Key overloading in DynamoDB
Venendo da SQL, una colonna significa una cosa per sempre: orders.created_at è sempre una
data, users.email è sempre un'email. Il key overloading butta via tutto questo. Dai
alla chiave di partizione e alla sort key nomi generici — pk, sk — e lasci che ogni tipo di Item
versi dentro un significato diverso. Una tabella, molte entità, una forma.
Cos'è il key overloading in DynamoDB?
Il key overloading consiste nel memorizzare molti tipi di entità in una sola tabella usando nomi di chiave generici come pk/sk, codificando il tipo nel valore (USER#u_3001, INVOICE#2026-0014). Il nome dell'attributo resta neutro, così utenti, fatture ed eventi condividono la stessa partizione; è il valore a portare il tipo, e un prefisso sulla sort key permette a una sola Query di estrarre ogni entità tramite begins_with.
- Nomi di chiave generici, valori tipizzati. Chiama le tue chiavi
pk/ske metti il tipo di entità nel valore:pk = "TENANT#acme",sk = "USER#u_3001". Il nome è muto; il valore porta il tipo. - È ciò che fa funzionare il single-table design. Senza overloading, una tabella condivisa
è solo un cassetto del disordine. Con esso, ogni entità sta in una partizione che puoi interrogare con
Query. begins_withè il guadagno. Un prefisso di tipo sulla sort key permette a una solaQuerydi estrarre un'intera entità, o una sua fetta, senzaScane senza filtro.- Il costo: leggibilità. Un dump grezzo di
pk/sknon ti dice nulla. Hai bisogno di un viewer che decodifichi i prefissi, altrimenti starai a strizzare gli occhi sulle stringhe.
Perché i nomi generici battono quelli reali
DynamoDB ha esattamente due attributi chiave per tabella, e una Query può puntare solo a una
singola chiave di partizione. Quindi se chiami la tua chiave userId, solo gli Item utente possono vivere in
quella tabella in modo pulito — tutto il resto deve fingere uno userId o spostarsi nella propria tabella.
L'overloading aggira tutto questo. Un nome neutro come pk non si impegna con nessuna entità,
così un utente, una fattura e un evento di audit possono condividere lo stesso attributo chiave e
la stessa tabella. Il valore, non il nome dell'attributo, dice cos'è l'Item.
Questa è la mossa che trasforma il single-table design da teoria in qualcosa che puoi davvero interrogare. La tabella condivisa è il contenitore; l'overloading è ciò che permette a entità distinte di coesistere al suo interno.
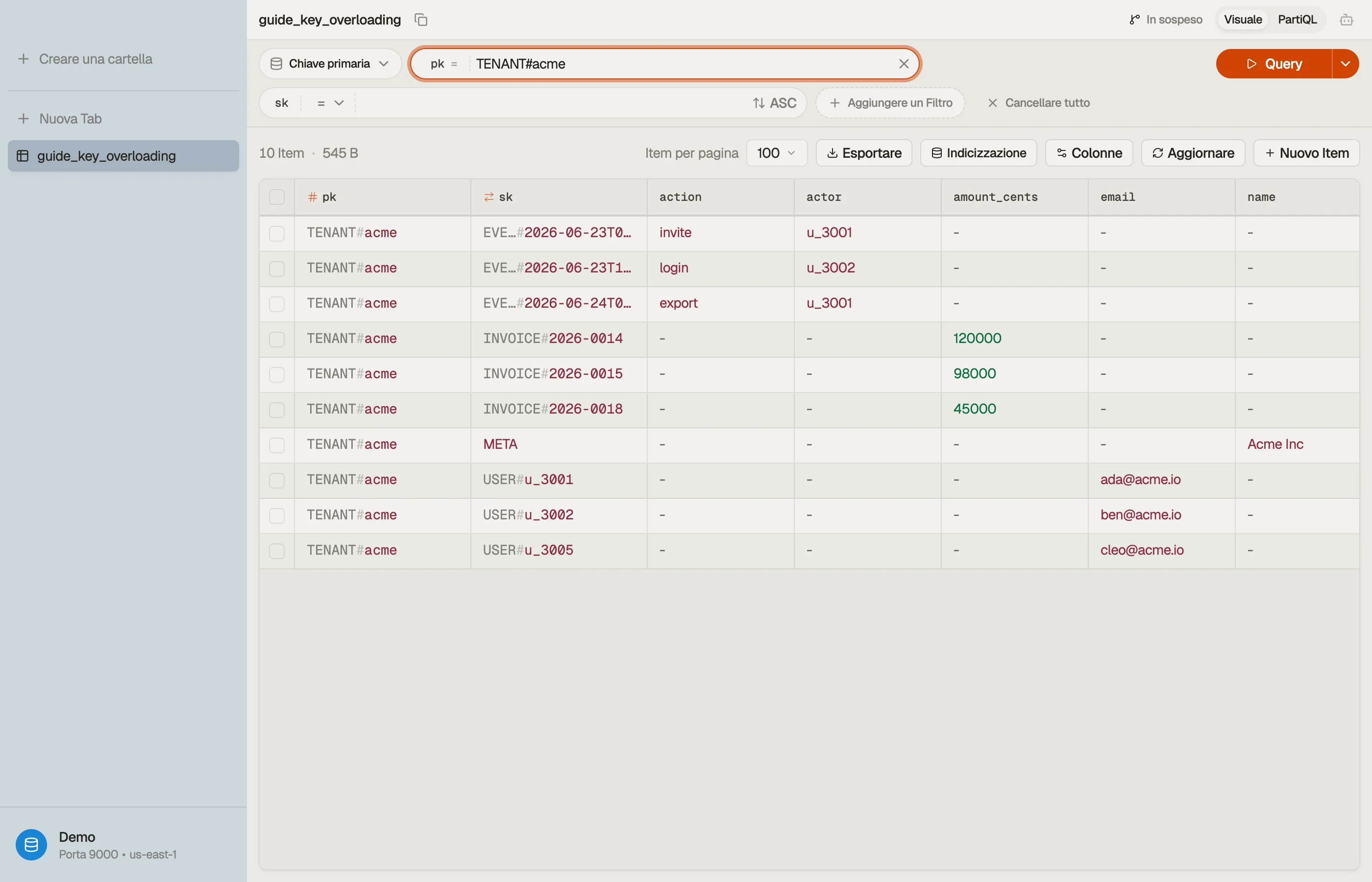
Un esempio multi-tenant
Diciamo che gestisci un prodotto SaaS di billing. Ogni tenant ha membri, fatture e un audit trail. Invece di tre tabelle, metti tutto in una e sovraccarica le chiavi:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
Ogni riga condivide pk = "TENANT#acme", quindi formano un'unica item collection — tutte
co-locate, tutte raggiungibili in una sola lettura di partizione.
Il prefisso della sort key fa il lavoro vero. Raggruppa le entità e le ordina.
