DynamoDB의 다대다 관계
한 학생은 여러 강좌에 등록하고, 한 강좌는 여러 학생을 담습니다. SQL이라면 조인
테이블과 4-way JOIN에 손을 뻗었을 겁니다.
DynamoDB에는 조인이 없으므로 관계는 키에 담겨야 합니다 — 그리고 비결은 각
등록 엣지를, 양쪽이 직접 Query할 수 있는 형태로 저장하는 것입니다.
이 가이드는 학생 ↔ 강좌 문제를 처음부터 끝까지 따라갑니다: 액세스 패턴, 그것을 푸는 인접 리스트 패턴, 그대로 복사할 수 있는 독자적인 키 스키마, 그리고 테이블을 스캔하지 않고 양방향을 다시 읽는 방법.
DynamoDB에서 다대다 관계를 어떻게 모델링하나요?
DynamoDB에는 조인이 없으므로, 한쪽으로 키잉된 자체 엣지 아이템으로 각 연결을 저장하고 키를 맞바꾸는 역전된 GSI를 추가하는 인접 리스트 패턴으로 다대다 관계를 모델링합니다. 한 번 쓴 단일 엣지가 양방향 쿼리를 저렴하게 처리합니다.
- 각 등록을 자체 엣지 아이템으로 저장하세요, 어느 한쪽의 리스트 속성이 아니라.
- 엣지를 학생으로 키잉하세요(
PK = STU#…,SK = ENROLL#CRS#…). 그러면 한 번의Query가 학생의 전체 강좌 목록을 돌려줍니다. - 역전된 GSI를 추가하세요. 역할을 맞바꾸면(
GSI1PK = CRS#…) 같은 엣지가 "이 강좌에 누가 있나?"에도 답합니다. - 한 번 쓴 엣지 하나가 양방향으로 저렴하게 읽힙니다 — 그게 게임의 전부입니다.
먼저 액세스 패턴을 정하세요
DynamoDB 모델링은 액세스 패턴 우선입니다. 단 하나의 속성 이름을 고르기 전에 읽기를 먼저 정합니다. 다대다 관계에는 거의 항상 엔티티 조회에 더해 두 개의 대칭적인 읽기가 있습니다:
- 학생의 프로필을 가져오고, 그 학생이 등록한 모든 강좌를 나열하기.
- 강좌의 메타데이터를 가져오고, 그 강좌에 등록한 모든 학생을 나열하기.
- 단일 등록 엣지 조회하기 — 성적을 갱신하거나 수강을 취소하기 위해.
까다로운 점: 두 목록 읽기가 같은 엣지 집합을 정반대 방향으로 가리킵니다. 순진한
설계는 한쪽을 저렴하게 처리하고 다른 쪽엔 Scan을 강요합니다 —
Query vs Scan에서 다룬 바로 그 함정이죠.
할 일은 양쪽 방향을 단일 Query로 만드는 것입니다.
인접 리스트 패턴을 쓰세요
관계에 대한 DynamoDB 자체의 지침은 인접 리스트(adjacency list) 입니다. 각 관계를, 파티션 키가 한쪽 끝점이고 정렬 키가 다른 쪽 끝점인 아이템으로 모델링합니다.
AWS는 이를 DynamoDB 개발자 안내서의 다대다 관계 관리 모범 사례 페이지에서 문서화합니다.
왜 두 번째 테이블이 아니라 키인가요? DynamoDB가 주는 원시 도구가 단일 파티션을 향한
Query이기 때문입니다.
Query는 한 파티션 키 아래 정렬 키 값들의 연속 범위를 단일 과금 작업으로
읽습니다 — 그게 엔진이 제공하는 유일한 "조인"입니다.
양쪽 에서 저렴하게 읽히는 관계를 얻으려면 엣지를 복제합니다. 학생으로 키잉해 한 번 쓴 뒤, 보조 인덱스로 같은 엣지를 강좌로 키잉해 프로젝션하는 거죠.
이것은 싱글 테이블 디자인의 오버로드 키 사고방식을 부모-자식 계층 대신 관계에 적용한 것입니다.
형태는 같은 엣지의 두 겹 뷰입니다 — 학생으로 키잉된 베이스 테이블, 강좌로 키잉된 역전 GSI:
각 엣지는 베이스 테이블에 한 번 쓰이고, 키를 맞바꾼 채 GSI에 프로젝션되므로, 어느
파티션에 Query해도 관계가 저렴하게 읽힙니다.
