DynamoDB 中的键重载
从 SQL 过来,一列永远只意味着一件事:orders.created_at 永远是日期,users.email 永远是邮箱。键重载把那一套扔掉。你给分区键和排序键起通用的名字 —— pk、sk —— 让每一种项类型往里面灌入一种不同的含义。一张表,多种实体,一种形态。
DynamoDB 中的键重载是什么?
键重载是指用 pk/sk 这样的通用键名在一张表里存储多种实体类型,将类型编码进键值中(如 USER#u_3001、INVOICE#2026-0014)。属性名保持中性,用户、发票和事件因此共享同一个分区;值携带类型信息,而排序键前缀让单次 Query 通过 begins_with 切分出各种实体。
- 通用键名,带类型的值。 把你的键命名为
pk/sk,并把实体类型放进值里:pk = "TENANT#acme",sk = "USER#u_3001"。名字是迟钝的;值携带类型。 - 它是让单表设计成立的关键。 没有重载,一张共享表只是个杂物抽屉。有了它,每一种实体都坐落在一个你能
Query的分区里。 begins_with是回报。 排序键上的一个类型前缀让单次Query拉出一整个实体、或它的一个切片,不需Scan、不需筛选。- 代价是可读性。 一份原始的
pk/sk转储什么也告诉不了你。你需要一个能解码前缀的查看器,否则你就要对着字符串眯眼了。
为什么通用名字胜过真实名字
DynamoDB 每张表恰好有两个键属性,而一次 Query 只能瞄准单一一个分区键。所以如果你把键命名为 userId,那就只有用户项能干净地住在那张表里 —— 别的一切都得伪造一个 userId 或者搬到它自己的表去。
重载绕开了那个。一个中性的名字比如 pk 不向任何实体许下承诺,所以一个用户、一张发票和一个审计事件全都能共享同一个键属性和同一张表。说明项是什么的,是那个值,而非属性名。
这一招把单表设计从理论变成你真能拿来查询的东西。共享表是容器;重载是让各异的实体得以在其中共存的东西。
一个多租户示例
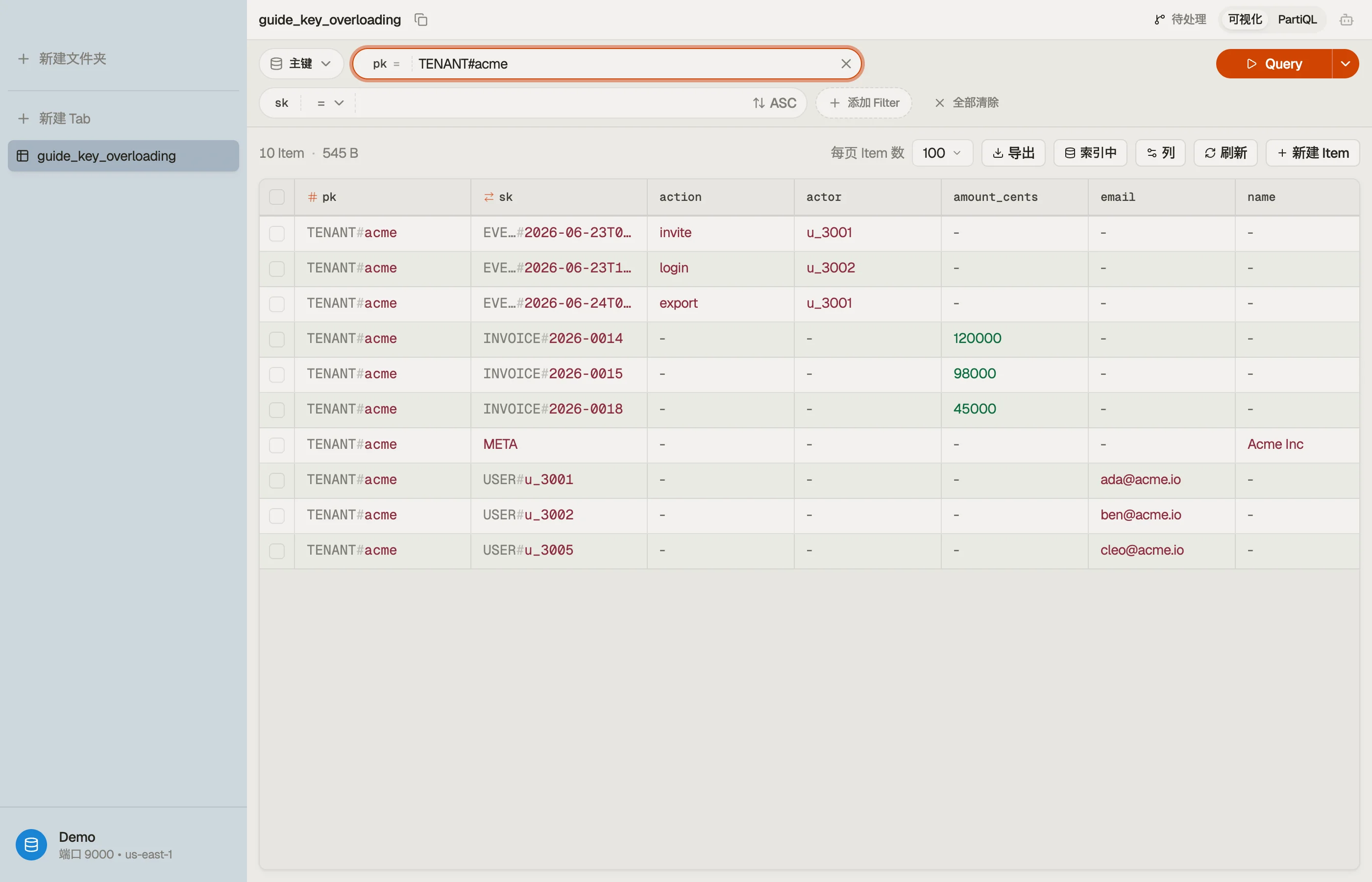
假设你运营一款 SaaS 计费产品。每个租户都有成员、发票和一条审计轨迹。别用三张表,把它们全放进一张并重载键:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
每一行都共享 pk = "TENANT#acme",所以它们构成一个项集合 —— 全都共置、全都在一次分区读取里可达。
排序键前缀在干真正的活。它给实体分组并给它们排序。
查询重载后的集合
因为类型住在排序键前缀里,begins_with 按实体切分分区,而不扫描任何东西:
Query pk = "TENANT#acme" -- 整个租户,每一种类型
