Relaciones uno-a-muchos en DynamoDB
Un plano de control SaaS casi siempre tiene una jerarquía de contención: un espacio de
trabajo posee muchos proyectos. En SQL pondrías una foreign key workspace_id en
la tabla de proyectos y harías un JOIN.
DynamoDB no tiene joins ni foreign keys, así que la relación tiene que vivir en el propio
esquema de claves. Bien hecho, "cargar un espacio de trabajo y cada proyecto dentro
de él" se convierte en una sola Query en lugar de una lectura más un escaneo posterior.
¿Cómo se modela una relación uno-a-muchos en DynamoDB?
Dale al padre y a todos sus hijos la misma para que compartan una sola , y luego diferéncialos con la sort key. DynamoDB no tiene joins ni foreign keys, por lo que la relación vive en el propio esquema de claves. Cargar un padre junto con todos sus hijos se convierte entonces en una sola Query en lugar de un join.
- Modela las lecturas, no las entidades. La relación uno-a-muchos solo existe para servir "listar los proyectos de un espacio de trabajo" — da forma a las claves en torno a esa consulta.
- Codifica el padre en la partition key del hijo. Da al espacio de trabajo y a todos sus proyectos el mismo valor de partition key para que caigan en una sola colección de elementos.
- Entonces la lectura de lista es una sola
Query. El padre más un número arbitrario de hijos vuelven en una sola llamada facturada — sin join, sin segundo viaje de ida y vuelta. - Vigila la partición caliente. Un inquilino enorme concentra todo su tráfico en una partición; un espacio de trabajo gigante puede necesitar una clave fragmentada y una lectura distribuida.
El patrón de acceso, primero
El modelado en DynamoDB es primero-el-patrón-de-acceso, no primero-la-entidad — la misma disciplina detrás del diseño de tabla única. Antes de elegir cualquier clave, anota las lecturas que la app realmente emite:
- Obtener la configuración de un espacio de trabajo.
- Listar cada proyecto de un espacio de trabajo, del más nuevo al más antiguo.
- Obtener un proyecto concreto por id.
La relación "un espacio de trabajo, muchos proyectos" solo importa por la lectura #2. Si nunca necesitaras listar juntos los proyectos de un espacio de trabajo, no modelarías la relación en absoluto — almacenarías los proyectos de forma independiente.
Así que la pregunta nunca es "¿cómo represento uno-a-muchos?" en abstracto. Es "¿qué consultas debe servir esta relación?". Responde a eso, luego da forma a las claves en torno a ello.
Por qué una foreign key no ayuda aquí
En DynamoDB cada GetItem y Query apunta a una partition key, y el servicio aplica
un hash a esa clave para localizar la partición que contiene el elemento.
AWS lo dice directamente en la documentación de Core Components: el valor de la partition key es la entrada de una función hash interna que decide dónde viven los datos.
Esa colocación basada en hash es la herencia del artículo original de 2007 Dynamo: Amazon's Highly Available Key-value Store, donde un hashing consistente distribuye las claves entre nodos.
Un mero atributo workspace_id en un elemento de proyecto es invisible para esa
maquinaria — DynamoDB no puede "seguirlo".
Para traer elementos relacionados en una sola petición, la identidad del padre debe estar
codificada en la partition key del proyecto, para que todos los elementos de un
espacio de trabajo tengan el mismo hash en la misma partición y una sola Query pueda
barrerlos.
Ejemplo desarrollado: espacios de trabajo y proyectos
Usa un esquema de claves genérico y sobrecargado. Llama a la partition key EntityRef y
a la sort key Detail. La identidad del espacio de trabajo va en EntityRef tanto para
el elemento del espacio de trabajo como para cada proyecto bajo él:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
