Índices dispersos de DynamoDB
Un índice disperso es un índice secundario que contiene solo los elementos que llevan su atributo de clave — así un subconjunto pequeño y caliente de una tabla enorme se convierte en su propia colección prefiltrada y lista para consultar.
Tienes millones de filas pero la consulta que ejecutas todo el día toca una porción diminuta: los tickets de soporte abiertos, las facturas impagadas, las cuentas marcadas para revisión.
Filtrar esa porción aún escanea toda la tabla y te factura cada lectura. Un índice disperso hace que el índice en sí sea pequeño.
¿Qué es un índice disperso en DynamoDB?
Un índice disperso es un índice secundario que contiene solo los elementos que llevan su atributo de clave. Como DynamoDB omite cualquier elemento al que le falte esa clave, inventas una clave que solo los elementos deseados escriben — tickets abiertos, facturas impagadas — y el índice se convierte exactamente en ese subconjunto. Las consultas leen solo él, sin filtro, sin capacidad de lectura desperdiciada.
- Un índice secundario solo indexa los elementos que tienen su clave. Omite la clave en un elemento y nunca entra en el índice — sin marcador de posición, sin fila nula.
- Así que inventas una clave que solo los elementos deseados llevan. Escríbela en los elementos que consultas, quítala en el resto. El índice se convierte exactamente en ese subconjunto.
- La consulta lee solo el subconjunto, sin filtro. Su tamaño sigue al conjunto caliente pequeño, no al total de la tabla.
REMOVEes la palanca, no dejarlo en blanco. Una cadena vacía sigue siendo un valor y aún se indexa — debes eliminar el atributo.
El problema: filtrar no ahorra lecturas
Viniendo de SQL, asumes que una cláusula WHERE reduce el trabajo. La FilterExpression
de DynamoDB no lo hace. Se ejecuta después de que los elementos se leen, no antes.
Según la AWS Developer Guide, filtrar "no reduce la cantidad de capacidad de lectura consumida" — pagas por cada elemento examinado, luego tiras los que no coinciden.
Así que si 50 de tus 5 millones de tickets están abiertos, una Query/Scan filtrada lee
millones para entregarte esos 50.
Ese es el tiro al pie detrás de cada hilo de "por qué mi escaneo es tan caro"; query vs. scan tiene el panorama completo de costes.
Un índice disperso lo esquiva haciendo que el índice en sí sea pequeño.
Cómo funciona la dispersión
Un índice secundario solo indexa los elementos que realmente tienen los atributos de clave del índice.
La documentación de AWS sobre índices secundarios globales lo dice sin rodeos: "un índice secundario global solo contiene los elementos que tienen los atributos de clave definidos para ese índice".
Si falta la partition key (o sort key) del GSI en un elemento, DynamoDB simplemente no lo escribe en el índice. Sin marcador de posición, sin fila nula — el elemento está ausente.
Esa "ausencia por defecto" es todo el truco. No indexes un atributo status que cada
elemento lleva. Inventa un atributo que solo los elementos que quieres consultar lleven
en absoluto.
El índice se convierte entonces en una lista limpia de exactamente esos elementos, y una
Query contra él lee solo a ellos — sin filtro, sin capacidad desperdiciada.
Imagina la tabla base alimentando el índice, donde solo cruzan los elementos que llevan la clave:
Solo los elementos con clave (abiertos) se replican al índice; los elementos cerrados nunca entran en él.
Esta es la misma mentalidad de dar-forma-a-las-claves que el diseño de tabla única: las claves son herramientas que construyes para un patrón de acceso específico, no espejos fieles de tus datos.
Un ejemplo desarrollado: "solo tickets abiertos"
Toma una tabla de tickets de soporte. La tabla base está indexada para traer un ticket por id y listar los tickets de un cliente:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
A lo largo de la vida de la tabla, la mayoría de los tickets acaban cerrados. Pero la consulta del panel que tus agentes ejecutan todo el día es "muéstrame cada ticket abierto, el más antiguo primero" — unos cientos de filas escondidas dentro de millones.
El movimiento del índice disperso: define un GSI con partition key openBucket y sort key
openedAt, y escribe openBucket solo en los tickets abiertos. Establécelo cuando se
crea el ticket; REMOVE-lo cuando el ticket se resuelve.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← open: in the index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← open: in the index |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← closed: NOT in the index |
Los tickets a91f y b02c llevan openBucket, así que viven en el GSI. El ticket 77de
se resolvió y se le eliminó openBucket, así que cayó silenciosamente. El panel es ahora
una sola consulta barata:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstEsto lee solo los tickets abiertos. A medida que los tickets se cierran, el índice se encoge por sí solo — su tamaño sigue a la población abierta, nunca al total.
Un único valor de partición estático ("OPEN") está bien aquí precisamente porque el
conjunto se mantiene pequeño. Un conjunto abierto enorme necesitaría una partition key
fragmentada, pero el índice de "subconjunto pequeño" es exactamente donde un solo valor es
la decisión correcta.
La transición que lo hace funcionar es una sola update expression — eliminar el atributo cuando el ticket se resuelve.
Prototipa esa cláusula REMOVE y la condición de clave tipada para el lado de lectura en
el Constructor de expresiones de DynamoDB, en lugar
de ensamblar tú mismo a mano los ExpressionAttributeNames y los marcadores :val.