그 계보는 2007년 Amazon Dynamo 논문으로 거슬러 올라갑니다. 파티션 키가 분산의 단위이고, 단일 키 접근이 빠른 경로입니다.
DynamoDB에서 관계란 다대다 읽기를 그 빠른 경로에 끼워 맞추는 연습입니다.
예제 풀어보기: 학생 ↔ 강좌
범용 키 PK와 SK를 가진 하나의 테이블을 쓰고, 엔티티 유형은 값에 인코딩합니다.
등록 엣지가 핵심입니다:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
단일 Query PK = "STU#a91"은 학생의 프로필 과 모든 등록을 한 번의 읽기로
돌려줍니다. SK begins_with "ENROLL#"로 좁히면 강좌 엣지만 얻습니다. 이걸로
"학생의 강좌 나열하기"가 해결됩니다.
하지만 "강좌의 학생 나열하기"는 반대 방향을 가리키고 — 학생 id가 파티션 키에 있고 정렬 키에 없으므로 베이스 테이블은 답할 수 없습니다.
역할을 맞바꾸는 역전 글로벌 보조 인덱스를 추가하세요. 엣지 아이템에 범용
GSI1PK/GSI1SK 쌍을 주어, 강좌를 파티션 쪽에, 학생을 정렬 쪽에 담습니다:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
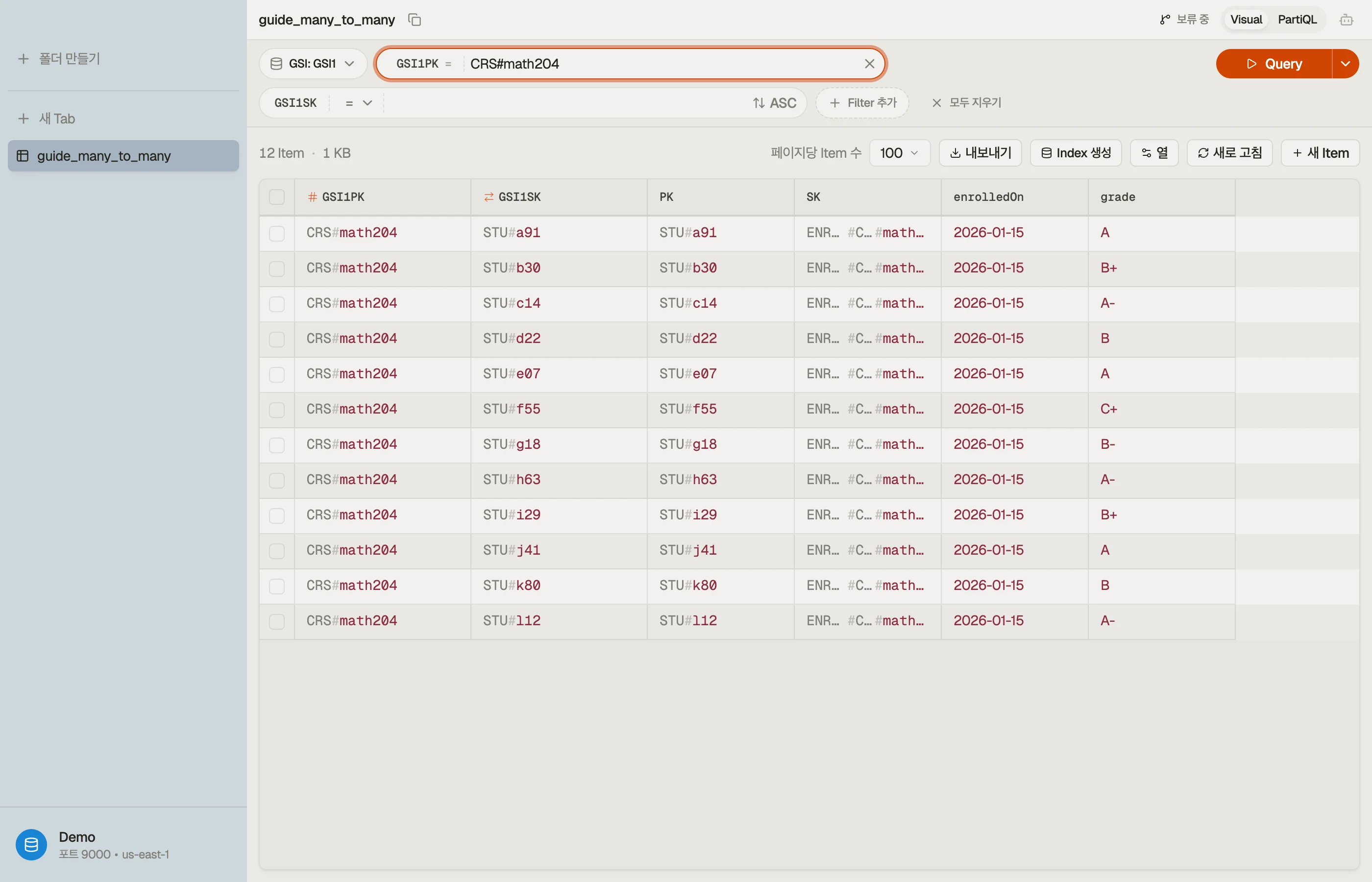
이제 Query GSI1 WHERE GSI1PK = "CRS#math204"가 그 강좌의 모든 학생을 나열합니다 —
베이스 테이블이 제공할 수 없던 읽기죠. 한 번 쓴 하나의 엣지 아이템이 양방향에
답합니다.
