Item collection in DynamoDB
Una item collection è l'insieme di tutti gli item in una tabella (o indice) che condividono lo stesso valore di partition key. Non è una funzionalità da attivare — è una proprietà emergente del tuo key schema.
Nel momento in cui due item portano la stessa partition key, formano una
collection, e quella collection diventa l'unità che DynamoDB ti permette di
leggere insieme in una singola Query.
Fai bene questo e le tue letture tornano in un solo round trip. Sbaglialo e resti
bloccato con uno Scan.
Cos'è una item collection in DynamoDB?
Una item collection in DynamoDB è l'insieme di tutti gli item che condividono lo stesso valore di partition key, memorizzati insieme e ordinati per sort key. Non è una funzionalità da attivare — è una proprietà emergente del tuo key schema. La collection è l'unità che una singola Query legge in modo efficiente, mentre uno Scan percorre ogni partizione.
- Una collection è semplicemente "stessa partition key". Due o più item con lo stesso valore di partition key sono memorizzati insieme, ordinati per sort key.
- È l'unità di una
Queryefficiente.Querylegge una collection;Scanpercorre ogni partizione. È tutta qui la storia delle prestazioni. - Niente sort key, niente collection. Una tabella con sola partition key contiene un item per chiave — niente da raccogliere.
- Due limiti mordono: il tetto di 10 GB per collection quando esiste una LSI, e le hot partition da chiavi a bassa cardinalità.
Il problema: leggere insieme item correlati
Diciamo che gestisci una flotta di veicoli, ognuno che trasmette telemetria —
velocità, temperatura del refrigerante, livello carburante — ogni pochi secondi.
La lettura dominante è "dammi le letture recenti del veicolo V-7741".
Venendo da SQL, indicizzeresti una colonna vehicle_id e lasceresti fare il
lavoro al planner. Un semplice key-value store non ha tale lusso.
Tratta ogni lettura come un record isolato, quindi quella domanda significa scansionare l'intera tabella e filtrare. Lento, costoso, e peggio man mano che la flotta cresce.
La risposta di DynamoDB è rendere "tutte le letture di un veicolo" una cosa raggruppata fisicamente e indirizzabile direttamente. Quel raggruppamento è l'item collection.
Cos'è davvero una collection
DynamoDB memorizza gli item in partizioni, e instrada ogni item a una partizione calcolando l'hash della sua partition key. Ogni item con lo stesso valore di partition key atterra quindi nella stessa partizione, ordinato per sort key.
La AWS Developer Guide lo nomina esattamente: gli item che condividono un valore di partition key sono una item collection, memorizzati insieme e ordinati per sort key.
È la stessa idea introdotta dal paper Amazon Dynamo del 2007 — hashing consistente per assegnare le chiavi ai nodi — estesa con una dimensione di ordinamento così che gli item correlati siano adiacenti su disco.
Poiché sono adiacenti e ordinati, DynamoDB restituisce un blocco contiguo di essi
con un solo seek. Ecco perché Query è economica e Scan no: Query legge una
singola collection; Scan percorre ogni partizione.
Per formare una collection ti serve una chiave primaria composta — una partition key e una sort key. Una tabella con la sola partition key ha esattamente un item per valore di chiave, quindi non c'è niente da raccogliere.
