Relazioni molti-a-molti in DynamoDB
Uno studente si iscrive a molti corsi; un corso accoglie molti studenti. In SQL
ricorri a una tabella di join e a un JOIN a quattro vie.
DynamoDB non ha join, quindi la relazione deve vivere nelle chiavi — e il
trucco è memorizzare ogni edge di iscrizione in una forma che entrambi i lati
possano interrogare direttamente con Query.
Questa guida affronta il problema studenti ↔ corsi da capo a fondo: gli access pattern, il pattern adjacency-list che li risolve, uno schema di chiavi originale da copiare e come leggere entrambe le direzioni senza mai scansionare la tabella.
Come si modella una relazione molti-a-molti in DynamoDB?
DynamoDB non ha join, quindi si modella una relazione molti-a-molti con il pattern : si memorizza ogni collegamento come il proprio item edge con chiave su un lato, poi si aggiunge una GSI invertita che scambia le chiavi. Un singolo edge, scritto una volta, risponde a Query da entrambe le direzioni a basso costo.
- Memorizza ogni iscrizione come il proprio item edge, non come un attributo lista su uno dei due lati.
- Imposta la chiave dell'edge sullo studente (
PK = STU#…,SK = ENROLL#CRS#…) così che una solaQueryrestituisca l'intero elenco di corsi di uno studente. - Aggiungi una GSI invertita che scambia i ruoli (
GSI1PK = CRS#…) così che lo stesso edge risponda anche a "chi c'è in questo corso?". - Un edge, scritto una volta, letto a basso costo in entrambi i versi — è tutto il gioco.
Inquadra prima gli access pattern
Il modeling in DynamoDB è access-pattern-first: decidi le letture prima di scegliere un singolo nome di attributo. Una relazione molti-a-molti ha quasi sempre due letture simmetriche più le ricerche delle entità:
- Ottieni il profilo di uno studente, ed elenca ogni corso a cui lo studente è iscritto.
- Ottieni i metadati di un corso, ed elenca ogni studente iscritto a quel corso.
- Cerca un singolo edge di iscrizione — per aggiornare un voto o annullare il corso.
Il problema: le due letture d'elenco puntano in direzioni opposte attraverso lo
stesso insieme di edge. Un design ingenuo serve una a basso costo e forza uno
Scan per l'altra — esattamente il footgun trattato in
Query vs Scan.
Il compito è rendere entrambe le direzioni una singola Query.
Usa il pattern adjacency-list
La guida ufficiale di DynamoDB per le relazioni è l'adjacency list: modella ogni relazione come un item la cui partition key è un estremo e la cui sort key è l'altro.
AWS lo documenta nella pagina Best Practices for Managing Many-to-Many Relationships della DynamoDB Developer Guide.
Perché le chiavi e non una seconda tabella? Perché la primitiva che DynamoDB ti
offre è una Query contro una singola partizione.
Una Query legge un intervallo contiguo di valori di sort key sotto un'unica
partition key in una sola operazione fatturata — è l'unico "join" che il motore
offre.
Per ottenere una relazione leggibile a basso costo da entrambi i lati, duplichi l'edge: lo scrivi una volta con chiave sullo studente, poi usi un secondary index per proiettare lo stesso edge con chiave sul corso.
Questo è il ragionamento sulle chiavi sovraccaricate del Single-Table Design, applicato a una relazione invece che a una gerarchia genitore-figlio.
La forma è due viste impilate dello stesso edge — la tabella base con chiave sullo studente, la GSI invertita con chiave sul corso:
Ogni edge è scritto una volta sulla tabella base e proiettato nella GSI con le
chiavi scambiate, così che una Query contro l'una o l'altra partizione legga la
relazione a basso costo.
La discendenza risale al paper Amazon Dynamo del 2007: la partition key è l'unità di distribuzione, e l'accesso a chiave singola è la strada veloce.
Le relazioni in DynamoDB sono un esercizio di piegare le letture molti-a-molti su quella strada veloce.
Lavora l'esempio: studenti ↔ corsi
Usa una tabella con chiavi generiche, PK e SK, e codifica il tipo di entità
nel valore. L'edge di iscrizione è il cuore del tutto:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Una sola Query PK = "STU#a91" restituisce il profilo dello studente e ogni
iscrizione in una lettura. Restringila con SK begins_with "ENROLL#" per
ottenere solo gli edge dei corsi. Questo risolve "elenca i corsi di uno
studente".
Ma "elenca gli studenti di un corso" punta dall'altra parte — e la tabella base non può rispondere, perché l'id dello studente è nella partition key, non nella sort key.
Aggiungi una global secondary index invertita che scambia i ruoli. Dai agli
item edge una coppia generica GSI1PK/GSI1SK che tiene il corso sul lato
partizione e lo studente sul lato ordinamento:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Ora Query GSI1 WHERE GSI1PK = "CRS#math204" elenca ogni studente in quel corso
— la lettura che la tabella base non poteva servire. Un solo item edge, scritto
una volta, risponde a entrambe le direzioni.
Deve essere una GSI, non una LSI: la partizione del corso è del tutto diversa da quella dello studente, e una LSI condivide la partition key della tabella base.
L'indice copre più partizioni, quindi deve essere globale — vedi GSI vs LSI.
Un dettaglio: le GSI in DynamoDB sono popolate in modo asincrono. Una nuovissima
iscrizione può impiegare un istante prima di comparire nella direzione CRS#….
Tratta la lettura del roster del corso come eventualmente coerente — cosa che la Developer Guide segnala esplicitamente per le global secondary index.
Scrivila e leggila in DynoTable
Scrivere l'iscrizione significa impostare quattro attributi chiave più i dati
propri dell'edge. La condizione che impedisce a uno studente di iscriversi due
volte allo stesso corso è una guardia attribute_not_exists(PK) sulla chiave
composta.
