Strategie per le sort key di DynamoDB
Una chiave primaria DynamoDB è uno o due attributi: una partition key da sola, o una partition key più una sort key. La partition key decide quale partizione fisica contiene un item.
La sort key decide l'ordine degli item all'interno di quella partizione — e
quell'ordinamento è ciò che rende potente Query.
Scegli la sort key sbagliata e puoi comunque scrivere dati, ma perdi le letture per intervalli, l'ordinamento e diversi access pattern da un'unica collection.
Venendo da SQL ricorreresti a un ORDER BY o a un secondary index dopo il fatto.
In DynamoDB inforni l'ordine nella chiave fin dall'inizio, oppure non lo ottieni.
Come funzionano le sort key di DynamoDB?
Una sort key di DynamoDB ordina gli item all'interno di una partizione, così che Query possa effettuare letture per intervalli — >=, between, begins_with — invece di recuperare un item alla volta. L'ordinamento è byte-order sulla chiave codificata, quindi progettala (un timestamp ISO-8601, un numero riempito con zeri) in modo che il byte-order corrisponda all'ordine in cui vuoi leggere.
- La sort key è il tuo indice intra-partizione. Ordina la item collection su
disco, così che
Querypossa fare letture per intervalli (>=,between,begins_with) invece di un singoloGetItem. - L'ordinamento è byte-order sulla chiave codificata. Progetta la chiave così
che il byte-order eguagli l'ordine in cui vuoi leggere — un timestamp ISO-8601,
un numero riempito con zeri, mai un UUID grezzo o
6/23/2026. - Una sort key ben modellata serve molti access pattern. Una chiave composta
(
EVT#<timestamp>) è prefisso e intervallo insieme — nessuna GSI necessaria. - La direzione è gratis.
ScanIndexForward = falselegge dal più recente allo stesso costo; non memorizzare timestamp invertiti per fingerlo.
Perché la sort key è la leva
Senza una sort key, ogni item in una partizione è indirizzabile solo dalla sua
chiave primaria completa — un GetItem al meglio. Aggiungi una sort key e
DynamoDB memorizza gli item ordinati per essa all'interno della partizione,
cosa che sblocca Query.
Ciò significa condizioni per intervalli (>=, between), confronto di prefissi
(begins_with) e un flag ScanIndexForward per leggere in ordine crescente o
decrescente.
Secondo la AWS DynamoDB Developer Guide, tutti gli item che condividono una partition key formano una item collection, ordinata su disco dalla sort key.
Quindi la sort key non è solo un secondo identificatore. È l'indice contro cui interroghi all'interno di una partizione.
Quell'ordinamento è byte-order sulla sort key codificata: le stringhe si confrontano per byte UTF-8, i numeri si confrontano numericamente. Questo unico fatto guida quasi ogni strategia qui sotto.
Se vuoi che le query per intervalli significhino qualcosa, il byte-order deve corrispondere all'ordine in cui vuoi leggere.
Strategia 1: rendi la sort key ordinabile
L'errore più comune è una sort key che non è ordinata in modo significativo. Un UUID casuale ti dà unicità ma nessuna query per intervalli utile — "dammi gli ultimi 20" diventa impossibile perché il byte-order è arbitrario.
Codifica invece il valore su cui ordini e filtri dentro la sort key, in una rappresentazione il cui byte-order eguagli il suo ordine logico. Per i timestamp ciò significa un formato lessicograficamente ordinabile: una stringa ISO-8601 o un epoch riempito con zeri.
ISO-8601 è stato progettato così che il confronto tra stringhe eguagli il
confronto cronologico — esattamente ciò di cui ha bisogno una query per
intervalli. Evita formati come 6/23/2026; si ordinano male nel momento in cui il
mese cambia.
Se ordini su numeri (un contatore di versione, un punteggio), usa il tipo nativo
Number di DynamoDB invece di una stringa, così 42 si ordina dopo 9 invece
che prima.
Se un numero deve vivere dentro una sort key composta di tipo stringa, riempilo con zeri a una larghezza fissa.