Il nostro esempio pratico: veicolo → letture di telemetria
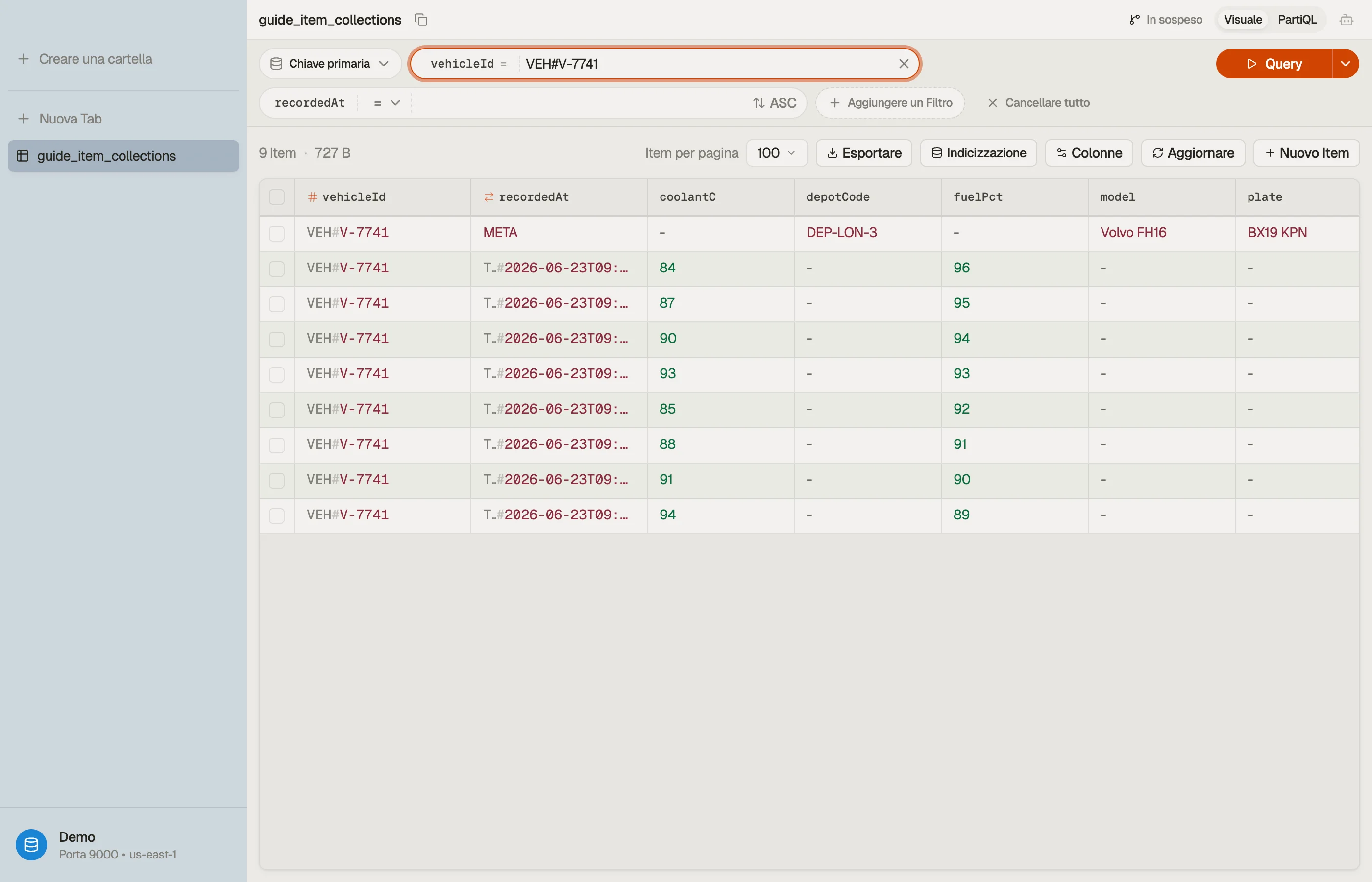
Modella lo stream di telemetria con una chiave composta. La partition key identifica il veicolo; la sort key è il timestamp della lettura, che mantiene le letture ordinate dalla più recente alla più vecchia all'interno della collection.
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPctQui vivono due collection — una per veicolo. L'item META (metadati del veicolo)
e tutte le letture di V-7741 formano una collection; gli item di V-7742 ne
formano un'altra.
Nota il trucco: dai ai metadati una sort key (META) che si ordina prima di
qualsiasi valore TS#..., e una singola Query su PK = "VEH#V-7741"
restituisce il profilo del veicolo e le sue letture insieme.
È il pattern genitore-e-figli al cuore del single-table design.
Ogni riquadro tratteggiato è una item collection: stessa partition key, item
ordinati per sort key. Una Query legge esattamente un riquadro.
