Indici sparsi in DynamoDB
Un indice sparso è un secondary index che contiene solo gli item che portano il suo attributo chiave — così un piccolo sottoinsieme caldo di una tabella enorme diventa la sua collection pre-filtrata e pronta da interrogare.
Hai milioni di righe ma la query che esegui tutto il giorno tocca una fetta minuscola: i ticket di supporto aperti, le fatture non pagate, gli account segnalati per revisione.
Filtrare quella fetta scansiona comunque l'intera tabella e ti fattura ogni lettura. Un indice sparso rende invece l'indice stesso piccolo.
Cos'è un indice sparso in DynamoDB?
Un indice sparso è un secondary index che contiene solo gli item che portano il suo attributo chiave. Poiché DynamoDB salta qualsiasi item privo di quella chiave, si inventa una chiave che solo gli item desiderati scrivono — ticket aperti, fatture non pagate — e l'indice diventa esattamente quel sottoinsieme. Le query leggono solo quello, senza filtro e senza capacità di lettura sprecata.
- Un secondary index indicizza solo gli item che hanno la sua chiave. Ometti la chiave su un item e non entra mai nell'indice — nessun placeholder, nessuna riga null.
- Quindi inventi una chiave che solo gli item voluti portano. Scrivila sugli item che interroghi, rimuovila sul resto. L'indice diventa esattamente quel sottoinsieme.
- La query legge solo il sottoinsieme, senza filtro. La sua dimensione segue il piccolo insieme caldo, non il totale della tabella.
REMOVEè la leva, non lo svuotamento. Una stringa vuota è comunque un valore e viene comunque indicizzata — devi eliminare l'attributo.
Il problema: filtrare non risparmia letture
Venendo da SQL, dai per scontato che una clausola WHERE restringa il lavoro. La
FilterExpression di DynamoDB no. Viene eseguita dopo che gli item sono
letti, non prima.
Secondo la AWS Developer Guide, il filtraggio "non riduce la quantità di capacità di lettura consumata" — paghi ogni item esaminato, poi scarti i non corrispondenti.
Quindi se 50 dei tuoi 5 milioni di ticket sono aperti, una Query/Scan
filtrata legge attraverso milioni per consegnarti quei 50.
È il footgun dietro ogni thread "perché la mia scan è così costosa"; query vs. scan ha il quadro completo dei costi.
Un indice sparso lo aggira rendendo l'indice stesso piccolo.
Come funziona la sparsità
Un secondary index indicizza solo gli item che hanno effettivamente gli attributi chiave dell'indice.
La documentazione AWS sulle global secondary index lo dice chiaramente: "una global secondary index contiene solo gli item che hanno gli attributi chiave definiti per quell'indice".
Manca all'item la partition key (o la sort key) della GSI e DynamoDB semplicemente non la scrive sull'indice. Nessun placeholder, nessuna riga null — l'item è assente.
Quell'"assenza per default" è tutto il trucco. Non indicizzare un attributo
status che ogni item porta. Inventa un attributo che solo gli item che vuoi
interrogare portano del tutto.
L'indice diventa allora un elenco pulito esattamente di quegli item, e una Query
contro di esso legge solo quelli — senza filtro, senza capacità sprecata.
Immagina la tabella base che alimenta l'indice, dove solo gli item che portano la chiave attraversano:
Solo gli item con la chiave (aperti) si replicano nell'indice; gli item chiusi non vi entrano mai.
È la stessa mentalità di modellazione delle chiavi del single-table design: le chiavi sono strumenti che costruisci per uno specifico access pattern, non specchi fedeli dei tuoi dati.
Un esempio pratico: "solo i ticket aperti"
Prendi una tabella di ticket di supporto. La tabella base è strutturata per recuperare un ticket per id ed elencare i ticket di un cliente:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
Nel corso della vita della tabella, la maggior parte dei ticket finisce chiusa. Ma la query del dashboard che i tuoi agenti colpiscono tutto il giorno è "mostrami ogni ticket aperto, dal più vecchio" — qualche centinaio di righe nascoste tra milioni.