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- 仅成员
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- 仅发票你只为条件匹配到的项付费,而非整个分区 —— 与一次带筛选的 Scan 正相反,后者你要付费去读取那些随后丢弃的行。AWS 把这叫做键条件;它在任何数据离开分区之前就在键上运行。
如果你手工构建那个 begins_with 条件,把类型标签弄对 —— 一个走神写成 USERS# 而非 USER# 会悄无声息地返回空。表达式构建器会生成 KeyConditionExpression 和 ExpressionAttributeValues 映射,好让前缀与你实际写的相符。
把索引也重载
同样的诀窍适用于 GSI。给它起通用键名 —— gsi1pk、gsi1sk —— 让每一种实体写它需要的任何东西。这样一个索引就能回答基表回答不了的模式。
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
现在 Query gsi1 WHERE gsi1pk = "STATUS#open" 列出跨所有租户的每一张未结发票,按到期日排序 —— 这是基表那套租户范围的键永远服务不了的跨分区视图。另一种实体可以用它自己的含义复用 gsi1(比如 gsi1pk = "ROLE#admin"),所以一个索引覆盖好几次读取。只是记住,一个 GSI 是最终一致的 —— 它的写入滞后于基表。
在 DynoTable 中实操
原始的重载键读起来很费劲:INVOICE#2026-0015 和 EVENT#2026-06-23T09:12Z 在一份扁平列表里糊成一团。一个按分区分组并把前缀凸显出来的查看器,把杂物抽屉重新变回实体。


暗坑
- 分隔符一次选定,永不更改。
#是约定。跨实体混用#和:会以无人警告你的方式破坏begins_with。 - 别重载需要范围数学的值。 一个排序键
INVOICE#2026-0015按字典序排序,而非数值序 —— 给 id 补零,并使用 ISO-8601 日期,好让字符串顺序与你想要的顺序相符。 - 预留前缀命名空间。 两种都以
USER开头的实体类型(比如USER#和USERGROUP#)会在begins_with(sk, "USER")下相撞。让前缀从第一个字符起就毫不含糊。 - 在键之前先规划读取。 重载服务的是你已经枚举出来的访问模式。如果你还不知道自己的读取,先看单表设计 —— 键是查询的下游产物。
把一个分区规划出来,然后下载 DynoTable,去浏览你自己的重载键,看一次 Query 一下子把整个租户拉回来。