Hazlo en DynoTable
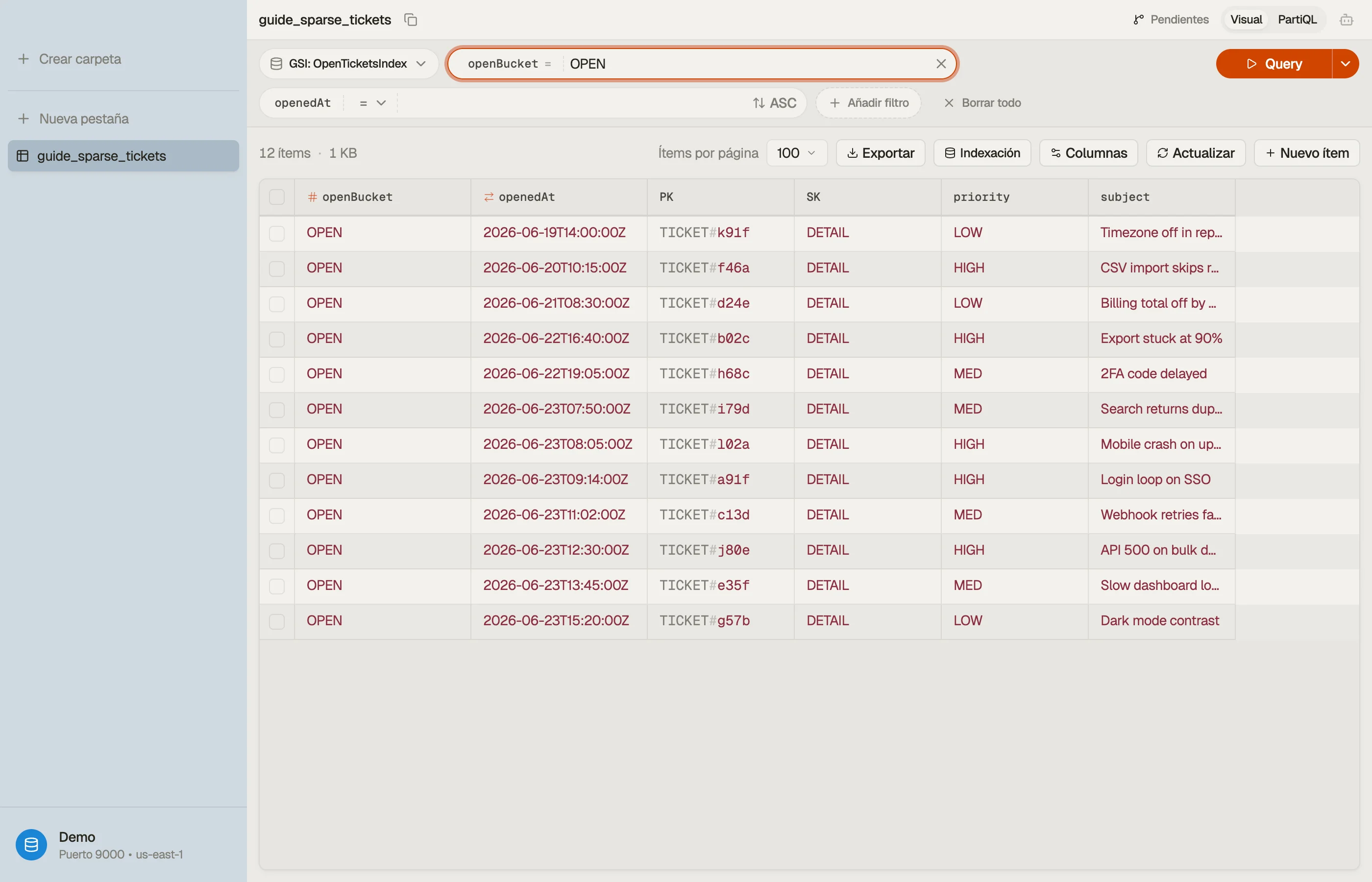
La parte difícil de un índice disperso no es la lectura — es ver qué elementos entraron en el índice frente a cuáles cayeron silenciosamente.
DynoTable te deja cambiar una vista de tabla a un índice secundario y ver exactamente el
subconjunto poblado. Así puedes confirmar que un ticket resuelto realmente abandonó
open-tickets-index en lugar de quedarse con una clave obsoleta.


Trampas y próximos pasos
Algunas cosas que vigilar:
- Elimina la clave, no la dejes en blanco. Una cadena vacía sigue siendo un valor, y
DynamoDB indexará un elemento cuyo
openBucketsea"". Para sacar un elemento del índice debes hacerREMOVEdel atributo — establecerlo a un valor falsy lo mantiene dentro. - El índice es eventualmente consistente. Los GSI se actualizan de forma asíncrona, así que un ticket recién-resuelto puede aparecer brevemente todavía — las lecturas de GSI solo soportan consistencia eventual. No confíes en él para "¿está este ticket abierto ahora mismo?".
- Atento a los atributos proyectados. Una
Querysobre el índice devuelve solo los atributos proyectados en él. Si el panel necesita el asunto y la prioridad, proyéctalos — o paga unGetItemextra por el elemento base completo. - Esto es una fortaleza del GSI, no del LSI. Los índices secundarios locales comparten la partition key de la tabla base y no pueden descartar elementos selectivamente de esta manera. GSI vs. LSI desglosa el compromiso.
Los índices dispersos son una de las ideas más antiguas del modelo. El artículo Dynamo de Amazon de 2007 original construyó el almacén en torno a servir patrones de acceso conocidos y de alto volumen de forma barata.
Un índice disperso es exactamente eso: da forma a las claves para que la consulta común no lea nada que no necesite.
Para construir e inspeccionar uno de verdad, descarga DynoTable, apúntalo a tu tabla y cambia la vista de datos a tu GSI disperso — observa cómo el subconjunto se actualiza a medida que los elementos ganan y pierden la clave del índice.