Colecciones de elementos de DynamoDB
Una colección de elementos es el conjunto de todos los elementos de una tabla (o índice) que comparten el mismo valor de partition key. No es una función que activas — es una propiedad emergente de tu esquema de claves.
En el momento en que dos elementos llevan la misma partition key, forman una colección, y
esa colección se convierte en la unidad que DynamoDB te deja leer junta en una sola
Query.
Acierta con esto y tus lecturas vuelven en un solo viaje de ida y vuelta. Falla y te
quedas atascado con un Scan.
¿Qué es una colección de elementos de DynamoDB?
Una colección de elementos de DynamoDB es el conjunto de todos los elementos que comparten el mismo valor de partition key, almacenados juntos y ordenados por sort key. No es una función que activas — es una propiedad emergente de tu esquema de claves. La colección es la unidad que una sola Query lee de forma eficiente, mientras que un Scan recorre cada partición.
- Una colección no es más que "la misma partition key". Dos o más elementos con el mismo valor de partition key se almacenan juntos, ordenados por sort key.
- Es la unidad de una
Queryeficiente.Querylee una colección;Scanrecorre cada partición. Esa es toda la historia del rendimiento. - Sin sort key, no hay colección. Una tabla solo-con-partition-key tiene un elemento por clave — nada que coleccionar.
- Dos límites muerden: el techo de 10 GB por colección cuando existe un LSI, y las particiones calientes por claves de baja cardinalidad.
El problema: leer juntos elementos relacionados
Digamos que gestionas una flota de vehículos, cada uno transmitiendo telemetría —
velocidad, temperatura del refrigerante, nivel de combustible — cada pocos segundos. La
lectura dominante es "dame las lecturas recientes del vehículo V-7741".
Viniendo de SQL, indexarías una columna vehicle_id y dejarías que el planificador
hiciera el trabajo. Un almacén clave-valor simple no tiene ese lujo.
Trata cada lectura como un registro aislado, así que esa pregunta significa escanear toda la tabla y filtrar. Lento, caro y peor a medida que crece la flota.
La respuesta de DynamoDB es convertir "todas las lecturas de un vehículo" en algo agrupado físicamente y direccionable directamente. Esa agrupación es la colección de elementos.
Qué es realmente una colección
DynamoDB almacena los elementos en particiones, y enruta cada elemento a una partición aplicando un hash a su partition key. Por tanto, cada elemento con el mismo valor de partition key cae en la misma partición, ordenado por sort key.
La AWS Developer Guide lo nombra exactamente así: los elementos que comparten un valor de partition key son una colección de elementos, almacenados juntos y ordenados por sort key.
Esta es la misma idea que introdujo el artículo Dynamo de Amazon de 2007 — hashing consistente para asignar claves a nodos — extendida con una dimensión de orden para que los elementos relacionados queden adyacentes en disco.
Como están adyacentes y ordenados, DynamoDB devuelve una tirada contigua de ellos con una
sola búsqueda. Por eso Query es barato y Scan no lo es: Query lee una sola
colección; Scan recorre cada partición.
Para formar una colección necesitas una clave primaria compuesta — una partition key y una sort key. Una tabla indexada solo por partition key tiene exactamente un elemento por valor de clave, así que no hay nada que coleccionar.