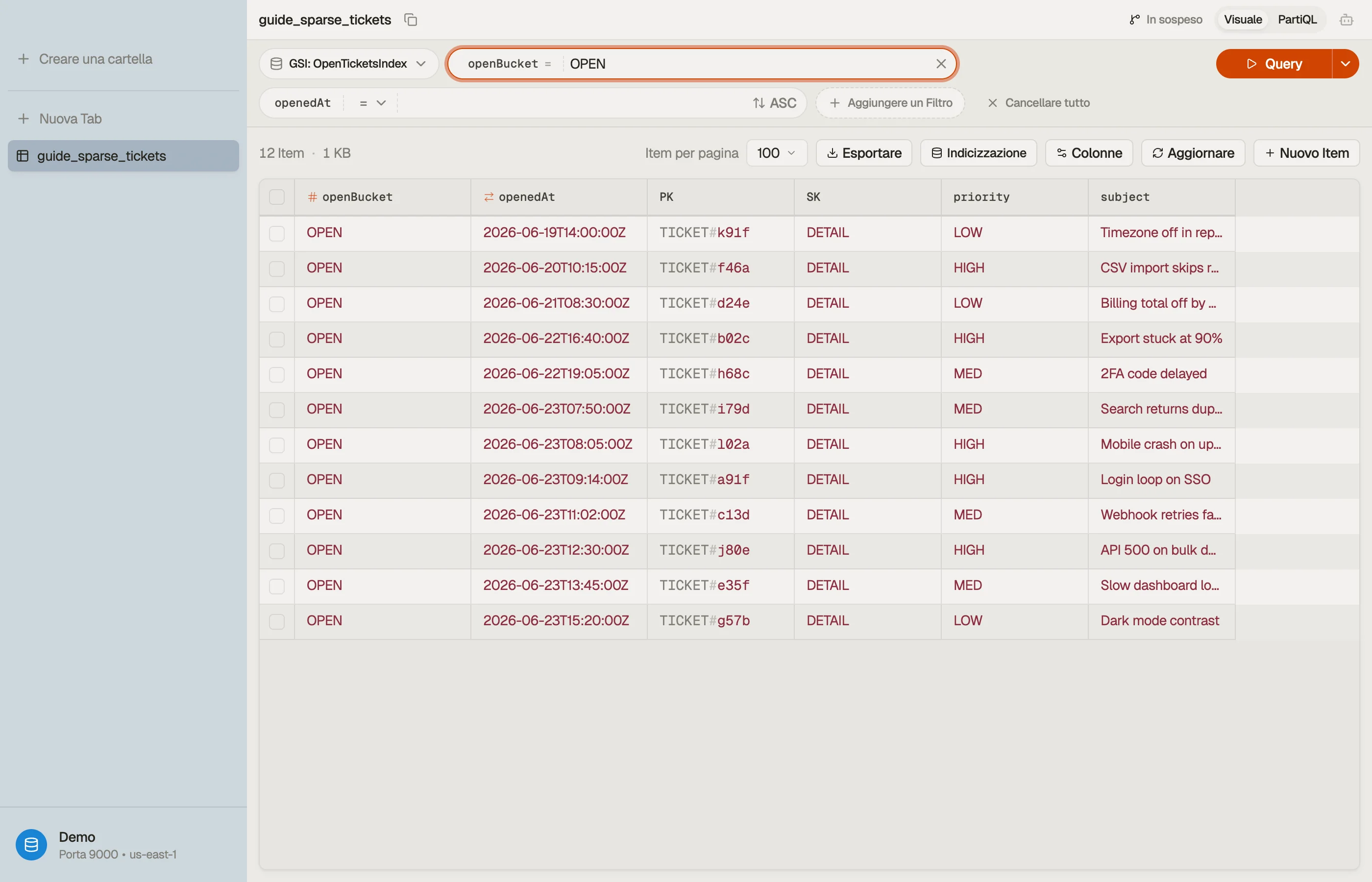
La mossa dell'indice sparso: definisci una GSI con partition key openBucket e
sort key openedAt, e scrivi openBucket solo sui ticket aperti. Impostalo
quando il ticket viene creato; fai REMOVE quando il ticket si risolve.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← aperto: nell'indice |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← aperto: nell'indice |
| TICKET#77de | DETAIL | (assente) | 2026-05-30T11:02:00Z | ← chiuso: NON nell'indice |
I ticket a91f e b02c portano openBucket, quindi vivono nella GSI. Il ticket
77de è stato risolto e gli è stato rimosso openBucket, quindi è uscito
silenziosamente. Il dashboard è ora una sola query economica:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstQuesto legge solo i ticket aperti. Man mano che i ticket si chiudono, l'indice si restringe da solo — la sua dimensione segue la popolazione aperta, mai il totale.
Un singolo valore di partizione statico ("OPEN") va bene qui proprio perché
l'insieme resta piccolo. Un insieme aperto enorme richiederebbe una partition key
con sharding, ma l'indice "piccolo sottoinsieme" è esattamente dove un solo valore
è la scelta giusta.
La transizione che lo fa funzionare è una singola update expression — rimuovere l'attributo quando il ticket si risolve.
Prototipa quella clausola REMOVE e la key condition tipizzata per il lato
lettura nel DynamoDB Expression Builder,
invece di assemblare a mano gli ExpressionAttributeNames e i placeholder
:val.
Fallo in DynoTable
La parte difficile di un indice sparso non è la lettura — è vedere quali item sono entrati nell'indice rispetto a quali sono usciti silenziosamente.
DynoTable ti permette di passare la vista tabella a un secondary index e vedere
esattamente il sottoinsieme popolato. Così puoi confermare che un ticket risolto
abbia davvero lasciato open-tickets-index invece di restare con una chiave
obsoleta.


Trappole e prossimi passi
Alcune cose a cui fare attenzione:
- Rimuovi la chiave, non svuotarla. Una stringa vuota è comunque un valore, e
DynamoDB indicizzerà un item il cui
openBucketè"". Per togliere un item dall'indice devi fareREMOVEdell'attributo — impostarlo a un valore falsy lo tiene dentro. - L'indice è eventualmente coerente. Le GSI si aggiornano in modo asincrono, quindi un ticket appena risolto può comparire ancora brevemente — le letture GSI supportano solo la coerenza eventuale. Non fidartene per "questo ticket è aperto in questo momento".
- Attenzione agli attributi proiettati. Una
Querysull'indice restituisce solo gli attributi proiettati in esso. Se il dashboard ha bisogno di subject e priority, proiettali — oppure paga unGetItemextra per l'item base completo. - Questa è una forza della GSI, non della LSI. Le local secondary index condividono la partition key della tabella base e non possono scartare item in modo selettivo così. GSI vs. LSI scompone il compromesso.
Gli indici sparsi sono una delle idee più antiche del modello. Il paper originale Amazon Dynamo del 2007 costruì lo store attorno al servire a basso costo access pattern noti e ad alto volume.
Un indice sparso è esattamente questo: modella le chiavi così che la query comune non legga nulla di cui non ha bisogno.
Per costruirne e ispezionarne uno sul serio, scarica DynoTable, puntalo alla tua tabella e passa la vista dati alla tua GSI sparsa — guarda il sottoinsieme aggiornarsi man mano che gli item guadagnano e perdono la chiave dell'indice.