Strategia 2: sort key composte per la gerarchia
Una sort key può codificare una gerarchia concatenando segmenti con un
delimitatore, più comunemente #. Una sola condizione begins_with seleziona
allora un intero sotto-albero:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") restituisce solo gli eventi di giugno; il più
ampio begins_with(SK, "EVENT#") li restituisce tutti.
L'ordine dei segmenti è una decisione di design. Da grezzo a fine (anno → mese → giorno) mantiene contigui gli item correlati, così una lettura per intervalli resta una query economica invece di una dispersione attraverso la partizione.
Strategia 3: controlla la direzione con ScanIndexForward
DynamoDB memorizza gli item in ordine crescente di sort key e li legge così
per default. Per leggere dal più recente — l'ordine naturale per un feed di
attività — imposta ScanIndexForward = false sulla Query.
Questo è un flag di lettura, non una decisione di schema: la stessa collection serve entrambe le direzioni allo stesso costo. Non invertire i tuoi timestamp (memorizzando un "reverse epoch") solo per ottenere letture decrescenti.
Una item collection, memorizzata una volta in ordine crescente, letta in entrambi i versi:
Stessi item, stessa partizione, stesso costo — cambia solo la direzione di lettura.
L'unica eccezione: se hai bisogno specificamente che l'ordine decrescente sia
anche l'ordine in cui avanza un indice sparso o un cursore di paginazione. A meno
di ciò, ScanIndexForward è la leva più semplice.
Esempio pratico: un log di audit per attore
Supponi di registrare eventi con timestamp prodotti da attori — utenti, servizi, chiavi API — in un prodotto SaaS, e di avere due letture:
- Lo stream di attività di un attore, dall'evento più recente.
- Gli eventi di un attore in una finestra temporale (es. "tutto tra i due deploy"), per un'indagine.
Entrambe le letture sono limitate a un singolo attore, quindi l'attore è la partition key e l'ora dell'evento è la sort key. Usa nomi di chiave generici così che la stessa tabella possa contenere altre entità in seguito:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
Il prefisso EVT# più un timestamp ISO-8601 dà una sort key ordinabile. La
lettura 1 è Query PK = "ACTOR#u_8814" con ScanIndexForward = false per partire
dal più recente. La lettura 2 restringe la stessa partizione con una condizione
between sulla sort key:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"Una collection, due access pattern, nessuna GSI — perché la sort key è sia un
prefisso (EVT#) sia un intervallo (il timestamp). La lettura decrescente e la
lettura per finestra sono gli stessi item nello stesso ordine; cambiano solo i
parametri.
Costruendo quella key condition a mano, è facile sbagliare i limiti di between o
l'escape delle parole riservate sui nomi degli attributi.
Il DynamoDB Expression Builder
genera la KeyConditionExpression, gli ExpressionAttributeNames e gli
ExpressionAttributeValues per una condizione sort-key begins_with o between.
Copiala dritta nella tua chiamata SDK invece di debuggare l'escape a runtime.
Fallo in DynoTable
Progettare una sort key è iterativo: scrivi qualche item rappresentativo, esegui la query per intervalli e controlla che le righe tornino nell'ordine che ti aspetti. Farlo contro una tabella dal vivo in una GUI batte il round-trip attraverso il codice.

