Cuándo usar DynamoDB (y cuándo no)
DynamoDB es una base de datos fantástica para las cargas de trabajo para las que está hecha y frustrante para el resto. La pregunta decisiva no es "¿escala a la web?" — es "¿conozco mis patrones de acceso de antemano, y están basados en clave?" Acierta en eso y DynamoDB te da lecturas de un solo dígito de milisegundos a cualquier escala; falla y pelearás para siempre contra la falta de joins y consultas ad-hoc.
¿Cuándo debería usar DynamoDB?
Usa DynamoDB cuando tus patrones de acceso sean conocidos, estén basados en clave y sean de alto volumen, y quieras una latencia predecible de un solo dígito de milisegundos a cualquier escala sin servidores que gestionar. Evítalo para consultas ad-hoc, joins ricos o analítica sobre todo el conjunto de datos, y cuando los datos sean pequeños y las formas de las consultas no dejen de cambiar.
- Usa DynamoDB cuando tus patrones de acceso sean conocidos, basados en clave y de alto volumen — y quieras latencia predecible a cualquier escala sin servidores que gestionar.
- Evítalo cuando necesites consultas ad-hoc, joins ricos o analítica sobre todo el conjunto de datos, o cuando los datos sean pequeños y las formas de las consultas no paren de cambiar.
- El intercambio central: DynamoDB te obliga a diseñar para tus consultas de antemano; a cambio nunca se ralentiza a medida que creces.
- No es una base de datos relacional con otra sintaxis — modelarla como una es la fuente de dolor número uno.
Las señales que favorecen a DynamoDB
DynamoDB brilla cuando se cumplen la mayoría de estas:
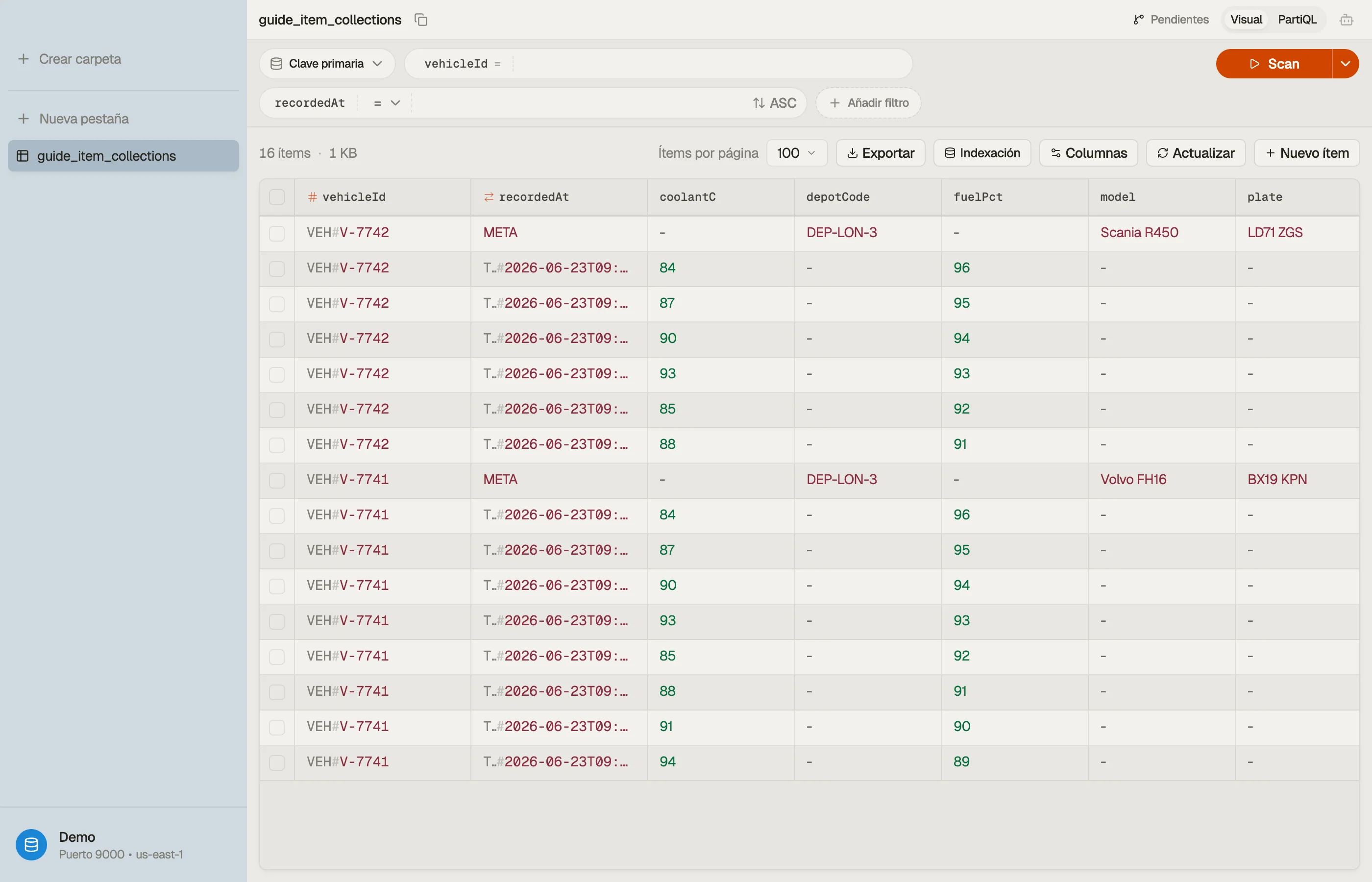
- Conoces tus patrones de acceso por adelantado. Puedes listar las consultas exactas que hace la app ("obtener un usuario por id", "listar los pedidos de un usuario, los más nuevos primero") y no cambian por capricho. DynamoDB se modela en torno a esas consultas.
- El acceso está basado en clave. Buscas elementos por una clave de partición conocida, no escaneando combinaciones arbitrarias de atributos.
- La escala y la latencia predecible importan. DynamoDB entrega un rendimiento consistente de un solo dígito de milisegundos tanto si la tabla guarda mil elementos como si guarda mil millones.
- Quieres cero sobrecarga operativa. Sin instancias, sin failover, sin vacuuming — está totalmente gestionada y escala a cero bajo demanda.
