Reference count in DynamoDB
Un reference count è un numero che memorizzi su un item genitore che traccia quanti item figli puntano a esso — like su un post, membri in un workspace, risposte a un commento. Lo mantieni perché contare i figli a ogni lettura è troppo costoso.
Come si mantiene un conteggio in DynamoDB?
Memorizza il totale corrente come numero sull'item genitore e aggiornalo nella stessa scrittura che crea il figlio. Una fa atterrare entrambi o nessuno, e una condizione sulla scrittura del figlio impedisce ai retry di contare due volte — così un singolo GetItem restituisce un conteggio accurato.
- Non contare i figli in lettura. Una
Queryper contare i like paga per ogni item like che scansiona. Memorizza il totale sul post e leggi un solo item. - Mantieni il conteggio dove viene scritto il figlio, non dopo. Incrementalo nella stessa operazione che crea il figlio così che i due non divergano mai.
- Usa una transazione quando la scrittura e l'incremento toccano item diversi.
Un like è un item, il conteggio vive su un altro —
TransactWriteItemsfa atterrare entrambi o nessuno. - Il footgun è il doppio conteggio. Un like riprovato o duplicato che riesegue l'incremento gonfia il numero. Proteggi la scrittura del figlio con una condizione.
Perché contare affatto
Venendo da SQL, non memorizzeresti mai un conteggio di like — faresti
SELECT COUNT(*) FROM likes WHERE post_id = ? e lasceresti che un index lo
rendesse economico. DynamoDB non ha un COUNT(*) che salti la lettura degli item.
Una Query sui like di un post legge — e fattura — ogni item like in quella
partizione, anche se vuoi solo il numero. Su un post virale sono migliaia di RCU
per rispondere a "quanti like?" Quello è il footgun di lettura per uccidere il
quale esistono i reference count.
Quindi denormalizzi: memorizzi il totale corrente sul post stesso. Leggere il
conteggio diventa un singolo GetItem. Il costo è che ora sei tu a doverlo tenere
accurato.
Modella gli item
Due tipi di item condividono una partizione così che il post e i suoi like stiano in un'unica item collection. Chiavi inventate:
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
L'attributo likeTally sull'item META è il reference count. Ogni item LIKE#
è un figlio. Mettere entrambi sotto PK = "POST#a91f" significa che una singola
Query può recuperare il post e chi l'ha messo like insieme quando vuoi
effettivamente la lista.
Incrementa il conteggio in modo atomico
DynamoDB incrementa un numero con una update expression ADD (o SET x = x + :n)
— questo è un atomic counter: DynamoDB applica il delta lato server senza che
tu legga prima il valore corrente, così gli incrementi concorrenti non si
calpestano a vicenda.
(AWS: atomic counter)
Il problema: mettere like a un post sono due scritture su due item — crea
l'item LIKE# e aggiunge 1 a likeTally su META. Se il like atterra ma
l'incremento fallisce, il conteggio è sbagliato per sempre. Servono entrambi o
nessuno.
È ciò che TransactWriteItems garantisce — tutto-o-niente su più item, e annulla
l'intera transazione se un qualsiasi item viene modificato in modo concorrente
(AWS: pessimistic locking con le transazioni):
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Il Put e l'Update vengono committati insieme. Se uno dei due fallisce,
DynamoDB fa il rollback di entrambi e restituisce una
TransactionCanceledException.
Proteggiti dal doppio conteggio
Il vero bug non è un like scritto a metà — la transazione lo previene. È lo
stesso utente che mette like due volte, o un retry del client che rigioca la
richiesta. Ogni replay aggiunge un altro 1, e likeTally deriva silenziosamente
sopra il conteggio reale.
La ConditionExpression: attribute_not_exists(SK) sul Put è la protezione. Se
l'item LIKE# di quell'utente esiste già, la condizione del Put fallisce,
l'intera transazione viene annullata e — cosa cruciale — l'ADD non viene mai
eseguito. Un like per utente, imposto dalla chiave.
Costruisci e copia queste update e condition expression — con i giusti
ExpressionAttributeValues e la protezione attribute_not_exists —
nell'Expression Builder per DynamoDB invece
di assemblare il JSON a mano.
Rimuovere il like, e il costo
Rimuovere un like è l'immagine speculare: Delete dell'item LIKE# con
ConditionExpression: attribute_exists(SK), e ADD likeTally :minusOne nella
stessa transazione. La condizione impedisce a un doppio unlike di spingere il
conteggio in negativo.
Conosci il prezzo. Una scrittura transazionale costa 2 WCU per item per item fino a 1 KB — una per preparare, una per committare — contro 1 WCU per una scrittura normale. Un like sono due item, quindi ogni like è circa quattro WCU. Economico per azione, ma vale la pena saperlo prima che un post di una celebrità prenda una tempesta di like.
