Relaciones muchos-a-muchos en DynamoDB
Un estudiante se inscribe en muchos cursos; un curso reúne a muchos estudiantes. En SQL
recurres a una tabla de unión y a un JOIN de cuatro vías.
DynamoDB no tiene joins, así que la relación tiene que vivir en las claves — y el
truco es almacenar cada arista de inscripción en una forma que ambos lados puedan
consultar con Query directamente.
Esta guía recorre el problema estudiantes ↔ cursos de principio a fin: los patrones de acceso, el patrón de lista de adyacencia que los resuelve, un esquema de claves original que puedes copiar y cómo leer ambas direcciones sin escanear nunca la tabla.
¿Cómo se modela una relación muchos-a-muchos en DynamoDB?
DynamoDB no tiene joins, así que modelas una relación muchos-a-muchos con el patrón de : almacena cada vínculo como su propio elemento-arista indexado por uno de los lados y añade un GSI invertido que intercambia las claves. Una sola arista, escrita una vez, responde consultas desde ambas direcciones de forma eficiente.
- Almacena cada inscripción como su propio elemento-arista, no como un atributo de lista en cualquiera de los lados.
- Indexa la arista por el estudiante (
PK = STU#…,SK = ENROLL#CRS#…) para que una solaQuerydevuelva toda la lista de cursos de un estudiante. - Añade un GSI invertido que intercambia los roles (
GSI1PK = CRS#…) para que la misma arista también responda "¿quién está en este curso?". - Una arista, escrita una vez, se lee barato en ambos sentidos — ese es todo el juego.
Encuadra primero los patrones de acceso
El modelado en DynamoDB es primero-el-patrón-de-acceso: decides las lecturas antes de elegir un solo nombre de atributo. Una relación muchos-a-muchos casi siempre tiene dos lecturas simétricas más las búsquedas de entidades:
- Obtener el perfil de un estudiante y listar cada curso en el que ese estudiante está inscrito.
- Obtener los metadatos de un curso y listar cada estudiante inscrito en ese curso.
- Buscar una sola arista de inscripción — para actualizar una nota o darse de baja del curso.
El dolor: las dos lecturas de lista apuntan en direcciones opuestas a través del mismo
conjunto de aristas. Un diseño ingenuo sirve una barato y obliga a un Scan para la otra
— exactamente el tiro al pie que se cubre en Query vs Scan.
El trabajo es hacer que ambas direcciones sean una sola Query.
Usa el patrón de lista de adyacencia
La guía propia de DynamoDB para relaciones es la lista de adyacencia: modela cada relación como un elemento cuya partition key es un extremo y cuya sort key es el otro.
AWS lo documenta en la página Best Practices for Managing Many-to-Many Relationships de la DynamoDB Developer Guide.
¿Por qué claves y no una segunda tabla? Porque la primitiva que DynamoDB te da es una
Query contra una sola partición.
Una Query lee un rango contiguo de valores de sort key bajo una partition key en una
operación facturada — ese es el único "join" que ofrece el motor.
Para obtener una relación que se lea barato desde ambos lados, duplicas la arista: la escribes una vez indexada por el estudiante, luego usas un índice secundario para proyectar la misma arista indexada por el curso.
Este es el pensamiento de clave-sobrecargada del diseño de tabla única, aplicado a una relación en lugar de a una jerarquía padre-hijo.
La forma son dos vistas apiladas de la misma arista — la tabla base indexada por estudiante, el GSI invertido indexado por curso:
Cada arista se escribe una vez en la tabla base y se proyecta en el GSI con sus claves
intercambiadas, así que una Query contra cualquiera de las particiones lee la relación
barato.
El linaje se remonta al artículo Dynamo de Amazon de 2007: la partition key es la unidad de distribución y el acceso por clave única es el camino rápido.
Las relaciones en DynamoDB son un ejercicio de doblar las lecturas muchos-a-muchos para que entren en ese camino rápido.
Trabaja el ejemplo: estudiantes ↔ cursos
Usa una tabla con claves genéricas, PK y SK, y codifica el tipo de entidad en el
valor. La arista de inscripción es el corazón de todo:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Una sola Query PK = "STU#a91" devuelve el perfil del estudiante y cada inscripción
en una lectura. Acótala con SK begins_with "ENROLL#" para obtener solo las aristas de
curso. Eso resuelve "listar los cursos de un estudiante".
Pero "listar los estudiantes de un curso" apunta en sentido contrario — y la tabla base no puede responderlo, porque el id del estudiante está en la partition key, no en la sort key.
Añade un índice secundario global invertido que intercambie los roles. Da a los
elementos-arista un par genérico GSI1PK/GSI1SK que lleve el curso en el lado de la
partición y el estudiante en el lado del orden:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Ahora Query GSI1 WHERE GSI1PK = "CRS#math204" lista cada estudiante de ese curso — la
lectura que la tabla base no podía servir. Un elemento-arista, escrito una vez, responde
a ambas direcciones.
Tiene que ser un GSI, no un LSI: la partición del curso es completamente distinta de la partición del estudiante, y un LSI comparte la partition key de la tabla base.
El índice abarca varias particiones, así que debe ser global — consulta GSI vs LSI.
Un detalle: los GSI en DynamoDB se rellenan de forma asíncrona. Una inscripción
recién-creada puede tardar un momento en aparecer en la dirección CRS#….
Trata la lectura de la lista del curso como eventualmente consistente — lo que la Developer Guide señala explícitamente para los índices secundarios globales.
Escríbelo y léelo en DynoTable
Escribir la inscripción significa establecer cuatro atributos de clave más los datos
propios de la arista. La condición que impide que un estudiante se inscriba dos veces en
el mismo curso es una guarda attribute_not_exists(PK) sobre la clave compuesta.