Nuestro ejemplo desarrollado: vehículo → lecturas de telemetría
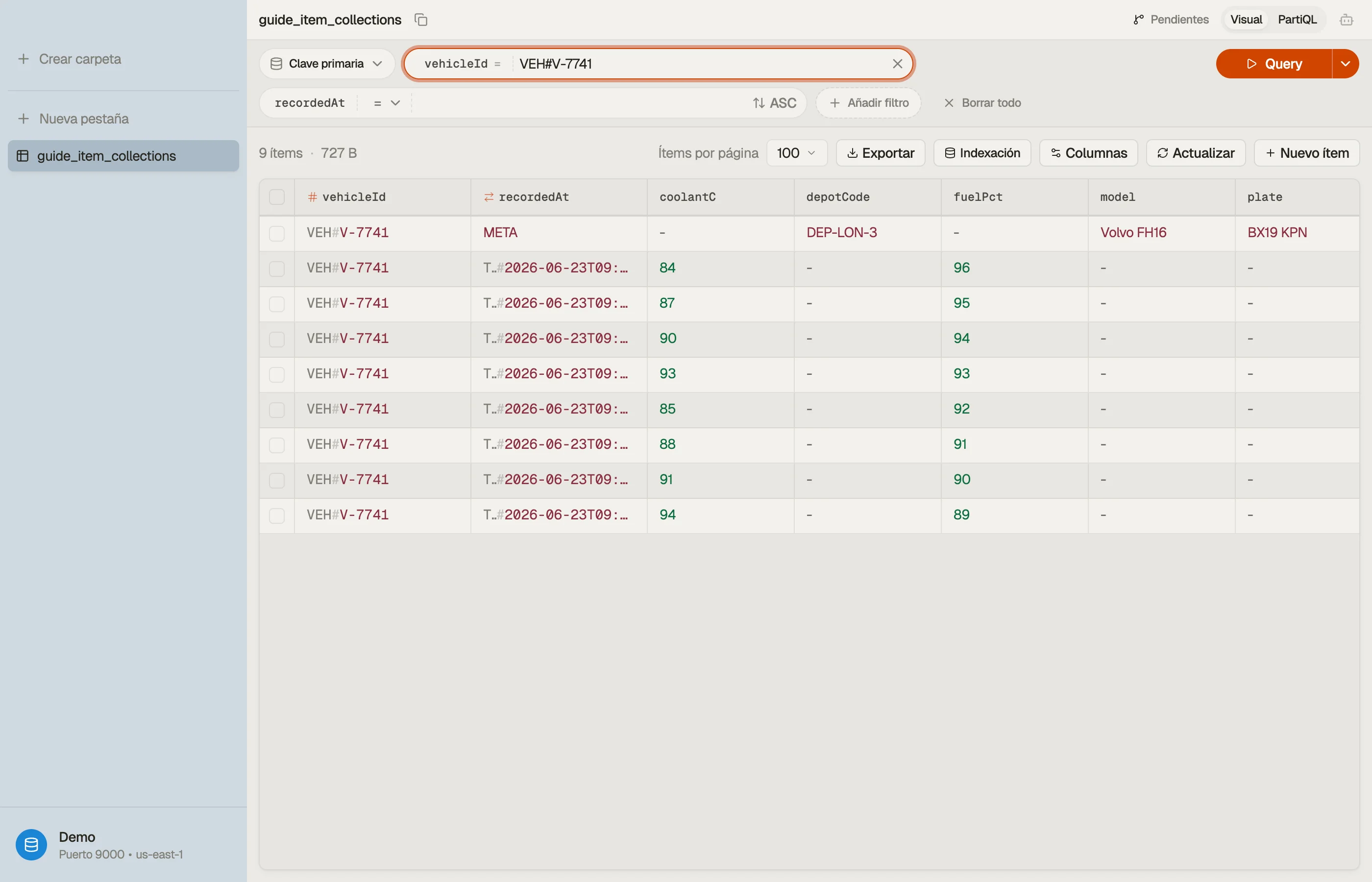
Modela el flujo de telemetría con una clave compuesta. La partition key identifica el vehículo; la sort key es la marca de tiempo de la lectura, lo que mantiene las lecturas ordenadas de la más nueva a la más antigua dentro de la colección.
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPctAquí viven dos colecciones — una por vehículo. El elemento META (metadatos del
vehículo) y todas las lecturas de V-7741 forman una colección; los elementos de
V-7742 forman otra.
Fíjate en el truco: da a los metadatos una sort key (META) que se ordene antes que
cualquier valor TS#..., y una sola Query sobre PK = "VEH#V-7741" devuelve el perfil
del vehículo y sus lecturas juntos.
Ese es el patrón padre-e-hijos en el corazón del diseño de tabla única.
Cada caja punteada es una colección de elementos: la misma partition key, elementos
ordenados por sort key. Una Query lee exactamente una caja.
