Operaciones por lotes de DynamoDB: BatchGetItem y BatchWriteItem
Cuando necesitas leer o escribir muchos elementos a la vez, lanzar un GetItem o
PutItem por elemento significa un viaje de ida y vuelta por la red por elemento — lento,
y parlanchín. Las API por lotes de DynamoDB pliegan muchas operaciones de elemento en una
única petición: BatchGetItem para lecturas, BatchWriteItem para escrituras.
Son una victoria de rendimiento y latencia, no una garantía de consistencia — y esa distinción es donde la gente se quema. Un lote no es una transacción.
¿Qué son las operaciones por lotes de DynamoDB?
Las operaciones por lotes de DynamoDB pliegan muchas lecturas o escrituras de elementos en una única petición: BatchGetItem recupera hasta 100 elementos, BatchWriteItem hace put o delete de hasta 25, cada una con un tope de 16 MB. Ahorran viajes de ida y vuelta, no capacidad. Y algo crítico: un lote no es una transacción — los elementos tienen éxito o fallan de forma independiente, sin rollback.
BatchGetItem— recupera hasta 100 elementos (o 16 MB) en una o más tablas en una sola llamada.BatchWriteItem— hasta 25 operaciones de put/delete (o 16 MB) en una sola llamada. Sin actualizaciones — solo puts y deletes.- No atómico. Algunos elementos pueden tener éxito mientras otros fallan. No hay rollback.
- El fallo parcial es normal. Los elementos throttled vuelven en
UnprocessedItems/UnprocessedKeys— debes reintentarlos tú mismo, con backoff. - El mismo coste de capacidad que las llamadas individuales — agrupar en lotes ahorra viajes de ida y vuelta, no unidades de capacidad.
El problema: muchos elementos, un viaje de ida y vuelta
Digamos que gestionas un servicio de soporte. Un panel necesita cargar 50 tickets por ID para renderizar una cola; un trabajo nocturno archiva 1.000 tickets resueltos. Hacer eso de uno en uno son 50 (o 1.000) viajes de ida y vuelta secuenciales — la latencia se acumula y el trabajo se arrastra.
Agrupar en lotes los colapsa en un puñado de llamadas. La lectura de 50 tickets se
convierte en un único BatchGetItem; el trabajo de archivado se convierte en un flujo de
llamadas BatchWriteItem de 25 deletes cada una. Muchos menos viajes de ida y vuelta, los
mismos datos movidos.
Cómo funcionan las API por lotes
BatchGetItem toma un conjunto de claves primarias (en una o más tablas) y devuelve
los elementos coincidentes. Puedes pedir lecturas fuertemente consistentes por tabla.
Cualquier cosa que no pudo leer — normalmente porque la petición rozó un límite de
rendimiento — vuelve en UnprocessedKeys en lugar de hacer fallar la llamada entera.
BatchWriteItem toma una lista de operaciones PutRequest / DeleteRequest. Fíjate
en lo que falta: no hay update. Una escritura por lotes o bien reemplaza un elemento
entero (put) o lo elimina (delete) — para modificar atributos específicos todavía
necesitas UpdateItem. Los elementos que no pudo escribir vuelven en
UnprocessedItems.
El modelo mental clave: un lote es un paquete de operaciones independientes, cada una con éxito o fallo por su cuenta — no una unidad de todo-o-nada.
Los lotes no son transacciones
Esta es la trampa. Si el lote de tu trabajo de archivado alcanza un límite de rendimiento a mitad de camino, algunos tickets se eliminan y otros no — y DynamoDB no deshace los que sí pasaron. No hay rollback, ni aislamiento, ni "los 25 o ninguno".
Si necesitas semántica de todo-o-nada — "mueve el ticket a archivado y decrementa el
contador de tickets abiertos, o no hagas ninguna de las dos" — eso es
TransactWriteItems, no un lote. Las transacciones cuestan
más (cada operación se factura al doble) y se topan en 100 elementos, pero te dan la
atomicidad que los lotes deliberadamente no dan.
Manejar los elementos no procesados
Un llamador de lotes correcto siempre comprueba el conjunto no procesado y lo
reintenta. DynamoDB devuelve UnprocessedItems/UnprocessedKeys siempre que la petición
en su conjunto fue aceptada pero algunos elementos no pudieron servirse — típicamente
throttling transitorio.
Reenvía solo los elementos no procesados, con backoff exponencial y jitter. Tratar un lote como dispara-y-olvida descarta escrituras en silencio — el tipo de bug que aflora meses después como datos faltantes.
