DynamoDB 참조 카운트
참조 카운트는 얼마나 많은 자식 아이템이 부모를 가리키는지 추적하기 위해 부모 아이템에 저장하는 숫자입니다 — 게시물의 좋아요, 워크스페이스의 구성원, 댓글의 답글. 매 읽기마다 자식을 세는 것이 너무 비싸기 때문에 이를 유지합니다.
DynamoDB에서 카운트를 어떻게 유지하나요?
부모 아이템에 실행 중인 총합을 숫자로 저장하고, 자식을 생성하는 쓰기와 같은 연산에서 이를 업데이트하세요. 를 사용하면 두 작업이 모두 반영되거나 하나도 반영되지 않으며, 자식 쓰기에 조건을 걸면 재시도로 인한 이중 카운팅을 막을 수 있습니다 — 따라서 단일 GetItem으로 정확한 카운트를 반환할 수 있습니다.
- 읽기 시점에 자식을 세지 마세요. 좋아요를 세는
Query는 훑는 모든 좋아요 아이템에 과금됩니다. 총합을 게시물에 저장하고 아이템 하나만 읽으세요. - 자식이 쓰이는 곳에서 카운트를 유지하세요, 나중이 아니라요. 자식을 생성하는 같은 연산에서 카운트를 올려 둘이 절대 어긋나지 않게 하세요.
- 쓰기와 카운트 증가가 서로 다른 아이템을 건드릴 때는 트랜잭션을 사용하세요. 좋아요는 한
아이템이고 카운트는 다른 아이템에 있습니다 —
TransactWriteItems가 둘 다 반영되거나 둘 다 반영되지 않게 합니다. - 지뢰는 이중 카운팅입니다. 재시도되거나 중복된 좋아요가 증가를 다시 실행하면 숫자가 부풀려집니다. 자식 쓰기를 조건으로 보호하세요.
애초에 왜 세는가
SQL에서 왔다면 좋아요 수를 저장할 일이 없을 겁니다 — SELECT COUNT(*) FROM likes WHERE post_id = ?로 인덱스가 그것을 값싸게 만들도록 하면 됩니다. DynamoDB에는 아이템 읽기를
건너뛰는 COUNT(*)가 없습니다.
게시물의 좋아요에 대한 Query는 숫자만 원하더라도 그 파티션의 모든 좋아요 아이템을 읽고 —
또 거기에 과금합니다. 바이럴 게시물에서는 "좋아요가 몇 개야?"에 답하는 데 수천 RCU가 듭니다.
그게 바로 참조 카운트가 없애려고 존재하는 읽기 지뢰입니다.
그래서 비정규화합니다. 진행 중인 총합을 게시물 자체에 저장합니다. 카운트 읽기는 단일
GetItem이 됩니다. 그 대가는 이제 그것을 정확하게 유지하는 책임을 여러분이 진다는 것입니다.
아이템 모델링하기
게시물과 그 좋아요가 하나의 아이템 컬렉션에 함께 자리하도록 두 아이템 타입이 파티션을 공유합니다. 임의의 키:
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
META 아이템의 likeTally 속성이 참조 카운트입니다. 각 LIKE# 아이템은 자식입니다. 둘 다
PK = "POST#a91f" 아래에 두면, 목록을 실제로 원할 때 하나의 Query로 게시물과 좋아요 누른
사람들을 함께 가져올 수 있습니다.
카운트를 원자적으로 올리기
DynamoDB는 ADD(또는 SET x = x + :n) 업데이트 표현식으로 숫자를 증가시킵니다 — 이것이
원자적 카운터입니다. DynamoDB는 현재 값을 먼저 읽지 않고 서버 측에서 델타를 적용하므로,
동시 증가가 서로를 덮어쓰지 않습니다.
(AWS: 원자적 카운터)
문제는 이것입니다. 게시물에 좋아요를 누르는 것은 두 아이템에 대한 두 번의 쓰기입니다 —
LIKE# 아이템을 생성하고, META의 likeTally에 1을 더합니다. 좋아요는 반영됐는데 증가가
실패하면, 집계는 영원히 틀립니다. 둘 다거나 둘 다 아니어야 합니다.
