Il pattern Adjacency List di DynamoDB
Un grafo non è altro che nodi e archi, e il pattern adjacency list memorizza entrambi
come semplici Item in una tabella. Ogni arco diventa una riga la cui chiave di partizione è il
nodo sorgente e la cui sort key è il target. Interrogare una partizione elenca ogni
vicino — il sostituto DynamoDB per un JOIN su una tabella di join.
Che cos'è il pattern adjacency list di DynamoDB?
Il pattern adjacency list modella un grafo come Item-arco in una singola tabella: ogni relazione (A segue B) è una riga con la sorgente sulla chiave di partizione e il target sulla sort key. Interrogare una partizione elenca ogni vicino, e un GSI invertito ribalta la relazione — niente join, niente scan, entrambe le direzioni in una sola query.
- Gli archi sono Item. Modella ogni relazione (l'utente A segue l'utente B) come il proprio Item con chiave: sorgente sulla chiave di partizione, target sulla sort key.
- Una direzione è gratis; l'altra ha bisogno di un GSI. La tabella base risponde a "chi segue A?" (chi A segue). Un indice invertito risponde a "chi sono i follower di A?".
- Niente join, niente scan. Entrambe le direzioni sono una sola
Querysu una partizione nota — mai unoScansull'intera tabella. - È il primitivo molti-a-molti. Follow, membership, like, amicizie — ogni grafo in cui un'entità si connette a molte altre rientra in questa forma.
Inquadralo come pattern di accesso
Venendo da SQL, un grafo di follow è una tabella di join: follows(follower_id, followee_id). Per elencare i follower di qualcuno indicizzi una colonna; per elencare chi
seguono indicizzi l'altra. DynamoDB non ha join, quindi progetti le chiavi per servire
ogni lettura direttamente.
Scrivi prima le letture. Per un grafo di follow social:
- Chi segue l'utente A? (la sua lista following)
- Chi segue A? (la sua lista followers)
- A segue B? (un singolo point lookup)
Le chiavi esistono solo per rispondere a quell'elenco. Azzeccale e ogni lettura è una sola
Query o GetItem.
Modella gli archi come Item
Usa nomi di chiave generici così la tabella può contenere più di un tipo di entità, e codifica il tipo di nodo nel valore. Un arco di follow appare così:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice è la sorgente dell'arco; SK = TARGET#bob è chi lei
segue. Una sola Query PK = "ACTOR#alice" restituisce ogni account che Alice segue in una
singola lettura fatturata — la sua intera lista following, senza join.
Ogni arco viene scritto una volta, nella direzione "chi seguo". La direzione inversa ("chi mi segue") è la parte a cui la tabella base non può rispondere — ancora.
Attraversa l'altra direzione con un GSI
La tabella base ha chiave sorgente-prima, quindi non può rispondere a "chi segue Bob?" senza fare uno scan. Aggiungi un global secondary index che inverte le chiavi: proietta il target sulla chiave di partizione dell'indice e la sorgente sulla sort key dell'indice.
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
Ora Query GSI1 WHERE GSI1PK = "TARGET#bob" elenca tutti quelli che seguono Bob —
alice e dave — in una sola lettura. Lo stesso Item-arco serve entrambe le direzioni: la
tabella base è following, l'indice è followers. Scrivi ogni arco una volta e
ottieni entrambe le query gratis.
Questo è esattamente il pattern che AWS documenta nella sua guida alle best-practice di DynamoDB per modellare relazioni molti-a-molti e dati a grafo — memorizza gli archi come Item, poi usa un GSI per invertire la relazione.
Controlla un singolo arco a basso costo
"Alice segue Bob?" non ha bisogno di nessuna delle due liste. Poiché l'arco ha chiave
PK = ACTOR#alice, SK = TARGET#bob, è un GetItem diretto — la lettura più economica
che DynamoDB offre, niente Query, niente indice.
Per scrivere il follow in modo idempotente ed evitare doppi conteggi, proteggi il PutItem
con una condizione che l'arco non esista già:
attribute_not_exists(PK)Puoi assemblare quella condizione — e i valori di chiave marshalled — con il
DynamoDB expression builder invece di
scrivere a mano il ConditionExpression e l'ExpressionAttributeValues.
Fallo in DynoTable
Quando navighi nella tabella, gli archi per un actor si impilano sotto una singola chiave di partizione come un'unica item collection, e passando alla vista GSI vedi la lista invertita dei follower — le due metà della relazione fianco a fianco.

