Estrategias de sort key en DynamoDB
Una clave primaria de DynamoDB son uno o dos atributos: una partition key sola, o una partition key más una sort key. La partition key decide qué partición física contiene un elemento.
La sort key decide el orden de los elementos dentro de esa partición — y ese
ordenamiento es lo que hace potente a Query.
Elige la sort key equivocada y aún puedes escribir datos, pero pierdes las lecturas de rango, el ordenamiento y varios patrones de acceso de una sola colección.
Viniendo de SQL recurrirías a un ORDER BY o a un índice secundario después de los
hechos. En DynamoDB horneas el orden en la clave por adelantado, o no lo obtienes.
¿Cómo funcionan las sort keys en DynamoDB?
Una sort key de DynamoDB ordena los elementos dentro de una partición, de modo que Query puede hacer lecturas de rango — >=, between, begins_with — en lugar de obtener un elemento a la vez. El ordenamiento es orden-de-bytes sobre la clave codificada, así que diseña la clave (una marca de tiempo ISO-8601, un número rellenado con ceros) para que el orden de bytes equivalga al orden en que quieres leer.
- La sort key es tu índice dentro de la partición. Ordena la colección de elementos en
disco, así que
Querypuede hacer lecturas de rango (>=,between,begins_with) en lugar de un únicoGetItem. - El ordenamiento es orden-de-bytes sobre la clave codificada. Diseña la clave para
que el orden de bytes equivalga al orden en que quieres leer — una marca de tiempo
ISO-8601, un número rellenado con ceros, nunca un UUID en bruto ni
6/23/2026. - Una sola sort key bien formada sirve a muchos patrones de acceso. Una clave compuesta
(
EVT#<timestamp>) es un prefijo y un rango a la vez — no se necesita GSI. - La dirección es gratis.
ScanIndexForward = falselee las más nuevas primero al mismo coste; no almacenes marcas de tiempo invertidas para fingirlo.
Por qué la sort key es la palanca
Sin una sort key, cada elemento de una partición solo es direccionable por su clave
primaria completa — un GetItem como mucho. Añade una sort key y DynamoDB almacena los
elementos ordenados por ella dentro de la partición, lo que desbloquea Query.
Eso significa condiciones de rango (>=, between), coincidencia de prefijo
(begins_with), y un flag ScanIndexForward para leer en orden ascendente o descendente.
Según la AWS DynamoDB Developer Guide, todos los elementos que comparten una partition key forman una colección de elementos, ordenada en disco por la sort key.
Así que la sort key no es solo un segundo identificador. Es el índice contra el que consultas dentro de una partición.
Ese ordenamiento es orden-de-bytes sobre la sort key codificada: las cadenas se comparan por bytes UTF-8, los números se comparan numéricamente. Este único hecho guía casi todas las estrategias de abajo.
Si quieres que las consultas de rango signifiquen algo, el orden de bytes tiene que coincidir con el orden en que quieres leer.
Estrategia 1: haz la sort key ordenable
El error más común es una sort key que no está ordenada de forma significativa. Un UUID aleatorio te da unicidad pero ninguna consulta de rango útil — "dame los últimos 20" se vuelve imposible porque el orden de bytes es arbitrario.
En su lugar, codifica el valor por el que ordenas y filtras dentro de la sort key, en una representación cuyo orden de bytes equivalga a su orden lógico. Para marcas de tiempo eso significa un formato ordenable lexicográficamente: una cadena ISO-8601 o un epoch rellenado con ceros.
ISO-8601 fue diseñado para que la comparación de cadenas equivalga a la comparación
cronológica — exactamente lo que necesita una consulta de rango. Evita formatos como
6/23/2026; se ordenan mal en cuanto cambia el mes.
Si ordenas por números (un contador de versión, una puntuación), usa el tipo Number
nativo de DynamoDB en lugar de una cadena, para que 42 se ordene después de 9 en lugar
de antes.
Si un número debe vivir dentro de una sort key de cadena compuesta, rellénalo con ceros a un ancho fijo.
Estrategia 2: sort keys compuestas para jerarquía
Una sort key puede codificar una jerarquía concatenando segmentos con un delimitador, lo
más común #. Una sola condición begins_with selecciona entonces todo un subárbol:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") devuelve solo los eventos de junio; el más amplio
begins_with(SK, "EVENT#") los devuelve todos.