그게 TransactWriteItems가 보장하는 것입니다 — 여러 아이템에 걸친 전부 아니면 전무이며,
어떤 아이템이라도 동시에 수정되면 전체 트랜잭션을 취소합니다
(AWS: 트랜잭션을 사용한 비관적 잠금):
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Put과 Update는 함께 커밋됩니다. 둘 중 하나라도 실패하면, DynamoDB는 둘 다 롤백하고
TransactionCanceledException을 반환합니다.
이중 카운팅 방지
진짜 버그는 절반만 쓰인 좋아요가 아닙니다 — 트랜잭션이 그걸 막아 줍니다. 그건 같은 사용자가
두 번 좋아요를 누르는 것, 또는 클라이언트 재시도가 요청을 다시 재생하는 것입니다. 각 재생이
또 1을 더하고, likeTally는 조용히 실제 카운트 위로 떠내려갑니다.
Put의 ConditionExpression: attribute_not_exists(SK)가 그 보호 장치입니다. 그 사용자의
LIKE# 아이템이 이미 존재하면 Put의 조건이 실패하고, 전체 트랜잭션이 취소되며 —
결정적으로 — ADD가 절대 실행되지 않습니다. 사용자당 좋아요 하나, 키로 강제됩니다.
이 업데이트 및 조건 표현식을 — 올바른 ExpressionAttributeValues와 attribute_not_exists
보호 장치와 함께 — JSON을 손으로 조립하는 대신
DynamoDB 표현식 빌더에서 만들고 복사하세요.
좋아요 취소, 그리고 비용
좋아요를 제거하는 것은 거울상입니다. ConditionExpression: attribute_exists(SK)로 LIKE#
아이템을 Delete하고, 같은 트랜잭션에서 ADD likeTally :minusOne을 합니다. 조건은 이중
좋아요 취소가 집계를 음수로 몰고 가는 것을 막습니다.
