Relazioni uno-a-molti in DynamoDB
Un piano di controllo SaaS ha quasi sempre una gerarchia di contenimento: un
workspace possiede molti progetti. In SQL metteresti una chiave esterna
workspace_id sulla tabella dei progetti e faresti un JOIN.
DynamoDB non ha join né chiavi esterne, quindi la relazione deve vivere nel
key schema stesso. Fatto bene, "carica un workspace e ogni progetto al suo
interno" diventa una singola Query invece di una lettura più una scansione di
follow-up.
Come si modella una relazione uno-a-molti in DynamoDB?
Assegna al genitore e a tutti i suoi figli la stessa così da condividere un'unica , poi differenziali con la sort key. DynamoDB non ha join né chiavi esterne, quindi la relazione vive nel key schema stesso. Caricare un genitore più tutti i figli diventa così una singola Query invece di un join.
- Modella le letture, non le entità. La relazione uno-a-molti esiste solo per servire "elenca i progetti di un workspace" — modella le chiavi attorno a quella query.
- Codifica il genitore nella partition key del figlio. Dai al workspace e a tutti i suoi progetti lo stesso valore di partition key così da farli atterrare in un'unica item collection.
- Allora la lettura dell'elenco è una sola
Query. Il genitore più un numero arbitrario di figli tornano in una singola chiamata fatturata — niente join, niente secondo round trip. - Attenzione alla hot partition. Un singolo tenant enorme concentra tutto il suo traffico su una partizione; un workspace gigantesco potrebbe richiedere una chiave con sharding e una lettura fan-out.
Prima l'access pattern
Il modeling in DynamoDB è access-pattern-first, non entity-first — la stessa disciplina dietro il single-table design. Prima di scegliere una chiave, scrivi le letture che l'app emette davvero:
- Ottieni le impostazioni di un workspace.
- Elenca ogni progetto in un workspace, dal più recente.
- Ottieni un progetto specifico per id.
La relazione "un workspace, molti progetti" conta solo per via della lettura #2. Se non avessi mai bisogno di elencare insieme i progetti di un workspace, non modelleresti affatto la relazione — memorizzeresti i progetti in modo indipendente.
Quindi la domanda non è mai "come rappresento uno-a-molti?" in astratto. È "quali query deve servire questa relazione?" Rispondi a questo, poi modella le chiavi attorno.
Perché una chiave esterna non aiuta qui
In DynamoDB ogni GetItem e Query punta a una partition key, e il servizio
calcola l'hash di quella chiave per individuare la partizione che contiene
l'item.
AWS lo dice direttamente nella documentazione Core Components: il valore della partition key è l'input di una funzione hash interna che decide dove risiedono i dati.
Quel posizionamento basato su hash è l'eredità del paper originale del 2007 Dynamo: Amazon's Highly Available Key-value Store, dove l'hashing consistente distribuisce le chiavi tra i nodi.
Un semplice attributo workspace_id su un item progetto è invisibile a quel
meccanismo — DynamoDB non può "seguirlo".
Per recuperare item correlati in una sola richiesta, l'identità del genitore deve
essere codificata nella partition key del progetto, così che tutti gli item
di un workspace facciano hash sulla stessa partizione e una sola Query possa
spazzarli via.
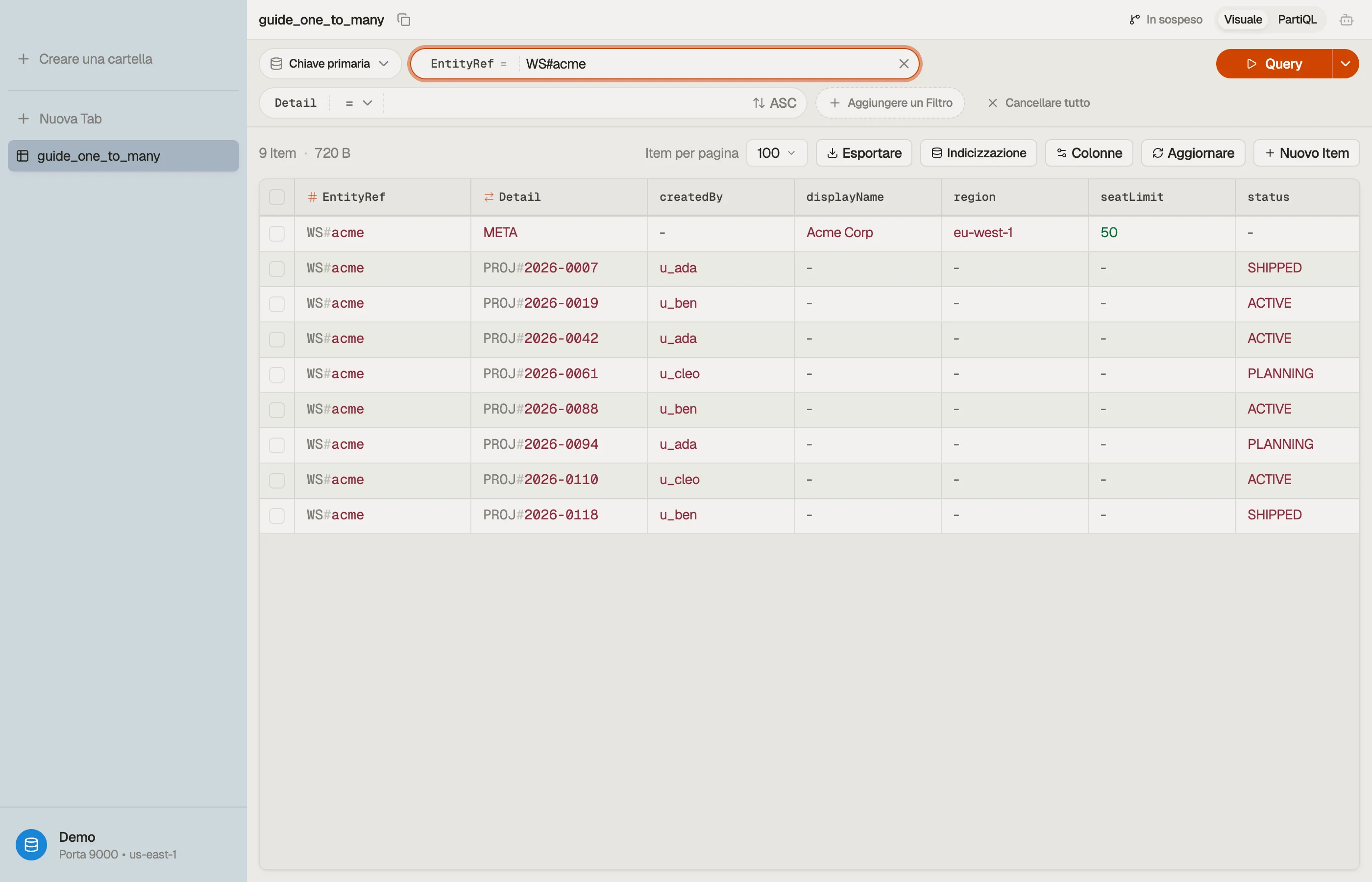
Esempio pratico: workspace e progetti
Usa un key schema generico e sovraccaricato. Chiama la partition key EntityRef
e la sort key Detail. L'identità del workspace va in EntityRef per sia