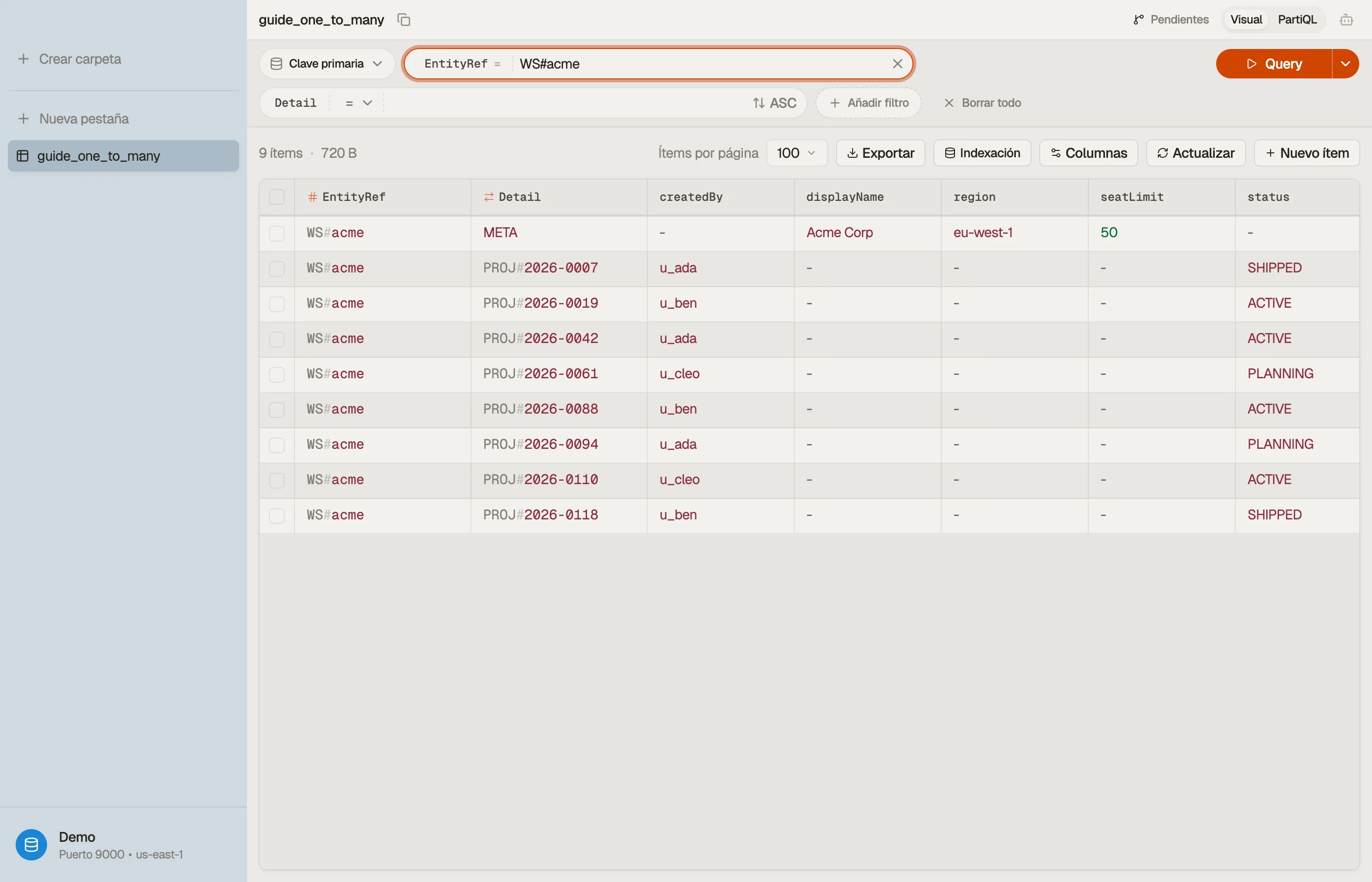
El espacio de trabajo y todos sus proyectos comparten EntityRef = "WS#acme", así que
forman una sola colección de elementos que vive junta en una partición.
La sort key Detail los separa: META es el registro del espacio de trabajo, y cada
proyecto lleva un prefijo PROJ# con un id ordenado por tiempo y rellenado con ceros para
que los proyectos se ordenen de forma natural.
Visualmente, el padre y sus hijos se apilan dentro de una partición, ordenados por la sort key:
Una sola Query sobre EntityRef = "WS#acme" barre toda la pila — el padre más cada
hijo — en una sola lectura.
Ahora cada uno de los tres patrones de acceso se reduce a una llamada:
- Configuración del espacio de trabajo —
GetItem(EntityRef="WS#acme", Detail="META"). - Listar proyectos del más nuevo al más antiguo —
Query(EntityRef="WS#acme")conDetail begins_with "PROJ#", ejecutada en orden descendente (ScanIndexForward = false). - Un proyecto —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
La segunda es el quid de todo: el padre y un número arbitrario de hijos vuelven en
una sola Query facturada, sin join y sin segundo viaje de ida y vuelta. Ese es el
movimiento que no puedes hacer con un atributo foreign key y un Scan.
Escribir esa condición begins_with a mano es engorroso — la sintaxis de la condición de
clave y de la expresión de proyección muerde.
El Constructor de expresiones de DynamoDB genera la
KeyConditionExpression, los mapas de marcadores #name/:value, y un fragmento de SDK
listo para ejecutar para que no pelees con la gramática:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Inspecciona la colección de elementos en DynoTable
La recompensa de esta disposición es visual: cada fila que comparte un EntityRef es el
espacio de trabajo más sus hijos, situados unos junto a otros.
DynoTable los agrupa para que veas la relación uno-a-muchos como un bloque contiguo en lugar de adivinarla a través de tablas separadas.


Trampas y la forma alternativa
Algunas cosas que vigilar:
- Particiones calientes. Cada elemento de un espacio de trabajo vive en una
partición, así que un único inquilino muy grande o muy activo concentra el tráfico. El
comportamiento de capacidad adaptativa
que AWS describe absorbe un sesgo moderado, pero un espacio de trabajo con millones de
proyectos puede necesitar una clave fragmentada (p. ej.
WS#acme#01 … #10) y una lectura distribuida. - Tamaño de la colección de elementos. Con un índice secundario local, la colección de elementos de una sola partición está limitada a 10 GB; sin un LSI no hay tal límite. Si estás sopesando tipos de índice aquí, consulta GSI vs LSI.
- Recurre a
Query, nunca aScan. Todo el diseño existe para que puedas hacerQuerya una partición. Recurrir a unScanfiltrado para "encontrar los proyectos de un espacio de trabajo" tira el modelo por la borda y lee toda la tabla — la trampa cubierta en Query vs Scan.
Si genuinamente necesitas listar proyectos a través de espacios de trabajo (digamos,
todos los proyectos status = ACTIVE globalmente), la tabla base no puede responder a
eso — su partition key está acotada al espacio de trabajo.
Ese es trabajo para un índice secundario que re-particione los proyectos sobre un atributo distinto, no para remodelar esta relación.
Próximos pasos
Modela los patrones de acceso, codifica el padre en la partition key del hijo, y la
lectura uno-a-muchos es una sola Query. Construye y valida la condición de clave con el
Constructor de expresiones de DynamoDB.
Luego descarga DynoTable para cargar este esquema, navegar en vivo por la colección de elementos espacio-de-trabajo→proyectos, y confirmar que cada consulta hace exactamente una lectura.