- El rendimiento de escritura es alto e irregular. Registros de eventos, telemetría de IoT, estado de sesión/carrito, tablas de clasificación — cargas de trabajo intensivas en append con una clave clara.
Las señales en contra
Recurre a una base de datos relacional (o a un motor de búsqueda/analítica) cuando:
- Tus consultas son ad-hoc. Los analistas trocean los datos por columnas arbitrarias, o los requisitos cambian semanalmente. Gana la flexibilidad de SQL; DynamoDB necesitaría un índice nuevo por patrón.
- Necesitas joins y agregaciones reales sobre todo el conjunto de datos. Informes, inteligencia de negocio, "suma los ingresos por región por mes" — eso es un trabajo OLAP/relacional.
- El conjunto de datos es pequeño y de poco tráfico. Unos pocos miles de filas en una app de administración tranquila no obtienen ningún beneficio de la escala de DynamoDB y pierden la comodidad de SQL.
- Aún no puedes predecir los patrones de acceso. ¿Un producto en fase temprana todavía buscando su forma? Un esquema relacional que puedes reconsultar libremente perdona más hasta que los patrones se asienten.
Calcular el coste antes de comprometerte
El precio de DynamoDB sigue las lecturas, escrituras y almacenamiento — no las horas de instancia — así que es barato para cargas irregulares y serverless y puede ser caro para escaneos pesados sostenidos. Modela tu mezcla real de lectura/escritura con la calculadora de precios de DynamoDB antes de comprometerte; una carga de trabajo que parece encajar técnicamente también debería salir a cuenta en coste.
Una vez que has decidido que encaja
El trabajo se desplaza al modelado. DynamoDB recompensa diseñar la tabla en torno a tus consultas — consulta cómo modelar datos en DynamoDB y diseño de tabla única — y explícitamente cuándo no recurrir a la tabla única.


Trampas y próximos pasos
- No modeles DynamoDB como una base de datos relacional — tablas normalizadas que unes en tiempo de lectura es el antipatrón que más castiga.
- No lo elijas para analítica — combínalo con un almacén analítico (o exporta a uno) para informes en lugar de escanear.
- ¿Inseguro sobre los patrones de acceso? Espera. Adoptar DynamoDB antes de conocer tus consultas es elegir la única base de datos que exige que las conozcas.
- Relacionado: query vs scan muestra qué te compra de verdad el "acceso basado en clave".
¿Quieres explorar una tabla de DynamoDB antes de apostar tu app por ella? Descarga DynoTable y conéctate a tus datos directamente.