l'item workspace sia ogni progetto sotto di esso:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
Il workspace e tutti i suoi progetti condividono EntityRef = "WS#acme", quindi
formano un'unica item collection che vive insieme su una partizione.
La sort key Detail li separa: META è il record del workspace, e ogni progetto
porta un prefisso PROJ# con un id ordinato nel tempo e con zero-padding, così i
progetti si ordinano naturalmente.
Visivamente, il genitore e i suoi figli si impilano dentro una partizione, ordinati per sort key:
Una sola Query su EntityRef = "WS#acme" spazza l'intera pila — il genitore
più ogni figlio — in una singola lettura.
Ora i tre access pattern collassano ciascuno in una sola chiamata:
- Impostazioni del workspace —
GetItem(EntityRef="WS#acme", Detail="META"). - Elenca i progetti dal più recente —
Query(EntityRef="WS#acme")conDetail begins_with "PROJ#", eseguita in ordine decrescente (ScanIndexForward = false). - Un progetto —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
La seconda è tutto il punto: il genitore e un numero arbitrario di figli tornano
in una sola Query fatturata, niente join e niente secondo round trip. È la
mossa che non puoi fare con un attributo chiave esterna e uno Scan.
Scrivere a mano quella condizione begins_with è scomodo — la sintassi della
key-condition e della projection-expression morde.
Il DynamoDB Expression Builder genera la
KeyConditionExpression, le mappe di placeholder #name/:value e uno snippet
SDK pronto all'uso, così non devi combattere con la grammatica:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Ispeziona l'item collection in DynoTable
Il vantaggio di questo layout è visivo: ogni riga che condivide un EntityRef è
il workspace più i suoi figli, l'uno accanto all'altro.
DynoTable li raggruppa così che tu veda la relazione uno-a-molti come un unico blocco contiguo invece di doverla indovinare tra tabelle separate.


Trappole e la forma alternativa
Alcune cose a cui fare attenzione:
- Hot partition. Ogni item di un workspace vive su una sola partizione,
quindi un singolo tenant molto grande o molto attivo concentra il traffico. Il
comportamento di capacità adattiva
descritto da AWS assorbe uno sbilanciamento moderato, ma un workspace con
milioni di progetti potrebbe richiedere una chiave con sharding (es.
WS#acme#01 … #10) e una lettura fan-out. - Dimensione dell'item collection. Con un local secondary index, l'item collection di una singola partizione è limitata a 10 GB; senza un LSI non c'è tale limite. Se stai valutando i tipi di indice qui, vedi GSI vs LSI.
- Affidati a
Query, mai aScan. Tutto il design esiste così da poter fareQuerysu una partizione. Ripiegare su unoScanfiltrato per "trovare i progetti di un workspace" butta via il modello e legge l'intera tabella — la trappola trattata in Query vs Scan.
Se hai davvero bisogno di elencare i progetti tra workspace (diciamo, tutti i
progetti con status = ACTIVE globalmente), la tabella base non può rispondere —
la sua partition key è limitata al workspace.
Quello è un lavoro per un secondary index che ri-partiziona i progetti su un attributo diverso, non per rimodellare questa relazione.
Prossimi passi
Modella gli access pattern, codifica il genitore nella partition key del figlio,
e la lettura uno-a-molti è una singola Query. Costruisci e convalida la key
condition con il DynamoDB Expression Builder.
Poi scarica DynoTable per caricare questo schema, sfogliare dal vivo l'item collection workspace→progetti e confermare che ogni query faccia esattamente una lettura.