LSI가 아니라 GSI여야 합니다. 강좌 파티션은 학생 파티션과 완전히 다른데, LSI는 베이스 테이블의 파티션 키를 공유하기 때문입니다.
이 인덱스는 여러 파티션에 걸치므로 글로벌이어야 합니다 — GSI vs LSI를 보세요.
한 가지 주의: DynamoDB의 GSI는 비동기로 채워집니다. 갓 생긴 등록은 CRS#… 방향에
나타나기까지 잠시 걸릴 수 있습니다.
강좌 명단 읽기는 최종적 일관성으로 취급하세요 — 개발자 안내서가 글로벌 보조 인덱스에 대해 명시적으로 짚는 점입니다.
DynoTable에서 쓰고 읽기
등록을 쓴다는 건 네 개의 키 속성과 엣지 자체의 데이터를 설정하는 일입니다. 한
학생이 같은 강좌에 두 번 등록하는 걸 막는 조건은 복합 키에 대한
attribute_not_exists(PK) 가드입니다.
그게 바로 ExpressionAttributeNames와 플레이스홀더 값을 손으로 쓰는 대신
DynamoDB 표현식 빌더로 시각적으로 조립할 수
있는 종류의 조건입니다.
DynoTable에서 Query를 GSI1에 겨누고 GSI1PK = "CRS#math204"를 설정하면, 명단이
읽고 정렬하고 제자리에서 편집할 수 있는 테이블로 돌아옵니다 — 관계의 양방향을 한
스키마에서 둘러볼 수 있습니다.


함정과 다음 단계
- 한쪽을 리스트 속성으로 저장하지 마세요. 학생 아이템의
courseIds배열은 강좌가 명단을 필요로 하거나, 배열이 400KB 아이템 한계에 부딪히거나, 두 등록이 경쟁해 서로를 덮어쓸 때까지는 깔끔해 보입니다. 개별 엣지 아이템은 독립적으로 확장되고 갱신됩니다. - 엣지 데이터는 엣지에 두세요. 등록의
grade와enrolledOn은 학생이나 강좌에 중복되는 게 아니라 엣지 아이템에 속합니다 — (학생, 강좌) 쌍마다 갱신할 행이 정확히 하나뿐입니다. - GSI 전파를 유념하세요. 역전 인덱스 방향은 최종적 일관성이라, 등록 직후의 읽기는 1초의 일부만큼 늦을 수 있습니다.
- 명단에 필요한 것만 프로젝션하세요. 명단 뷰가 id만 필요하다면
KEYS_ONLY나 좁은 프로젝션이 GSI를 작게 유지합니다.
주변 패턴을 더 깊이 보려면, 오버로드 키는 싱글 테이블 디자인을, 역전 인덱스가 글로벌이어야 하는 경우는 GSI vs LSI를 읽으세요.
그런 다음 DynoTable을 다운로드해 학생 ↔ 강좌 스키마를 실제로 모델링하세요 — 엣지를 쓰고, 표현식 빌더로 조건을 만들고, 단 한 번의 스캔도 없이 관계의 양방향을 쿼리하세요.