Come modellare i dati in DynamoDB
In SQL modelli prima entità e relazioni, poi ti fidi che il query planner assembli in seguito qualunque cosa chiedi. DynamoDB ribalta tutto. Modelli le letture che già sai che farai, e le chiavi esistono per servirle.
Non c'è motore di join né planner che sceglie una strategia a runtime. Una Query
legge una partizione lungo una chiave, ed è l'intero contratto di prestazioni.
Quindi progetti le chiavi per access pattern noti, non per uno schema ordinato.
AWS lo dice chiaramente nella sua guida alle best practice: "non dovresti iniziare a progettare il tuo schema finché non conosci le domande a cui dovrà rispondere".
Questa guida percorre l'intero processo su un dominio: una classifica di gioco multiplayer che traccia giocatori, le partite che giocano e il loro posizionamento per stagione. Passiamo da un elenco di domande a un key schema funzionante.
Come si modellano i dati in DynamoDB?
Modella prima le letture, non le tabelle. Elenca ogni query che l'app esegue, poi progetta una partition key e una sort key affinché ogni domanda si risolva in una singola Query o GetItem. Co-localizza gli item letti insieme, usa la sort key per i range, e aggiungi una GSI per ogni access pattern che la tabella base non riesce a servire.
- Elenca prima le letture, non le tabelle. Le domande sono la specifica; i sostantivi sono una distrazione.
- Ogni domanda deve essere una
Queryo unGetItem. Se una domanda richiede unoScan, il modello è sbagliato. - Gli item co-locati condividono una partition key; tutto ciò su cui spazi per intervalli va nella sort key.
- Una domanda a cui la tabella base non può rispondere ottiene una GSI — mai
uno
Scancon un filtro.
Passo 1 — Inquadra il problema come domande, non tabelle
Resisti all'impulso di disegnare le tabelle players, matches e scores.
Quell'istinto è l'abitudine SQL, e qui è sbagliato. Scrivi invece ogni lettura che
l'app esegue davvero. Per la nostra classifica:
- Recupera il profilo di un giocatore per id.
- Elenca le partite recenti di un giocatore, dalla più recente.
- Mostra i top N giocatori per una data stagione, ordinati per rating.
- Cerca un giocatore tramite il suo handle pubblico (es. per un URL di profilo).
Queste quattro domande — non i sostantivi — sono la specifica. Ognuna deve
risolversi in una singola Query (o GetItem), perché è l'unica forma di
accesso che DynamoDB serve a basso costo su larga scala.
Se una domanda può ricevere risposta solo scansionando la tabella, il modello è
sbagliato, e lo sentirai in latenza e costo — vedi Query vs Scan
per cui uno Scan è il footgun da evitare.
L'intero metodo è una pipeline breve e ordinata che esegui una volta per dominio:
Ogni passo qui sotto mappa su un riquadro: elenca, enumera, progetta le chiavi, aggiungi indici per il resto, poi convalida.
Passo 2 — Comprendi le primitive con cui modelli
Una tabella ha una partition key (PK) che sceglie su quale partizione fisica vive un item, e una sort key (SK) opzionale che ordina gli item all'interno di quella partizione.
La documentazione core-components di AWS
chiama la coppia la chiave primaria dell'item. Una Query punta sempre a
esattamente un valore di PK e può fare range-scan o filtrare la SK — è tutto il
toolkit.
Questo design a singola partizione è ciò che permette a DynamoDB di offrire le letture prevedibili, a bassa latenza e partizionate orizzontalmente descritte per la prima volta nel paper Amazon Dynamo del 2007.
Due conseguenze guidano ogni decisione qui sotto:
- Gli item letti insieme dovrebbero condividere una partition key così che
una sola
Queryli restituisca in una singola richiesta fatturata. - Tutto ciò su cui vuoi spaziare per intervalli (partite recenti, top rating)
deve vivere nella sort key, perché è l'unico attributo che
Querypuò ordinare e limitare.