El orden de los segmentos es una decisión de diseño. De grueso a fino (año → mes → día) mantiene los elementos relacionados contiguos, así que una lectura de rango sigue siendo una consulta barata en lugar de una dispersión por la partición.
Estrategia 3: controla la dirección con ScanIndexForward
DynamoDB almacena los elementos en orden ascendente de sort key y los lee así por
defecto. Para leer las más nuevas primero — el orden natural para un feed de actividad —
establece ScanIndexForward = false en la Query.
Este es un flag de tiempo-de-lectura, no una decisión de esquema: la misma colección sirve ambas direcciones al mismo coste. No inviertas tus marcas de tiempo (almacenando un "epoch inverso") solo para conseguir lecturas descendentes.
Una colección de elementos, almacenada una vez en orden ascendente, leída en cualquier sentido:
Los mismos elementos, la misma partición, el mismo coste — solo difiere la dirección de lectura.
La única excepción: si necesitas específicamente que el orden descendente sea también el
orden en que avanza un índice disperso o un cursor de paginación. Salvo eso,
ScanIndexForward es la palanca más simple.
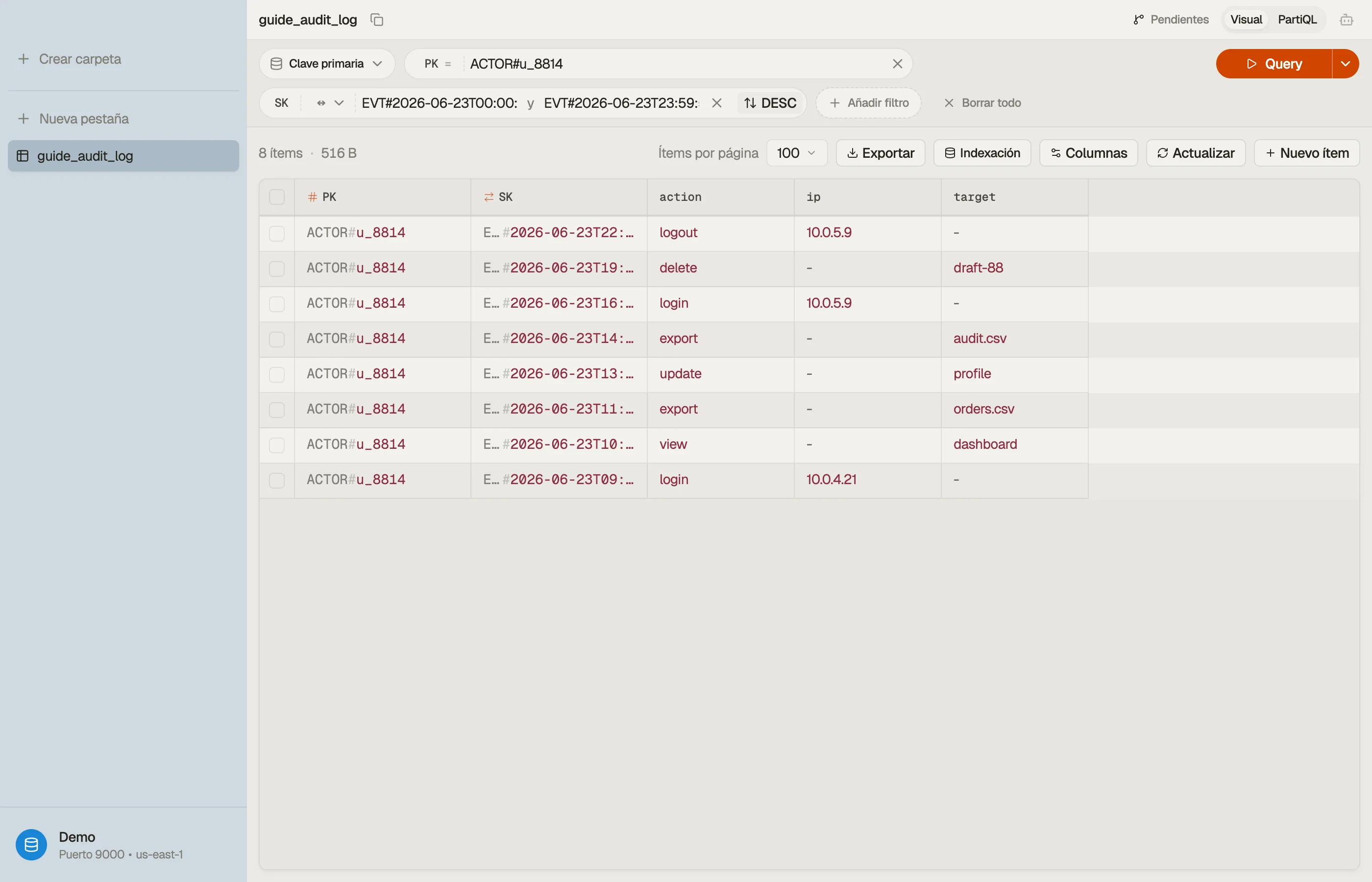
Ejemplo desarrollado: un registro de auditoría acotado por actor
Supón que registras eventos con marca de tiempo producidos por actores — usuarios, servicios, claves de API — en un producto SaaS, y tienes dos lecturas:
- El flujo de actividad de un actor, el evento más nuevo primero.
