Cómo modelar datos en DynamoDB
En SQL modelas primero las entidades y relaciones, luego confías en que el planificador de consultas ensamble después lo que le pidas. DynamoDB invierte eso. Modelas las lecturas que ya sabes que vas a hacer, y las claves existen para servirlas.
No hay motor de joins ni planificador eligiendo una estrategia en tiempo de ejecución. Una Query lee una partición a lo largo de una clave, y ese es todo el contrato de rendimiento. Así que diseñas las claves para patrones de acceso conocidos, no para un esquema ordenado.
AWS lo dice sin rodeos en su guía de buenas prácticas: "no deberías empezar a diseñar tu esquema hasta que sepas las preguntas que tendrá que responder".
Esta guía recorre todo el proceso sobre un dominio: la tabla de clasificación de un juego multijugador que rastrea jugadores, las partidas que juegan y su ranking por temporada. Vamos de una lista de preguntas a un esquema de claves funcional.
¿Cómo se modelan los datos en DynamoDB?
Modela primero las lecturas, no las tablas. Enumera cada consulta que realiza la app y diseña una y una para que cada pregunta se resuelva en una sola Query o GetItem. Coubica los elementos que se leen juntos, recorre rangos en la sort key y añade un GSI para cualquier patrón de acceso que la tabla base no pueda servir.
- Lista primero las lecturas, no las tablas. Las preguntas son la especificación; los sustantivos son una distracción.
- Cada pregunta debe ser una
Queryo unGetItem. Si una pregunta necesita unScan, el modelo está mal. - Los elementos coubicados comparten una partition key; cualquier cosa por la que recorras un rango va en la sort key.
- Una pregunta que la tabla base no puede responder recibe un GSI — nunca un
Scancon un filtro.
Paso 1 — Encuadra el problema como preguntas, no como tablas
Resiste el impulso de dibujar tablas players, matches y scores. Ese instinto es el hábito de SQL, y aquí está mal. En su lugar, anota cada lectura que la app realmente realiza. Para nuestra tabla de clasificación:
- Traer el perfil de un jugador por id.
- Listar las partidas recientes de un jugador, las más nuevas primero.
- Mostrar los N mejores jugadores de una temporada dada, clasificados por rating.
- Buscar un jugador por su nombre público (p. ej. para una URL de perfil).
Estas cuatro preguntas — no los sustantivos — son la especificación. Cada una debe resolverse en una sola Query (o GetItem), porque esa es la única forma de acceso que DynamoDB sirve barato a escala.
Si una pregunta solo puede responderse escaneando la tabla, el modelo está mal, y lo notarás en latencia y coste — consulta Query vs Scan para entender por qué un Scan es el tiro al pie que hay que evitar.
Todo el método es un pipeline corto y ordenado que ejecutas una vez por dominio:
Cada paso de abajo se corresponde con una caja: lista, enumera, diseña claves, añade índices para el resto, luego valida.
Paso 2 — Entiende las primitivas con las que modelas
Una tabla tiene una partition key (PK) que elige en qué partición física vive un elemento, y una sort key (SK) opcional que ordena los elementos dentro de esa partición.
La documentación de componentes básicos de AWS llama al par la clave primaria del elemento. Una Query siempre apunta exactamente a un valor de PK y puede recorrer un rango o filtrar la SK — esas son todas las herramientas.
Este diseño de partición-única es lo que permite a DynamoDB entregar las lecturas predecibles, de baja latencia y particionadas horizontalmente descritas por primera vez en el artículo Dynamo de Amazon de 2007.
Dos consecuencias guían cada decisión de abajo:
- Los elementos que se leen juntos deberían compartir una partition key para que una sola
Querylos devuelva en una única petición facturada. - Cualquier cosa por la que quieras recorrer un rango (partidas recientes, mejores ratings) debe vivir en la sort key, porque es el único atributo que
Querypuede ordenar y acotar.
Cuando una pregunta necesita una forma de acceso distinta de la que ofrece la tabla base, añades un índice secundario global — una reproyección de la tabla bajo una PK/SK diferente.