Quando una domanda richiede una forma di accesso diversa da quella che la tabella base offre, aggiungi una Global Secondary Index — una ri-proiezione della tabella sotto una diversa PK/SK.
(Per GSI rispetto a Local Secondary Index, vedi GSI vs LSI.)
Passo 3 — Progetta le chiavi, una domanda alla volta
Usiamo una tabella singola con attributi chiave generici e sovraccaricati — l'approccio single-table — perché un giocatore e le sue partite sono letti insieme.
Inventa i tuoi prefissi; qui PLAYER#, MATCH# e SEASON# etichettano il tipo
di entità dentro chiavi altrimenti generiche.
Le domande 1 e 2 (profilo + partite recenti) condividono una partizione, quindi entrambe pendono dalla stessa PK:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" restituisce il profilo e ogni partita in una
lettura. Per il solo profilo, GetItem.
Per le partite recenti, rangeId begins_with "MATCH#" con
ScanIndexForward = false le percorre dalla più recente — il timestamp nella sort
key fa l'ordinamento gratis.
Le domande 3 e 4 non possono ricevere risposta da quella partizione — ruotano sul rank di stagione e sull'handle, nessuno dei quali è la PK base. Ognuna ottiene una GSI.
Aggiungiamo due attributi indice generici, gsiPartition / gsiSort, e lasciamo
che ogni item li popoli con qualunque cosa serva a quell'indice:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Ora Query sull'indice di stagione WHERE gsiPartition = "SEASON#2026-Q2" con
ScanIndexForward = false restituisce i giocatori ordinati per rating — quella è
la classifica.
Un secondo indice con chiave su HANDLE#… risolve un handle pubblico in un id
giocatore in una lettura. Una tabella fisica, quattro access pattern a singola
Query.
Una nota sullo zero-padding di
RATING#1842: DynamoDB ordina le sort key lessicograficamente, non numericamente, quindi un rating va riempito con zeri a una larghezza fissa (RATING#01842) o9si ordinerebbe dopo1000. È una classica trappola di modellazione che vale la pena impostare bene fin dall'inizio.
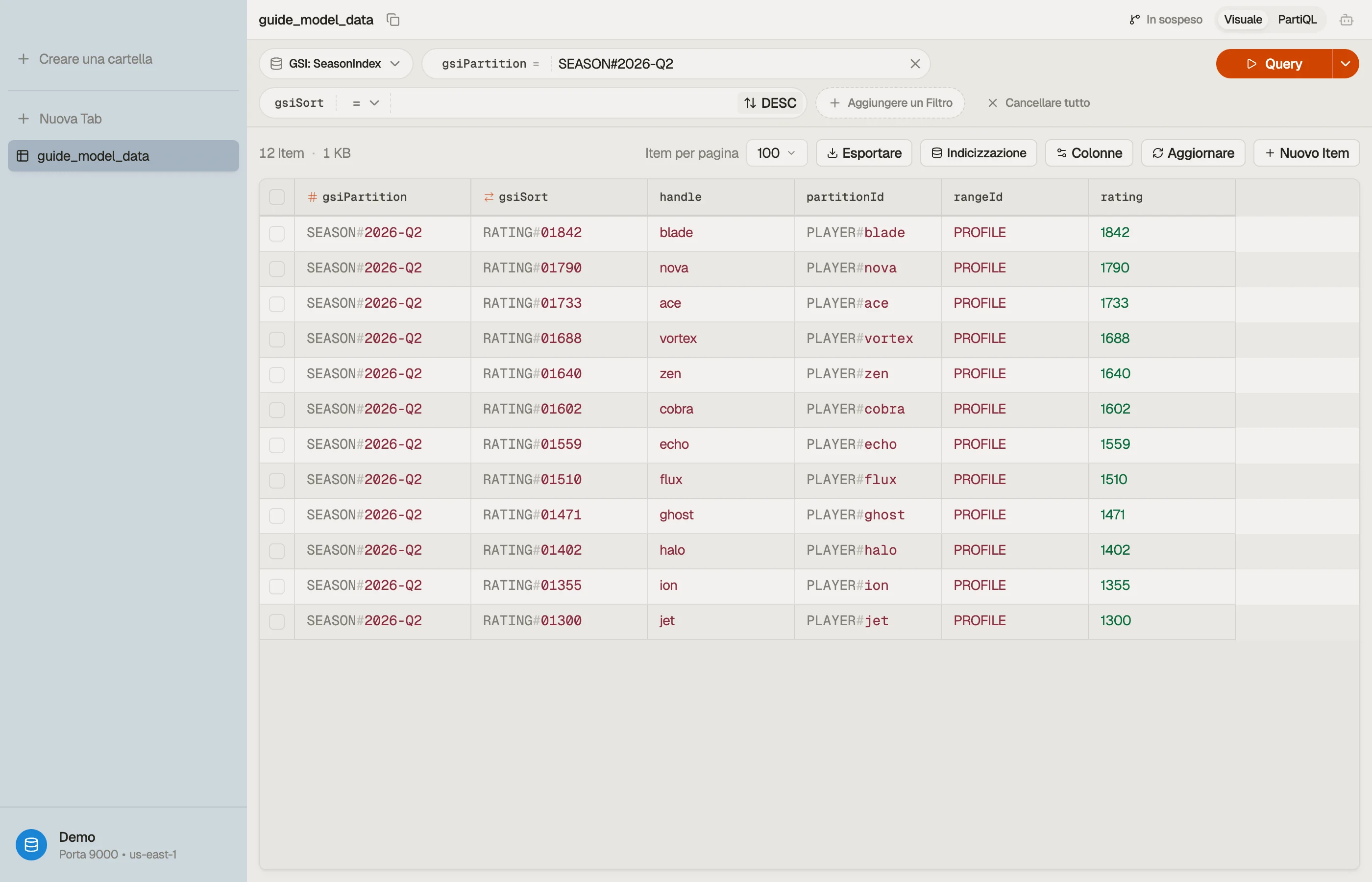