Consultar una colección
Como la colección está ordenada por sort key, obtienes lecturas de rango gratis. Para sacar las lecturas registradas en una ventana de diez minutos de un vehículo, acotas la sort key:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest firstLa condición de clave te restringe a una colección (vehicleId = :v) y luego a una
porción contigua de ella (recordedAt BETWEEN ...). DynamoDB lee solo esos elementos y
te factura solo por ellos. ¿Solo quieres los metadatos? recordedAt = "META" trae el
único elemento META.
Construir estas condiciones de clave y expresiones de proyección a mano es engorroso. El
Constructor de expresiones de DynamoDB genera por ti
la KeyConditionExpression, los ExpressionAttributeNames y los
ExpressionAttributeValues, para que los detalles de palabras reservadas y marcadores de
posición no muerdan.
Colecciones en índices
Un índice secundario tiene su propio esquema de claves, así que forma sus propias colecciones de elementos.
Añade un índice secundario global indexado por depotCode (partición) y recordedAt
(orden), y "todas las lecturas del depósito DEP-LON-3, las más nuevas primero" se
convierte en una sola Query contra la colección de ese índice — una lectura que la
tabla base no puede servir.
Por eso importa el tipo de índice: gobierna qué colecciones puedes formar y cómo se comportan. Consulta GSI vs LSI para el compromiso.
Una distinción tajante: un índice secundario local (LSI) comparte la partition key de la tabla base, así que su colección está físicamente atada a la colección de elementos base — y ese vínculo crea un límite duro, abajo.
Los límites que muerden
Las colecciones de elementos son potentes, pero dos restricciones deciden cómo das forma a las claves:
- El límite de 10 GB del LSI. Cuando una tabla tiene uno o más índices secundarios
locales, una sola colección de elementos — los elementos base más sus proyecciones
de LSI de una partition key — no puede superar los 10 GB. Supéralo y las escrituras
que hacen crecer la colección empiezan a fallar con
ItemCollectionSizeLimitExceeded. Una tabla sin LSI no tiene ese techo por colección. Por eso exactamente un flujo ilimitado y siempre-creciente (telemetría que nunca para) encaja mal con un LSI: la colección solo crece. Un GSI obtiene sus propias particiones, así que esquiva el límite. - Particiones calientes. Una colección vive en una partición, y una sola partición
tiene un throughput finito. Si un vehículo (o un
depotCode) atrae una porción desproporcionadamente enorme del tráfico, puedes sobrecalentar esa partición incluso mientras la tabla en su conjunto está infraaprovisionada. La capacidad adaptativa — cubierta en los análisis profundos "Advanced Design Patterns for DynamoDB" de re:Invent de AWS — aísla y refuerza las claves calientes automáticamente, pero no puede rescatar una clave sin ninguna dispersión. Elige partition keys de alta cardinalidad para que el tráfico se distribuya entre muchas colecciones.
Velo en DynoTable
La forma más rápida de construir intuición sobre las colecciones es mirar una. En
DynoTable, consultar una partition key renderiza toda la colección como una lista
contigua y ordenada por sort key — el elemento META se sitúa justo delante de sus
lecturas con marca de tiempo, en pantalla, sin reconstrucción mental requerida.


Trampas y próximos pasos
- Sin sort key, no hay colección. Una tabla solo-con-partition-key no puede agrupar elementos relacionados. Si necesitas leer elementos juntos, necesitas una clave compuesta.
- No dejes que una colección de LSI crezca sin límite. Los flujos de solo-anexar pertenecen a un GSI (o a una partition key con buckets de tiempo), no a un LSI, por el techo de 10 GB.
- Distribuye tus partition keys. Una colección es solo tan escalable como la partición en la que vive. Las partition keys de baja cardinalidad crean puntos calientes.
- Recurre a
Query, no aScan. Las colecciones existen para que puedas leer elementos relacionados con una solaQuerydirigida; recurrir a unScantira esa ventaja por la borda — consulta Query vs Scan.
Bosqueja tu propio esquema de claves, ejecuta una Query contra una partition key real y
observa cómo la colección vuelve ordenada. Descarga DynoTable y explora las
colecciones de tus tablas directamente.