(Para GSI frente a índice secundario local, consulta GSI vs LSI.)
Paso 3 — Diseña las claves, una pregunta a la vez
Usamos una sola tabla con atributos de clave genéricos y sobrecargados — el enfoque de tabla única — porque un jugador y sus partidas se leen juntos.
Inventa tus propios prefijos; aquí PLAYER#, MATCH# y SEASON# etiquetan el tipo de entidad dentro de claves por lo demás genéricas.
Las preguntas 1 y 2 (perfil + partidas recientes) comparten partición, así que ambas cuelgan de la misma PK:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" devuelve el perfil y cada partida en una lectura. Para el perfil solo, GetItem.
Para las partidas recientes, rangeId begins_with "MATCH#" con ScanIndexForward = false las recorre las más nuevas primero — la marca de tiempo en la sort key hace el ordenamiento gratis.
Las preguntas 3 y 4 no pueden responderse desde esa partición — pivotan sobre el rango de temporada y sobre el nombre, ninguno de los cuales es la PK base. Cada una recibe un GSI.
Añadimos dos atributos de índice genéricos, gsiPartition / gsiSort, y dejamos que cada elemento los rellene con lo que ese índice necesite:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Ahora hacer Query al índice de temporada WHERE gsiPartition = "SEASON#2026-Q2" con ScanIndexForward = false devuelve los jugadores clasificados por rating — esa es la tabla de clasificación.
Un segundo índice indexado por HANDLE#… resuelve un nombre público a un id de jugador en una lectura. Una tabla física, cuatro patrones de acceso de una sola Query.
Una nota sobre el relleno con ceros en
RATING#1842: DynamoDB ordena las sort keys lexicográficamente, no numéricamente, así que un rating debe rellenarse con ceros a un ancho fijo (RATING#01842) o9se ordenaría después de1000. Esta es una trampa clásica de modelado que conviene resolver desde el principio.
Paso 4 — Valida el modelo en DynoTable