Passo 4 — Convalida il modello in DynoTable
Un key schema si guadagna fiducia solo quando guardi una Query reale
restituire esattamente gli item che ti aspettavi e nient'altro.
Apri la tabella in DynoTable, esegui la query della classifica contro l'indice di
stagione e conferma che la partizione torni ordinata e limitata — niente Scan,
niente ordinamento lato client.


Quando costruisci le condition expression per queste query — il begins_with, il
gsiPartition = :p, il binding del placeholder :p — lascia fare al
DynamoDB Expression Builder.
Genera la KeyConditionExpression, gli ExpressionAttributeNames e gli
ExpressionAttributeValues, così una parola riservata come result o un
placeholder con un typo non rompe mai silenziosamente una lettura.
Passo 5 — Trappole e prossimi passi
Alcune trappole da controllare prima di spedire il modello:
- Non modellare relazioni che non leggi mai insieme. Una GSI per domanda è economica; una GSI sprecata è un costo ricorrente. Aggiungi indici dall'elenco delle domande, non in modo speculativo.
- Attenzione al calore della partizione. Se una PK (un giocatore famoso, una singola stagione calda) assorbe la maggior parte del traffico, quella partizione può andare in throttling. Distribuisci le scritture con uno shard di suffisso quando una chiave è dimostrabilmente calda — AWS lo tratta sotto partition-key design.
- Riempi con zeri e usa ISO-8601 per tutto ciò che è numerico o temporale in una sort key, così che l'ordinamento lessicografico corrisponda all'ordine che intendi.
- Una nuova domanda = una nuova chiave o indice, mai uno
Scan. Quando in seguito compare un access pattern davvero nuovo, estendi le chiavi; non rattopparlo con un filtro.
Modella prima le domande, progetta le chiavi così che ognuna sia una Query, poi
dimostralo.
Prova DynoTable per sfogliare la tua tabella, eseguire queste query contro la tabella base e le GSI fianco a fianco, e guardare gli access pattern che hai progettato restituire esattamente ciò che avevi pianificato.