Interroga la collection sovraccaricata
Poiché il tipo vive nel prefisso della sort key, begins_with affetta la partizione per
entità senza fare scan di nulla:
Query pk = "TENANT#acme" -- l'intero tenant, ogni tipo
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- solo i membri
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- solo le fatturePaghi solo per gli Item che la condizione abbina, non per l'intera partizione — l'
opposto di uno Scan filtrato, dove paghi per leggere righe
che poi butti via. AWS chiama questo una condition di chiave; gira sulle chiavi prima che
qualsiasi dato lasci la partizione.
Se costruisci quella condizione begins_with a mano, azzecca i tag di tipo — un USERS#
errante invece di USER# non restituisce nulla, silenziosamente. L'
expression builder genera la
KeyConditionExpression e la map ExpressionAttributeValues così i prefissi
corrispondono a ciò che hai davvero scritto.
Sovraccarica anche l'indice
Lo stesso trucco si applica a un GSI. Dagli nomi di chiave generici — gsi1pk, gsi1sk —
e lascia che ogni entità scriva ciò di cui ha bisogno. Un indice risponde poi a pattern che la
tabella base non può.
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
Ora Query gsi1 WHERE gsi1pk = "STATUS#open" elenca ogni fattura aperta su tutti i
tenant, ordinata per data di scadenza — una vista cross-partizione che le chiavi scoped per tenant
della tabella base non potrebbero mai servire. Un'entità diversa può riutilizzare gsi1 con il proprio
significato (diciamo gsi1pk = "ROLE#admin"), così un indice copre diverse letture. Ricorda solo che un
GSI è eventualmente coerente — le sue scritture sono in ritardo rispetto alla tabella base.
Fallo in DynoTable
Le chiavi sovraccaricate grezze sono ostili da leggere: INVOICE#2026-0015 e
EVENT#2026-06-23T09:12Z si confondono in un elenco piatto. Un viewer che raggruppa per
partizione e fa emergere i prefissi trasforma il cassetto del disordine di nuovo in entità.



Errori
- Scegli i delimitatori una volta e non cambiarli mai.
#è la convenzione. Mischiare#e:tra le entità rompebegins_within modi di cui nulla ti avverte. - Non sovraccaricare valori che richiedono aritmetica di range. Una sort key di
INVOICE#2026-0015si ordina lessicalmente, non numericamente — zero-padda gli id e usa date ISO-8601 così l'ordine delle stringhe corrisponde all'ordine che intendi. - Riserva il namespace dei prefissi. Due tipi di entità che iniziano entrambi con
USER(diciamoUSER#eUSERGROUP#) collideranno sottobegins_with(sk, "USER"). Rendi i prefissi non ambigui dal primo carattere. - Pianifica la lettura prima delle chiavi. L'overloading serve pattern di accesso che hai enumerato. Se non conosci ancora le tue letture, vedi prima single-table design — le chiavi sono a valle delle query.
Mappa una partizione, poi scarica DynoTable per navigare le tue
chiavi sovraccaricate e osservare una sola Query riportare indietro un intero tenant in una volta.