- Los eventos de un actor dentro de una ventana de tiempo (p. ej. "todo entre los dos despliegues"), para una investigación.
Ambas lecturas están acotadas a un solo actor, así que el actor es la partition key y la hora del evento es la sort key. Usa nombres de clave genéricos para que la misma tabla pueda contener otras entidades después:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
El prefijo EVT# más una marca de tiempo ISO-8601 da una sort key ordenable. La lectura 1
es Query PK = "ACTOR#u_8814" con ScanIndexForward = false para las más nuevas primero.
La lectura 2 acota la misma partición con una condición between sobre la sort key:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"Una colección, dos patrones de acceso, sin GSI — porque la sort key es a la vez un prefijo
(EVT#) y un rango (la marca de tiempo). La lectura descendente y la lectura de ventana
son los mismos elementos en el mismo orden; solo difieren los parámetros.
Construyendo esa condición de clave a mano, es fácil equivocarse con los límites del
between o con el escapado de palabras reservadas en los nombres de atributo.
El Constructor de expresiones de DynamoDB
genera la KeyConditionExpression, los ExpressionAttributeNames y los
ExpressionAttributeValues para una condición de sort key begins_with o between.
Cópialo directamente en tu llamada al SDK en lugar de depurar el escapado en tiempo de ejecución.
Hazlo en DynoTable
Diseñar una sort key es iterativo: escribe unos cuantos elementos representativos, ejecuta la consulta de rango y comprueba que las filas vuelven en el orden que esperas. Hacer eso contra una tabla en vivo en una GUI supera al ir y volver a través del código.


Invierte la dirección de orden, ajusta los límites del between y observa cómo cambia la
colección devuelta sin escribir una línea de código — la forma más rápida de confirmar un
diseño de sort key antes de comprometerlo.
Trampas y próximos pasos
- Las sort keys deben ser únicas dentro de una partición. Si dos eventos pueden compartir una marca de tiempo, añade un desambiguador (un número de secuencia o un id corto) a la sort key para que el compuesto siga siendo único.
- Una partición caliente no se puede ordenar para esquivar. Si un actor produce muchos más eventos que el resto, la sort key no te salvará — necesitas un diseño de partition key que distribuya la carga. Consulta diseño de tabla única.
- Un segundo orden necesita un segundo índice. La sort key de la tabla base da un ordenamiento. Para ordenar los mismos elementos de otra manera (por tipo de evento, digamos), añade un GSI con una sort key distinta — sopesando los compromisos del índice secundario local vs global.
- No recurras a
Scanpara "ordenar después". Ordenar del lado del cliente tras unScanlee toda la tabla y tira el ordenamiento por la borda; ese es el tiro al pie del Scan. Empuja el orden a la sort key en su lugar.
Una vez que la condición de clave esté bien, prueba DynoTable para modelar la colección, ejecutar las consultas ascendente y descendente lado a lado, y verificar tu estrategia de sort key contra datos reales antes de que se publique.