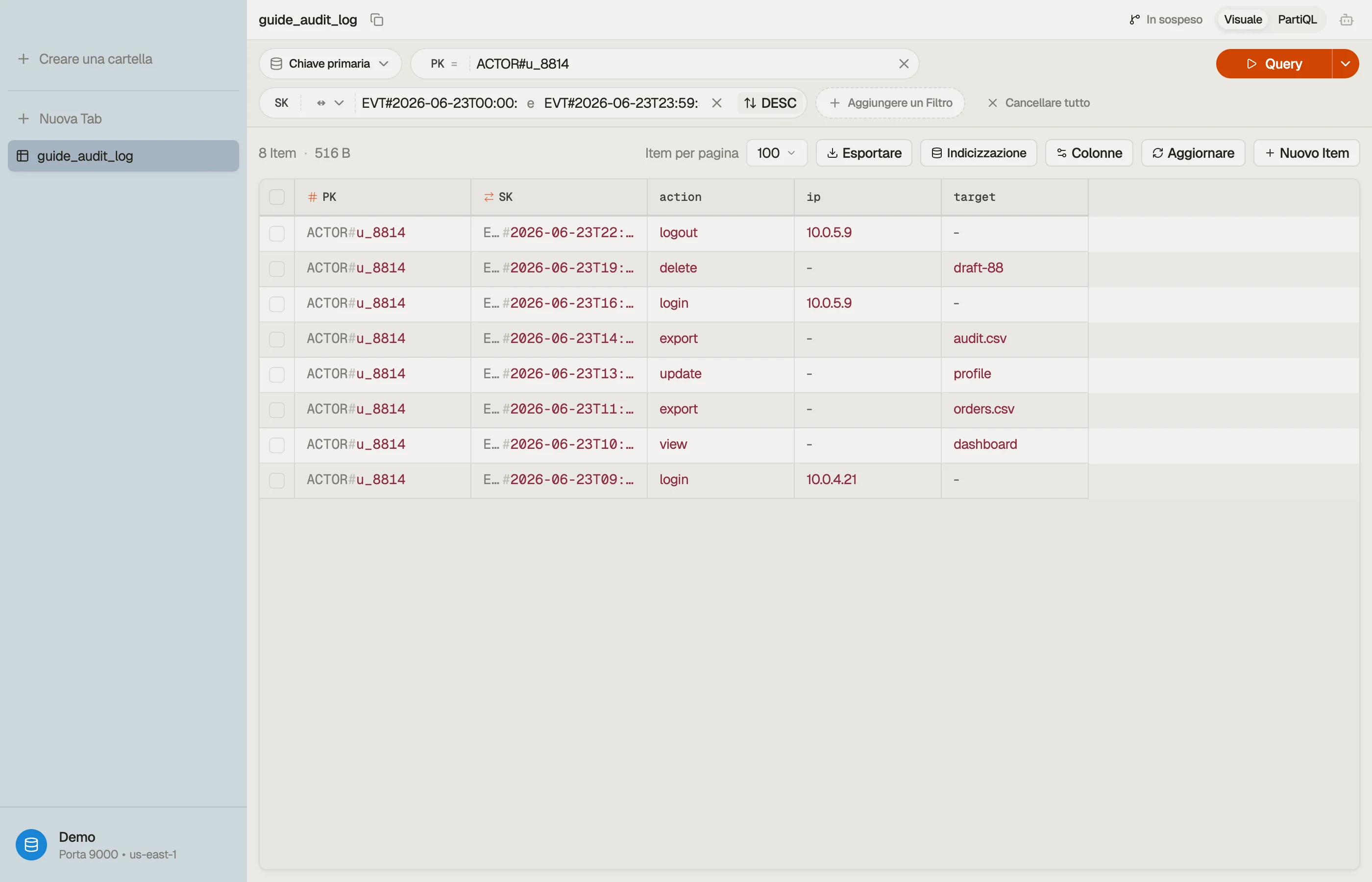

Inverti la direzione di ordinamento, stringi i limiti di between e guarda la
collection restituita cambiare senza scrivere una riga di codice — il modo più
rapido per confermare un design di sort key prima di committarlo.
Trappole e prossimi passi
- Le sort key devono essere uniche all'interno di una partizione. Se due eventi possono condividere un timestamp, aggiungi un disambiguatore (un numero di sequenza o un id breve) alla sort key così che la composta resti unica.
- Una hot partition non si può aggirare con l'ordinamento. Se un attore produce molti più eventi degli altri, la sort key non ti salverà — ti serve un design di partition key che distribuisca il carico. Vedi single-table design.
- Un secondo ordine di sort richiede un secondo indice. La sort key della tabella base dà un ordinamento. Per ordinare gli stessi item in modo diverso (per tipo di evento, diciamo), aggiungi una GSI con una sort key diversa — pesando i compromessi local vs global secondary index.
- Non ricorrere a
Scanper "ordinare dopo". Ordinare lato client dopo unoScanlegge l'intera tabella e butta via l'ordinamento; è il footgun dello Scan. Spingi invece l'ordine nella sort key.
Una volta che la key condition è giusta, prova DynoTable per modellare la collection, eseguire le query crescenti e decrescenti fianco a fianco e verificare la tua strategia di sort key contro dati reali prima che vada in produzione.