비용을 아세요. 트랜잭션 쓰기는 1 KB까지의 아이템에 대해 아이템당 2 WCU가 듭니다 — 하나는 준비, 하나는 커밋 — 일반 쓰기의 1 WCU에 비해서요. 좋아요는 두 아이템이므로, 각 좋아요는 대략 4 WCU입니다. 동작당으로는 싸지만, 유명인 게시물이 좋아요 폭풍을 맞기 전에 알아 둘 만합니다.
DynoTable에서 보기
집계가 어긋났다고 의심될 때, 저장된 likeTally를 실제 LIKE# 자식의 개수와 비교하고 싶을
겁니다 — 프로덕션에서 카운트 쿼리를 돌리지 않고서요.

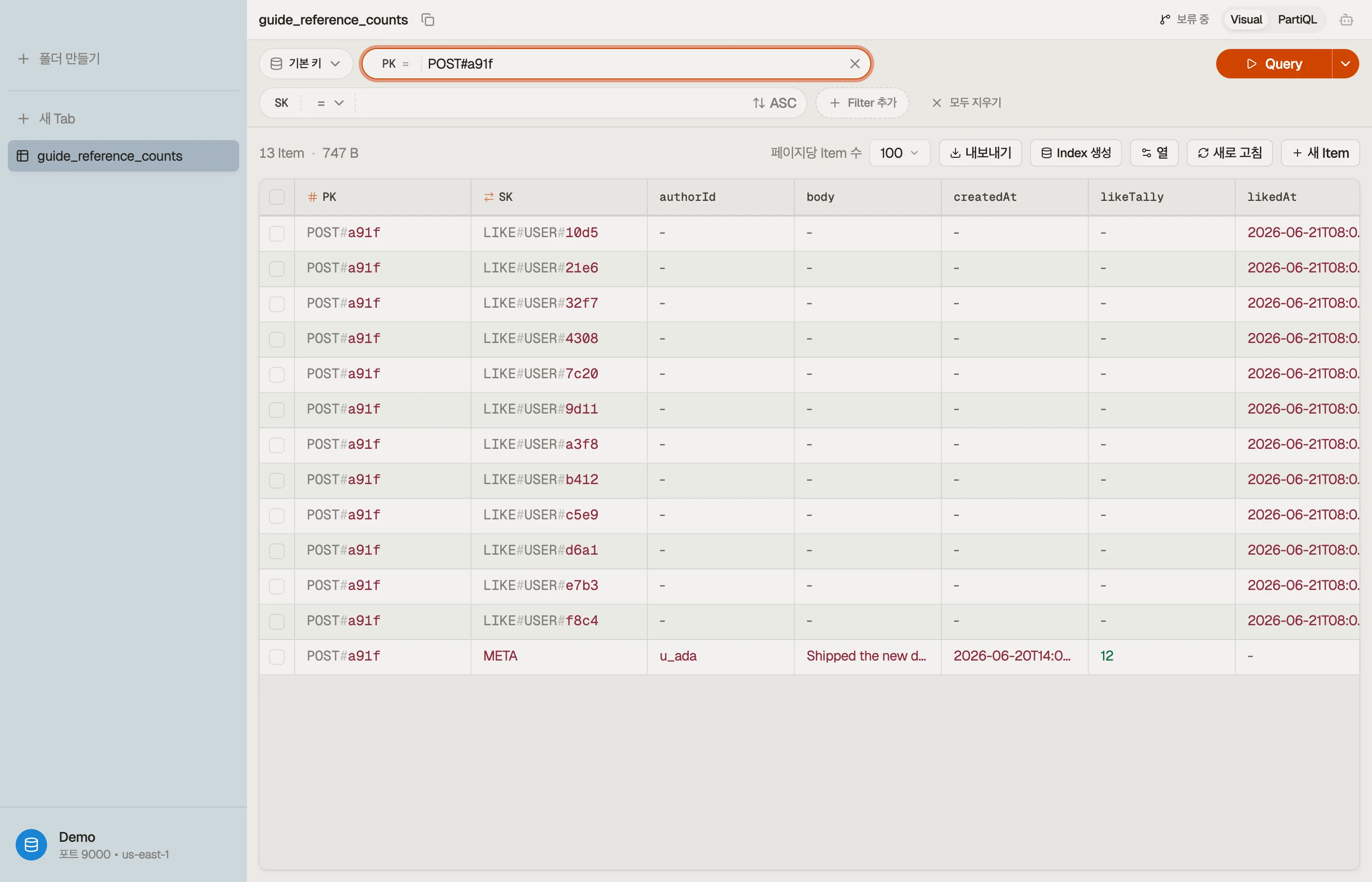

한정된 게시물 집합에 걸친 진정한 정합성 검사 — "어느 집계가 자식 개수와 안 맞지?" — 를 위해,
DynoTable의 SQL Workbench는 여러분이 불러온 행에 대해 GROUP BY와 조인을 클라이언트 측에서
실행합니다. 이는 일반 PartiQL이 표현할 수 없는 것입니다.
함정과 다음 단계
- 카운트를 밖에서 유지하지 마세요(밤마다 다시 세는 Lambda 같은 것). 그건 애초에 트랜잭션으로 했어야 할 쓰기 경로에 붙인 반창고입니다.
- 핫 파티션을 주의하세요. 한 게시물이 폭발적으로 인기를 끌면 모든 좋아요 — 그리고 모든 집계 증가 — 가 하나의 파티션 키에 집중됩니다. 카운트는 정확합니다. 파티션은 여전히 스로틀될 수 있습니다.
- 드물게 정합성을 맞추고, 외과적으로 복구하세요. 모든 변경이 조건으로 보호된다면 어긋남은 거의 0이어야 합니다. 불일치는 덮어쓸 숫자가 아니라 찾아내야 할 버그로 다루세요.
관련 읽을거리: 게시물과 좋아요가 파티션을 공유하는 이유에 관한 단일 테이블 설계, 그리고 읽기 시점에 자식을 세는 것이 여러분이 피하려는 패턴인 이유에 관한 Query vs Scan.
그런 다음 DynoTable을 다운로드해 이 아이템 컬렉션을 점검하고 여러분 자신의 테이블에 대해 집계를 검증하세요.