Vedilo in DynoTable
Quando sospetti che un conteggio sia derivato, vuoi confrontare il likeTally
memorizzato con il numero effettivo di figli LIKE# — senza eseguire una query
di conteggio in produzione.

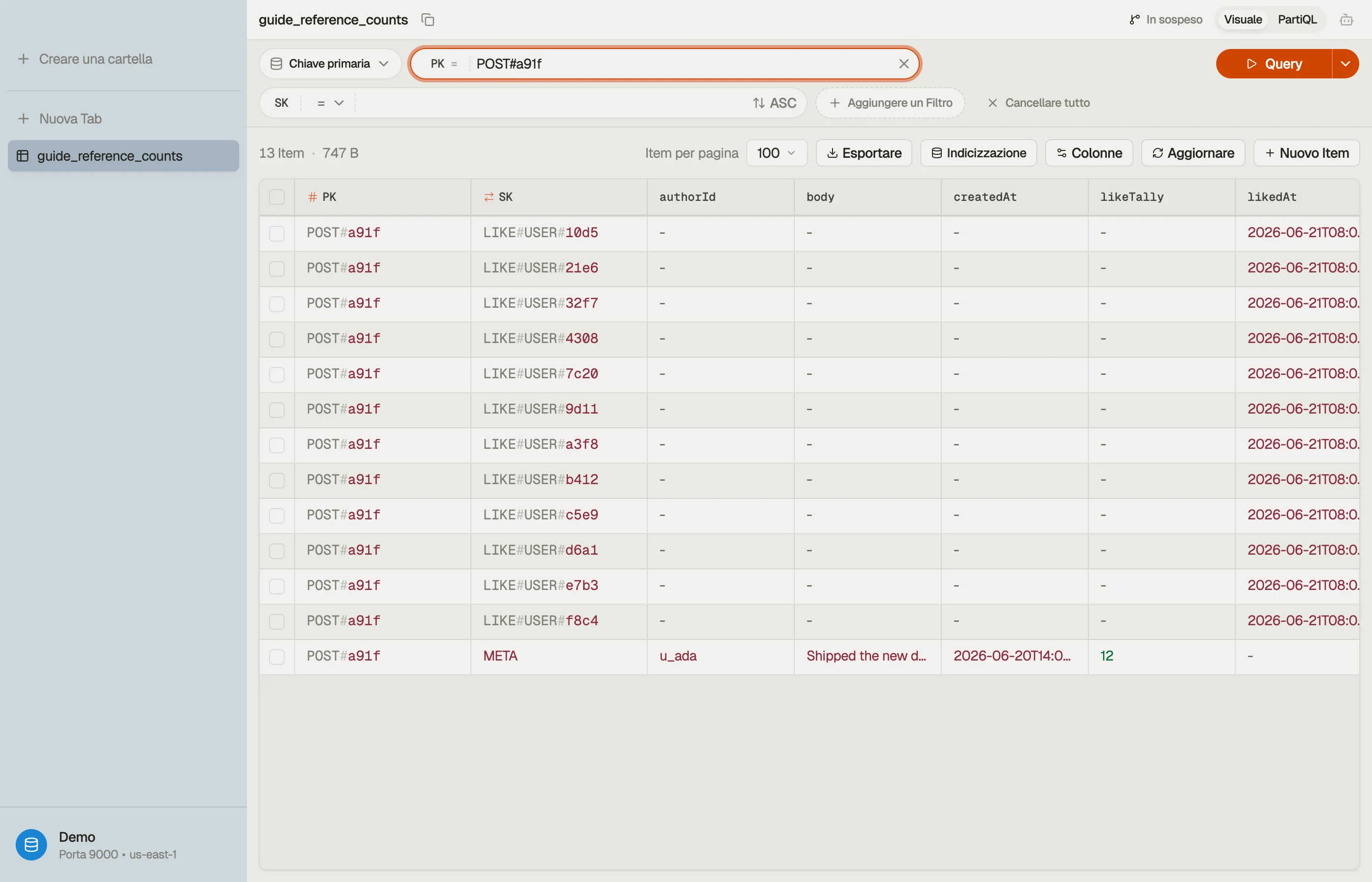

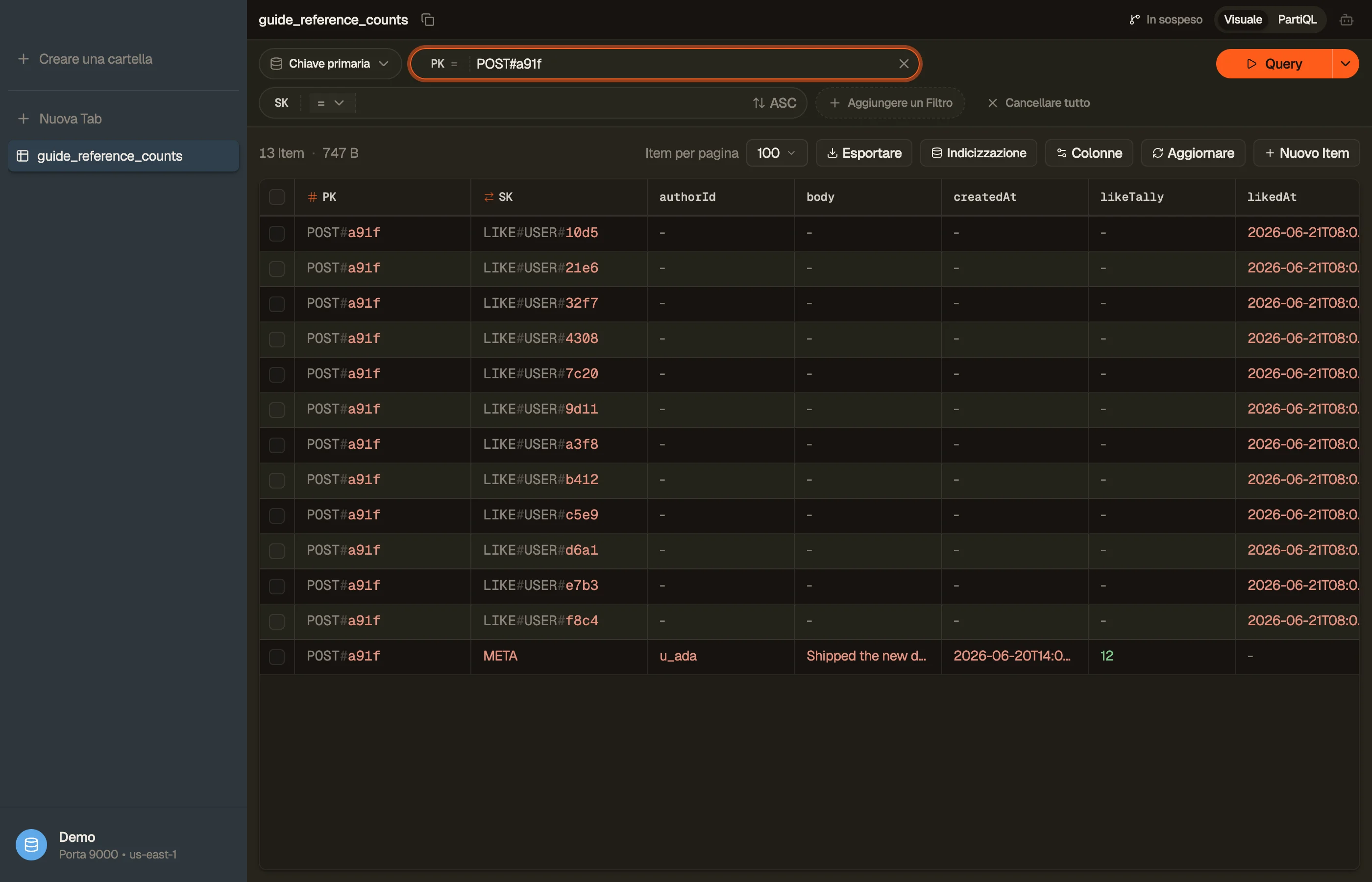
Per una vera riconciliazione su un insieme limitato di post — "quali conteggi non
corrispondono ai conteggi dei loro figli?" — la SQL Workbench di DynoTable esegue
il GROUP BY e la join lato client sulle righe che hai caricato, cosa che PartiQL
puro non può esprimere.
Insidie e prossimi passi
- Non mantenere il conteggio fuori banda (un Lambda che ricontano di notte). È un cerotto su un percorso di scrittura che avrebbe dovuto essere transazionale fin dall'inizio.
- Attento alle hot partition. Un singolo post enormemente popolare concentra ogni like — e ogni incremento del conteggio — su un'unica partition key. Il conteggio è corretto; la partizione può comunque andare in throttling.
- Riconcilia di rado, ripara chirurgicamente. La deriva dovrebbe essere quasi nulla se ogni mutazione è condizionata. Tratta una discrepanza come un bug da trovare, non come un numero da sovrascrivere.
Letture correlate: single-table design per capire perché il post e i like condividono una partizione, e Query vs Scan per capire perché contare i figli in lettura è il pattern che stai evitando.
Poi scarica DynoTable per ispezionare queste item collection e verificare i tuoi conteggi sulle tue tabelle.