Ese es exactamente el tipo de condición que puedes ensamblar visualmente con el
Constructor de expresiones de DynamoDB en lugar de
escribir a mano los ExpressionAttributeNames y los valores de marcador de posición.
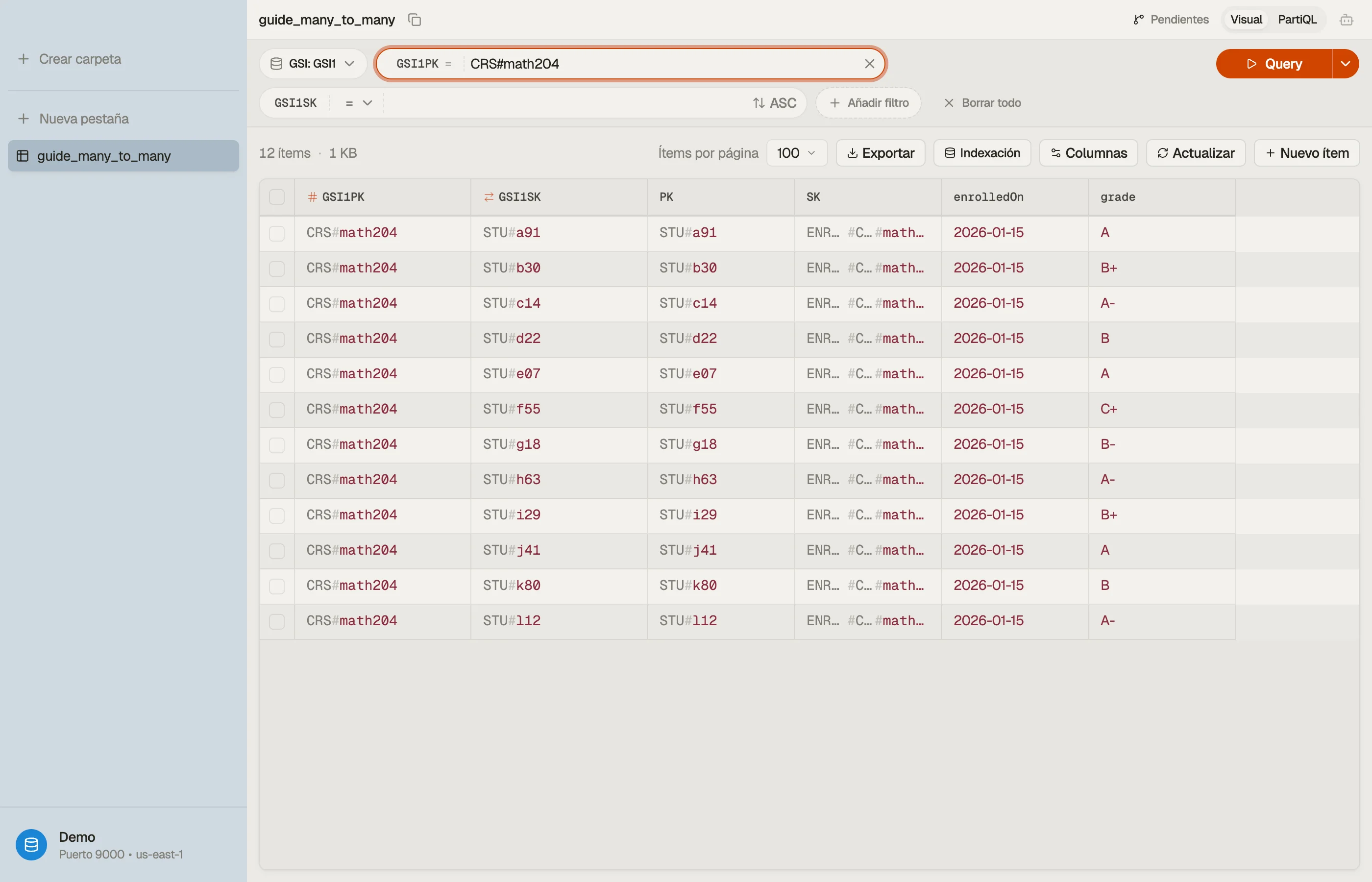
En DynoTable apuntas una Query a GSI1, estableces GSI1PK = "CRS#math204", y la
lista de inscritos vuelve como una tabla que puedes leer, ordenar y editar en el sitio —
ambas direcciones de la relación navegables desde un solo esquema.


Trampas y próximos pasos
- No almacenes un lado como atributo de lista. Un array
courseIdsen el elemento del estudiante parece ordenado hasta que un curso necesita su lista de inscritos, el array choca con el techo de 400 KB por elemento, o dos inscripciones compiten y se pisan. Los elementos-arista discretos escalan y se actualizan de forma independiente. - Mantén los datos de la arista en la arista. El
gradey elenrolledOnde la inscripción pertenecen al elemento-arista, no duplicados en el estudiante o el curso — hay exactamente una fila por par (estudiante, curso) que actualizar. - Atento a la propagación del GSI. La dirección del índice invertido es eventualmente consistente, así que una lectura inmediatamente después de una inscripción puede ir con un retraso de una fracción de segundo.
- Proyecta solo lo que la lista de inscritos necesita. Una proyección
KEYS_ONLYo estrecha mantiene el GSI pequeño cuando la vista de la lista solo necesita ids.
Para profundizar en los patrones circundantes, lee Diseño de tabla única para claves sobrecargadas y GSI vs LSI para cuándo el índice invertido tiene que ser global.
Luego descarga DynoTable para modelar el esquema estudiantes ↔ cursos de verdad — escribe las aristas, construye la condición con el Constructor de expresiones y consulta ambas direcciones de la relación sin un solo escaneo.