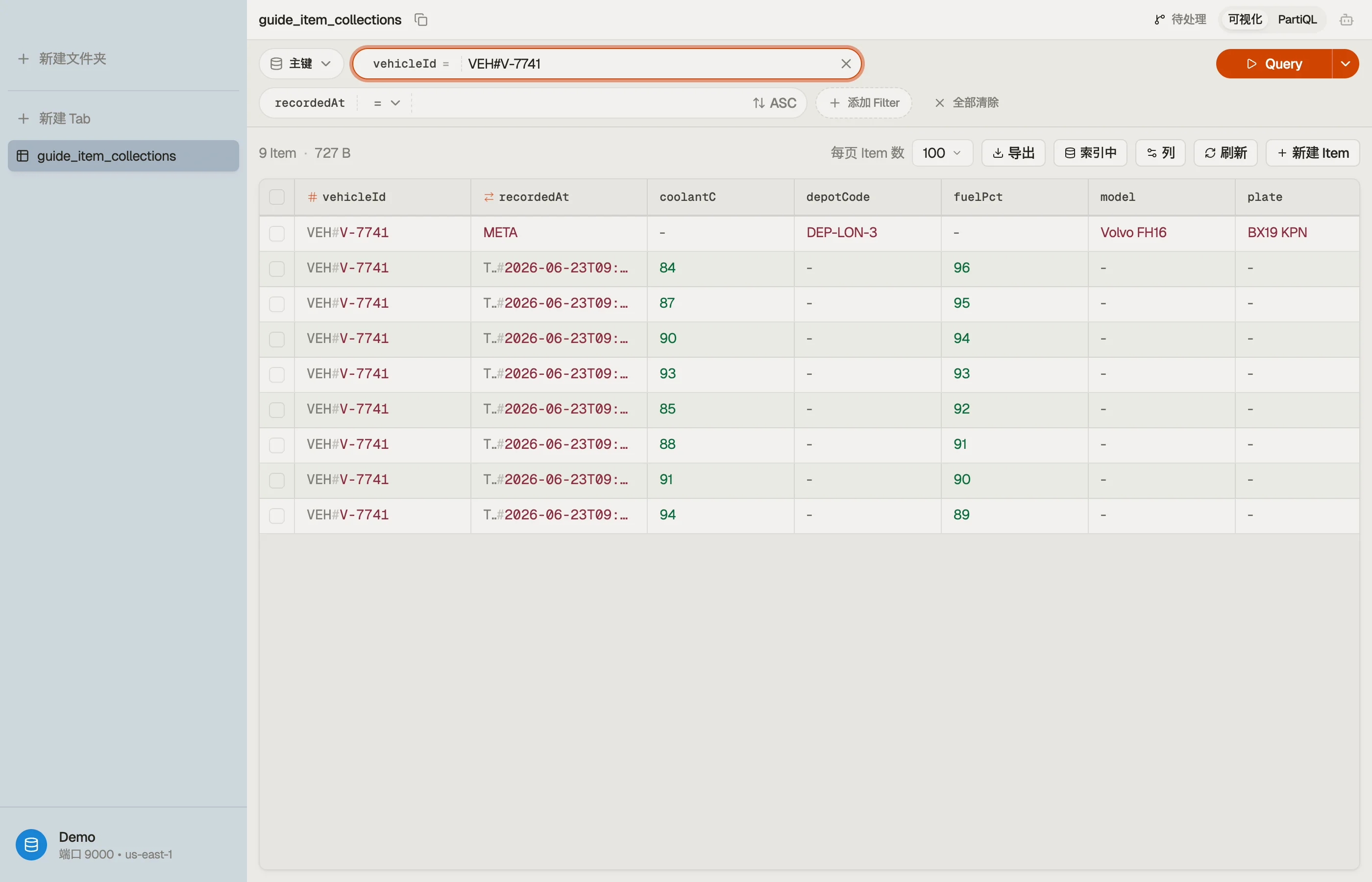
每个虚线框是一个项集合:相同分区键,各项按排序键排序。一次 Query 恰好读取一个框。
查询一个集合
因为集合按排序键排序,你免费得到范围读取。要拉取某辆车在十分钟窗口内记录的读数,你给排序键 设定边界:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest first键条件把你限制在一个集合(vehicleId = :v),再限制到它的一段连续切片
(recordedAt BETWEEN ...)。DynamoDB 只读取那些项,也只就它们向你计费。只想要元数据?
recordedAt = "META" 取出那个单独的 META 项。
手工构建这些键条件和投影表达式很繁琐。DynamoDB Expression Builder
会替你生成 KeyConditionExpression、ExpressionAttributeNames 和
ExpressionAttributeValues,让保留字和占位符的细节不再咬人。
索引上的集合
二级索引有它自己的键 schema,所以它构成它自己的项集合。
加一个以 depotCode(分区)和 recordedAt(排序)设键的全局二级索引,那么"来自车库
DEP-LON-3 的所有读数,最新优先"就变成针对那个索引集合的单次 Query——一个基础表服务
不了的读取。
这就是为什么索引类型很重要:它支配你能构成哪些集合以及它们如何表现。参见 GSI 与 LSI了解取舍。
一个尖锐的区分:本地二级索引(LSI)共享基础表的分区键,所以它的集合在物理上绑定到 基础项集合——而这种绑定造就了一个硬限制,见下文。
会咬人的限制
项集合很强大,但有两个约束决定你如何塑造键:
- 10 GB 的 LSI 限制。 当一张表有一个或多个本地二级索引时,单个项集合——一个分区键的
基础项加上它们的 LSI 投影——不能超过 10 GB。超过它,使集合增长的写入就开始以
ItemCollectionSizeLimitExceeded失败。一张没有 LSI 的表没有这种每集合的上限。这正是 为什么一个无界、不断增长的流(永不停止的遥测)不适合 LSI:集合只会增长。GSI 拥有它自己的 分区,所以它绕开了这个限制。 - 热分区。 一个集合住在一个分区里,而单个分区的吞吐量有限。如果一辆车(或一个
depotCode) 吸引了极不成比例的一份流量,你可能在整张表都欠配的情况下把那个分区搞热点。自适应容量 ——在 AWS 的"DynamoDB 高级设计模式"re:Invent 深度讲解中有涉及——会自动隔离并提升热键, 但它救不了一个完全没有分散的键。挑选高基数的分区键,让流量在许多集合间扇出。
在 DynoTable 中看它
建立对集合的直觉,最快的办法是看一个。在 DynoTable 中,查询一个分区键会把整个集合渲染为
一个连续、按排序键排序的列表——META 项就坐在它那些带时间戳的读数前面,在屏幕上,无需任何
心理重建。


陷阱与下一步
- 没有排序键,就没有集合。 一张只有分区键的表无法把相关项分组。如果你需要把项一起读, 你就需要复合键。
- 别让 LSI 集合无界增长。 仅追加的流属于 GSI(或一个按时间分桶的分区键),而不是 LSI, 因为有那个 10 GB 上限。
- 分散你的分区键。 一个集合的可扩展性,只取决于它所在的那个分区。低基数的分区键制造热点。
- 优先
Query,而不是Scan。 集合存在的意义就是让你用一次有针对性的Query读取相关项; 退回到Scan等于把这个优势扔掉——参见 Query 与 Scan。
勾勒你自己的键 schema,对一个真实的分区键运行一次 Query,看着集合有序地返回。
下载 DynoTable 直接探索你各张表的集合。