Un esquema de claves solo se gana la confianza cuando ves una Query real devolver exactamente los elementos que esperabas y nada más.
Abre la tabla en DynoTable, ejecuta la consulta de la clasificación contra el índice de temporada y confirma que la partición vuelve clasificada y acotada — sin Scan, sin ordenamiento del lado del cliente.

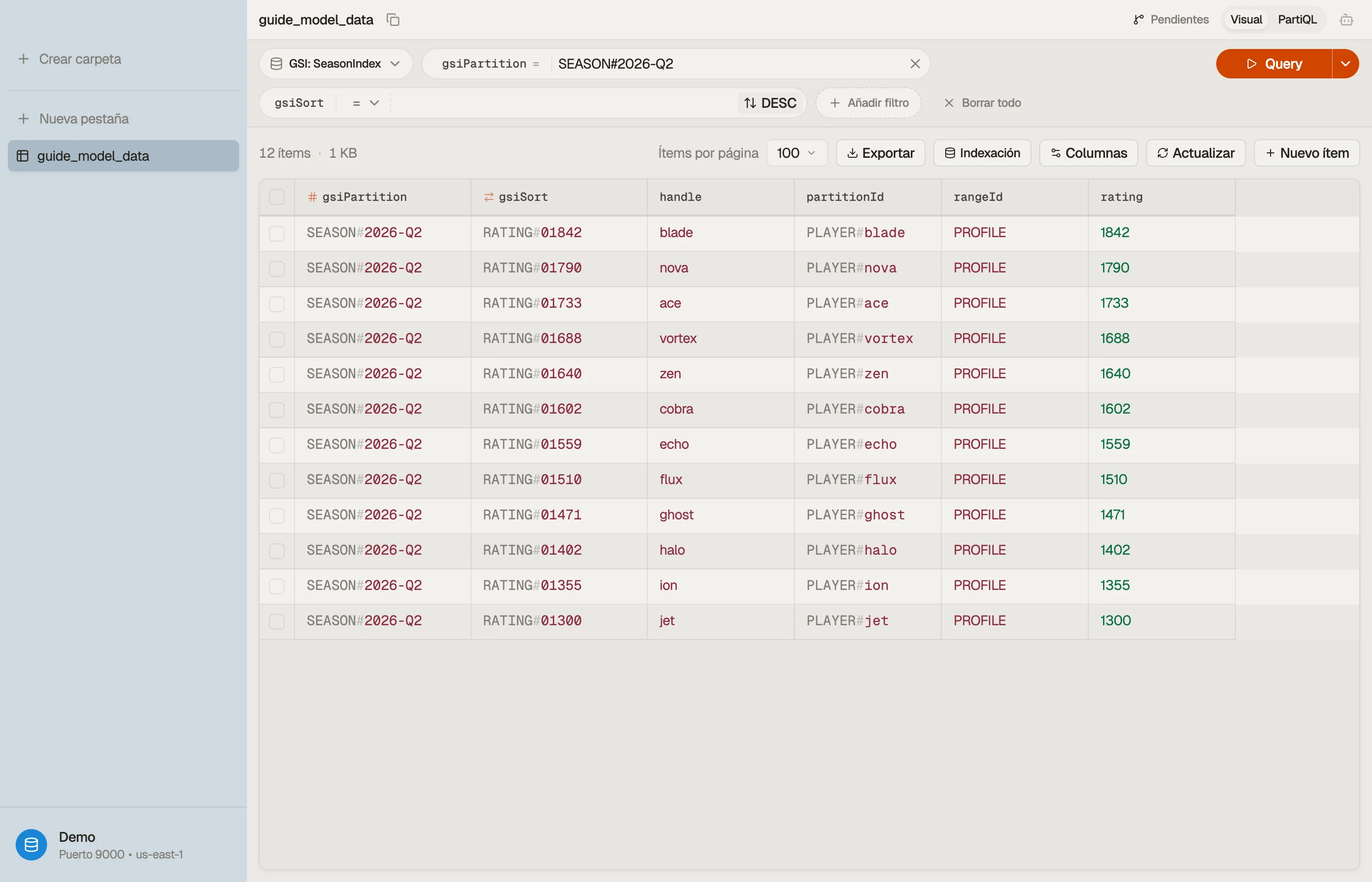


Cuando construyas las expresiones de condición para estas consultas — el begins_with, el gsiPartition = :p, el enlace del marcador :p — deja que el Constructor de expresiones de DynamoDB lo haga.
Genera la KeyConditionExpression, los ExpressionAttributeNames y los ExpressionAttributeValues, para que una palabra reservada como result o un marcador con una errata nunca rompa silenciosamente una lectura.
Paso 5 — Trampas y próximos pasos
Algunas trampas que comprobar antes de publicar el modelo:
- No modeles relaciones que nunca lees juntas. Un GSI por pregunta es barato; un GSI desperdiciado es un coste recurrente. Añade índices a partir de la lista de preguntas, no de forma especulativa.
- Vigila el calor de la partición. Si una PK (un jugador celebridad, una única temporada caliente) absorbe la mayor parte del tráfico, esa partición puede limitarse. Distribuye las escrituras con un fragmento de sufijo cuando una clave esté demostrablemente caliente — AWS lo cubre en diseño de partition keys.
- Rellena con ceros y usa ISO-8601 en todo lo numérico o temporal de una sort key, para que el ordenamiento lexicográfico coincida con el orden que quieres.
- Una pregunta nueva = una clave o índice nuevo, nunca un
Scan. Cuando aparezca después un patrón de acceso genuinamente nuevo, extiende las claves; no lo tapes con un filtro.
Modela primero las preguntas, diseña las claves para que cada una sea una Query, luego demuéstralo.
Prueba DynoTable para navegar por tu tabla, ejecutar estas consultas contra la tabla base y los GSI lado a lado, y ver cómo los patrones de acceso que diseñaste devuelven exactamente lo que planeaste.