È esattamente il tipo di condizione che puoi assemblare visivamente con il
DynamoDB Expression Builder invece di
scrivere a mano gli ExpressionAttributeNames e i valori placeholder.
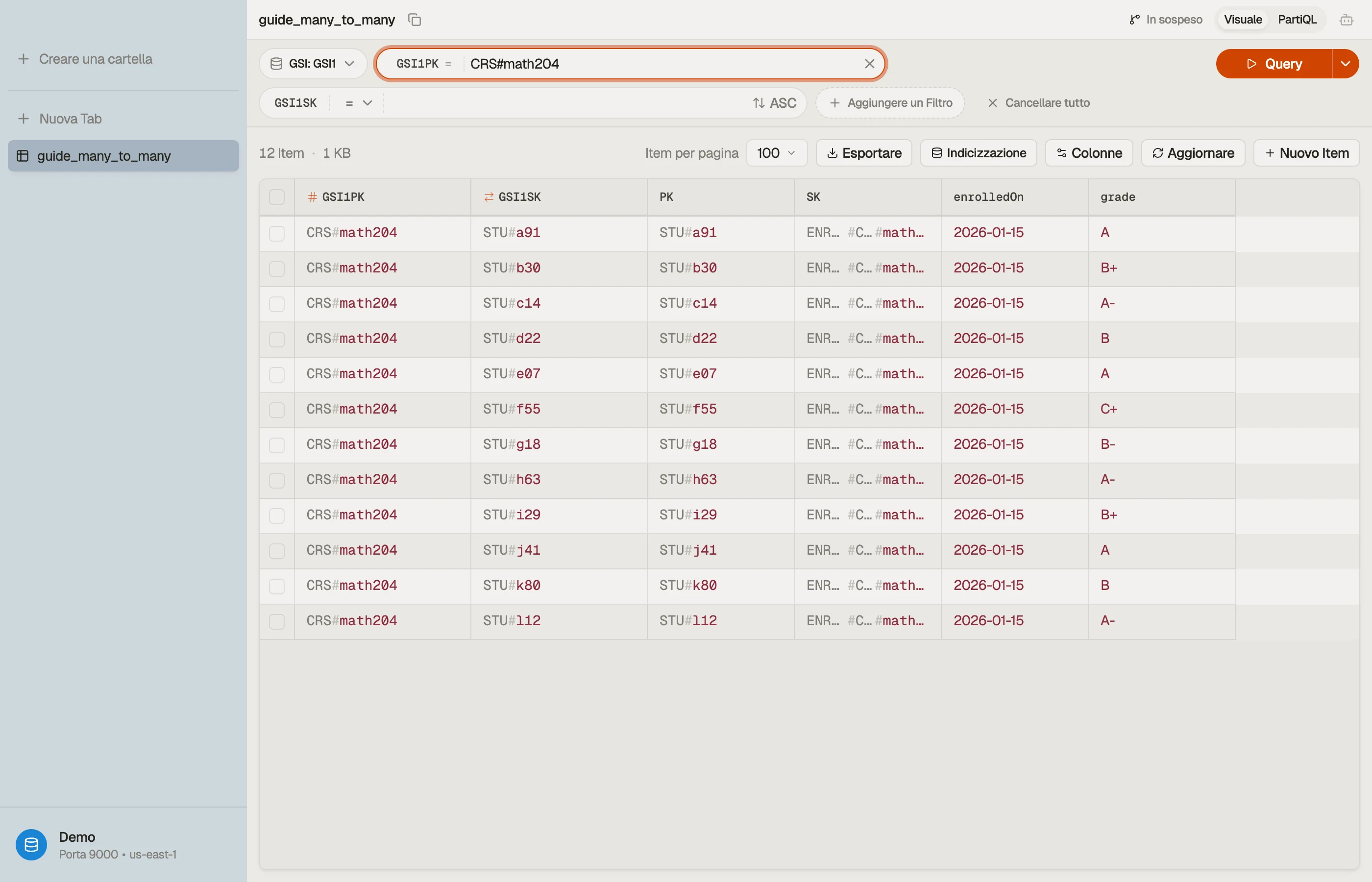
In DynoTable punti una Query su GSI1, imposti GSI1PK = "CRS#math204", e il
roster torna come una tabella che puoi leggere, ordinare e modificare in loco —
entrambe le direzioni della relazione esplorabili da un unico schema.


Trappole e prossimi passi
- Non memorizzare un lato come attributo lista. Un array
courseIdssull'item studente sembra ordinato finché un corso non ha bisogno del suo roster, l'array non raggiunge il tetto di 400 KB per item, o due iscrizioni non si scontrano in una gara sovrascrivendosi. Item edge distinti scalano e si aggiornano in modo indipendente. - Tieni i dati dell'edge sull'edge. Il
gradee l'enrolledOndell'iscrizione appartengono all'item edge, non duplicati sullo studente o sul corso — c'è esattamente una riga per coppia (studente, corso) da aggiornare. - Attenzione alla propagazione della GSI. La direzione dell'indice invertito è eventualmente coerente, quindi una lettura subito dopo un'iscrizione può ritardare di una frazione di secondo.
- Proietta solo ciò che serve al roster. Una proiezione
KEYS_ONLYo ristretta mantiene piccola la GSI quando la vista roster ha bisogno solo degli id.
Per approfondire i pattern circostanti, leggi Single-Table Design per le chiavi sovraccaricate e GSI vs LSI per quando l'indice invertito deve essere globale.
Poi scarica DynoTable per modellare lo schema studenti ↔ corsi sul serio — scrivi gli edge, costruisci la condizione con l'Expression Builder e interroga entrambe le direzioni della relazione senza una sola scansione.