Interrogare una collection
Poiché la collection è ordinata per sort key, ottieni gratuitamente le letture per intervallo. Per estrarre le letture registrate in una finestra di dieci minuti per un veicolo, limiti la sort key:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest firstLa key condition ti restringe a una collection (vehicleId = :v) e poi a una
fetta contigua di essa (recordedAt BETWEEN ...). DynamoDB legge solo quegli
item e ti fattura solo per essi. Vuoi solo i metadati? recordedAt = "META"
recupera il singolo item META.
Costruire a mano queste key condition e projection expression è scomodo. Il
DynamoDB Expression Builder genera per te la
KeyConditionExpression, gli ExpressionAttributeNames e gli
ExpressionAttributeValues, così i dettagli di parole riservate e placeholder non
mordono.
Collection sugli indici
Un secondary index ha il suo key schema, quindi forma le sue item collection.
Aggiungi una global secondary index con chiave su depotCode (partizione) e
recordedAt (ordinamento), e "tutte le letture dal deposito DEP-LON-3, dalla
più recente" diventa una singola Query contro la collection di quell'indice —
una lettura che la tabella base non può servire.
Ecco perché il tipo di indice conta: governa quali collection puoi formare e come si comportano. Vedi GSI vs LSI per il compromesso.
Una distinzione netta: una local secondary index (LSI) condivide la partition key della tabella base, quindi la sua collection è fisicamente legata alla item collection base — e quel legame crea un limite stringente, qui sotto.
I limiti che mordono
Le item collection sono potenti, ma due vincoli decidono come modelli le chiavi:
- Il limite di 10 GB della LSI. Quando una tabella ha una o più local
secondary index, una singola item collection — gli item base più le loro
proiezioni LSI per una partition key — non può superare i 10 GB. Superalo e
le scritture che fanno crescere la collection iniziano a fallire con
ItemCollectionSizeLimitExceeded. Una tabella senza LSI non ha tale tetto per collection. È esattamente per questo che uno stream illimitato e in continua crescita (telemetria che non si ferma mai) è una pessima scelta per una LSI: la collection cresce e basta. Una GSI ottiene le proprie partizioni, quindi aggira il limite. - Hot partition. Una collection vive in una partizione, e una singola
partizione ha throughput finito. Se un veicolo (o un
depotCode) attira una quota di traffico enormemente sproporzionata, puoi creare un hot spot su quella partizione anche mentre la tabella nel suo complesso è sotto-allocata. La capacità adattiva — trattata nei deep-dive di re:Invent "Advanced Design Patterns for DynamoDB" di AWS — isola e potenzia automaticamente le hot key, ma non può salvare una chiave senza alcuna distribuzione. Scegli partition key ad alta cardinalità così che il traffico si distribuisca su molte collection.
Vedila in DynoTable
Il modo più rapido per costruire intuizione sulle collection è guardarne una. In
DynoTable, interrogare una partition key rende l'intera collection come un elenco
contiguo, ordinato per sort key — l'item META sta proprio davanti alle sue
letture con timestamp, sullo schermo, senza alcuna ricostruzione mentale.


Trappole e prossimi passi
- Niente sort key, niente collection. Una tabella con la sola partition key non può raggruppare item correlati. Se devi leggere item insieme, ti serve una chiave composta.
- Non lasciare che una collection LSI cresca illimitata. Gli stream append-only appartengono a una GSI (o a una partition key suddivisa per intervalli temporali), non a una LSI, per via del tetto di 10 GB.
- Distribuisci le tue partition key. Una collection è scalabile solo quanto la partizione in cui vive. Partition key a bassa cardinalità creano hot spot.
- Affidati a
Query, non aScan. Le collection esistono così da poter leggere item correlati con unaQuerymirata; ripiegare su unoScanbutta via quel vantaggio — vedi Query vs Scan.
Abbozza il tuo key schema, esegui una Query contro una partition key reale e
guarda la collection tornare ordinata. Scarica DynoTable ed esplora
direttamente le collection delle tue tabelle.