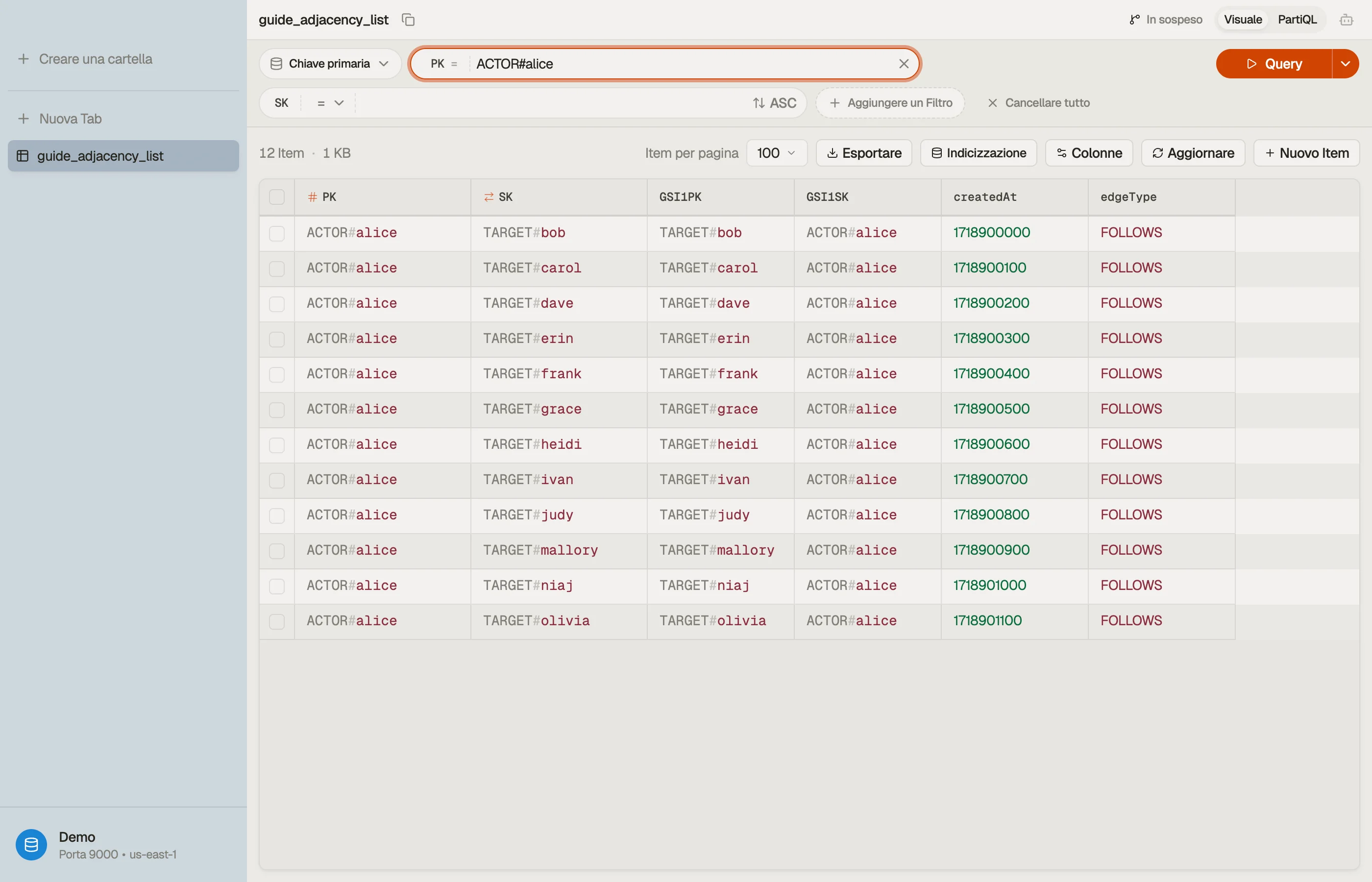

Errori
La partizione "celebrità". Un utente con milioni di follower concentra ogni
arco di follower sotto una partizione GSI1PK = TARGET#<star>. Le letture di quella
collection sono paginate e possono scaldarsi. Per grafi a fan-out intenso, fai lo shard della hot
key (es. TARGET#bob#0..N) o denormalizza i conteggi così non rileggi l'intera
lista.
Memorizzare i conteggi sull'arco. Un conteggio di follower non è un arco — non derivarlo leggendo e contando l'intera partizione a ogni visualizzazione del profilo. Mantieni un attributo contatore sull'Item utente e aggiornalo transazionalmente con l'arco.
Dimenticare che la scrittura inversa non serve qui. Una classica variante adjacency-list scrive l'arco due volte con gli id scambiati. Con un GSI a chiave invertita lo scrivi una volta e lasci che l'indice materializzi l'inverso — meno scritture, nessuna deriva tra le due copie.
Prossimi passi
L'adjacency list è il building block delle relazioni del
single-table design; l'indice invertente è un
GSI, non un LSI, perché la chiave di partizione cambia. E
ogni lettura qui è una Query o GetItem su una chiave nota — mai il
footgun dello Scan.
Costruisci le espressioni di condizione e di chiave con il DynamoDB expression builder, e scarica DynoTable per modellare un grafo di follow sulla tua tabella e osservare entrambe le direzioni risolversi in una sola lettura.