Escrituras por lotes en DynoTable
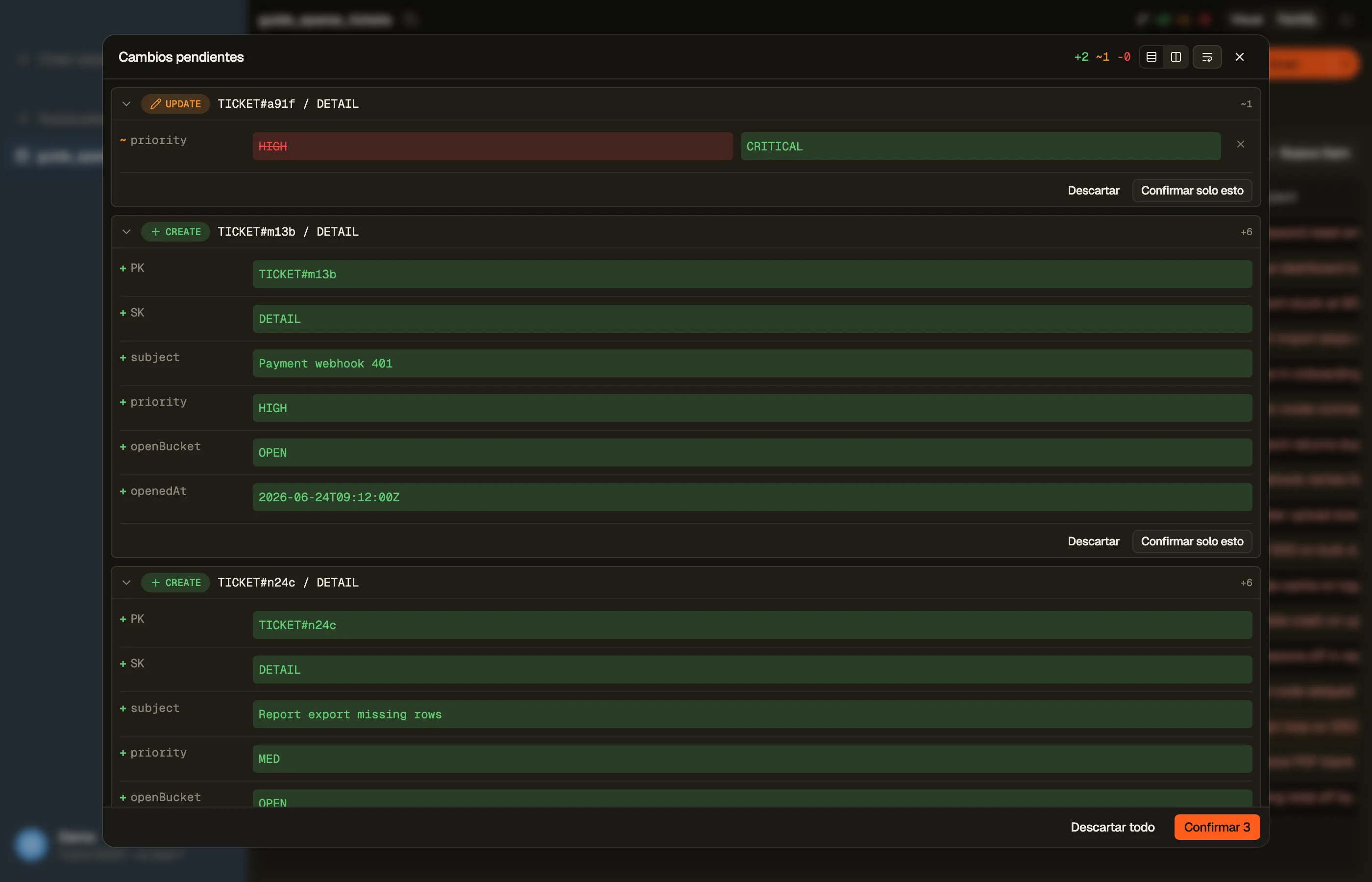
Estima primero lo que costará un trabajo masivo con la calculadora de precios de DynamoDB — un lote consume la misma capacidad que las escrituras individuales que agrupa, solo en menos peticiones.
En DynoTable, preparas tus ediciones localmente y las revisas antes de confirmarlas como escrituras por lotes eficientes — los cambios masivos a lo largo de muchas filas salen en peticiones agrupadas en lugar de una llamada a la API por cambio, con el reintento de elementos no procesados manejado por ti.



Trampas y próximos pasos
- Reintenta siempre
UnprocessedItems/UnprocessedKeyscon backoff — son esperados, no excepcionales. - Sin rollback en el fallo parcial. ¿Necesitas atomicidad? Usa transacciones.
- Sin actualizaciones en una escritura por lotes —
BatchWriteItemes solo put/delete; recurre aUpdateItempara cambiar atributos. - Atención a los topes por llamada — 25 escrituras / 100 lecturas / 16 MB. Pagina los trabajos más grandes; consulta paginación.
¿Quieres ejecutar lecturas y escrituras masivas sin programar el bucle de reintentos? Descarga DynoTable y edita tus tablas directamente.