DynamoDB에서 데이터를 모델링하는 법
SQL에서는 엔티티와 관계를 먼저 모델링하고, 나중에 무엇을 요청하든 쿼리 플래너가 알아서 조립해 줄 거라 믿습니다. DynamoDB는 그걸 뒤집습니다. 이미 하게 될 줄 아는 읽기를 모델링하고, 키는 그것을 위해 존재합니다.
조인 엔진도 없고 런타임에 전략을 고르는 플래너도 없습니다. Query는 하나의 키를 따라 한 파티션을 읽고, 그것이 성능 계약의 전부입니다. 그래서 깔끔한 스키마가 아니라 알려진 액세스 패턴을 위해 키를 설계합니다.
AWS는 모범 사례 안내서에서 단순명료하게 말합니다. "스키마가 답해야 할 질문들을 알기 전에는 스키마 설계를 시작하지 마세요."
이 가이드는 하나의 도메인에서 전체 과정을 따라갑니다: 플레이어, 그들이 치르는 경기, 그리고 시즌별 순위를 추적하는 멀티플레이어 게임 리더보드. 질문 목록에서 출발해 작동하는 키 스키마까지 갑니다.
DynamoDB에서 데이터를 어떻게 모델링하나요?
테이블이 아니라 읽기를 먼저 모델링하세요. 앱이 수행하는 모든 쿼리를 나열한 뒤, 각 질문이 단일 Query나 GetItem으로 풀리도록 파티션 키와 정렬 키를 설계하세요. 함께 읽는 아이템은 같은 파티션 키 아래 두고, 범위로 훑을 값은 정렬 키에 넣고, 베이스 테이블이 처리할 수 없는 액세스 패턴에는 GSI를 추가하세요.
- 테이블이 아니라 읽기를 먼저 나열하세요. 질문이 명세이고, 명사는 주의를 흩뜨립니다.
- 각 질문은 하나의
Query나GetItem이어야 합니다. 질문이Scan을 필요로 하면 모델이 틀렸습니다. - 함께 둘 아이템은 파티션 키를 공유하고, 범위로 훑을 것은 정렬 키에 넣습니다.
- 베이스 테이블이 답할 수 없는 질문은 GSI를 얻습니다 — 결코 필터를 단
Scan이 아니라.
1단계 — 문제를 테이블이 아니라 질문으로 짜세요
players, matches, scores 테이블을 그리고 싶은 충동을 참으세요. 그 본능은 SQL 습관이고, 여기서는 틀렸습니다. 대신 앱이 실제로 수행하는 모든 읽기를 적으세요. 우리 리더보드의 경우:
- id로 플레이어 하나의 프로필 가져오기.
- 한 플레이어의 최근 경기를 최신순으로 나열하기.
- 주어진 시즌의 상위 N명 플레이어를 레이팅 순으로 보여주기.
- 공개 핸들로 플레이어 조회하기(예: 프로필 URL용).
이 네 질문이 — 명사가 아니라 — 명세입니다. 각각은 하나의 Query(또는 GetItem)로 풀려야 합니다. 그것이 DynamoDB가 대규모에서 저렴하게 제공하는 유일한 액세스 형태이니까요.
질문이 테이블을 스캔해야만 답할 수 있다면 모델이 틀렸고, 그건 지연 시간과 비용으로 체감됩니다 — Scan이 왜 피해야 할 함정인지는 Query vs Scan을 보세요.
이 방법 전체는 도메인마다 한 번 실행하는 짧고 순서 있는 파이프라인입니다:
아래 각 단계는 상자 하나에 대응합니다: 나열, 열거, 키 설계, 나머지에 인덱스 추가, 그다음 검증.
2단계 — 모델링에 쓰는 원시 요소를 이해하세요
테이블에는 아이템이 어느 물리 파티션에 사는지 고르는 파티션 키(PK) 와, 그 파티션 안에서 아이템을 정렬하는 선택적 정렬 키(SK) 가 있습니다.
AWS 핵심 구성 요소 문서는 이 쌍을 아이템의 기본 키라 부릅니다. Query는 항상 정확히 하나의 PK 값을 겨냥하고 SK를 범위로 훑거나 필터링할 수 있습니다 — 그게 도구 전부입니다.
이 단일 파티션 설계가 DynamoDB로 하여금 2007년 Amazon Dynamo 논문이 처음 기술한 예측 가능하고 낮은 지연의 수평 분할된 읽기를 제공하게 하는 것입니다.
두 가지 귀결이 아래 모든 결정을 이끕니다:
- 함께 읽는 아이템은 파티션 키를 공유해야 하나의
Query가 단일 과금 요청으로 그들을 돌려줍니다. - 범위로 훑고 싶은 것은(최근 경기, 상위 레이팅) 정렬 키에 살아야 합니다.
Query가 정렬하고 한정할 수 있는 유일한 속성이니까요.
질문이 베이스 테이블이 제공하는 것과 다른 액세스 형태를 필요로 하면, 글로벌 보조 인덱스 — 테이블을 다른 PK/SK로 다시 프로젝션한 것 — 를 추가합니다.
(GSI 대 로컬 보조 인덱스는 GSI vs LSI를 보세요.)
3단계 — 한 번에 한 질문씩 키를 설계하세요
플레이어와 그 경기를 함께 읽으므로, 범용적이고 오버로드된 키 속성을 가진 하나의 테이블 — 싱글 테이블 접근 — 을 씁니다.
여러분만의 접두사를 발명하세요. 여기서는 PLAYER#, MATCH#, SEASON#이 그 외엔 범용인 키 안에서 엔티티 유형을 태깅합니다.
질문 1과 2(프로필 + 최근 경기)는 파티션을 공유하므로, 둘 다 같은 PK에 매답니다:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231"은 프로필과 모든 경기를 한 번의 읽기로 돌려줍니다. 프로필만 원하면 GetItem.
최근 경기는 rangeId begins_with "MATCH#"와 ScanIndexForward = false로 최신순으로 훑습니다 — 정렬 키의 타임스탬프가 정렬을 공짜로 해 줍니다.
질문 3과 4는 그 파티션에서 답할 수 없습니다 — 시즌 순위와 핸들을 축으로 도는데, 둘 다 베이스 PK가 아닙니다. 각각 GSI를 얻습니다.
범용 인덱스 속성 gsiPartition / gsiSort 두 개를 추가하고, 각 아이템이 그 인덱스가 필요로 하는 무엇으로든 그것들을 채우게 합니다:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
이제 시즌 인덱스를 WHERE gsiPartition = "SEASON#2026-Q2"로 ScanIndexForward = false로 Query하면 플레이어가 레이팅 순으로 돌아옵니다 — 그게 리더보드입니다.
HANDLE#…로 키잉된 두 번째 인덱스는 공개 핸들을 한 번의 읽기로 플레이어 id로 해석합니다. 물리 테이블 하나, 단일 Query 액세스 패턴 네 개.
RATING#1842에 대한 0 패딩 참고: DynamoDB는 정렬 키를 숫자가 아니라 사전식으로 정렬하므로, 레이팅은 고정 폭으로 0 패딩하거나(RATING#01842)9가1000뒤로 정렬됩니다. 이것은 미리 제대로 짚어 둘 가치가 있는 고전적 모델링 함정입니다.
4단계 — DynoTable에서 모델 검증하기
키 스키마는 실제 Query가 정확히 기대한 아이템만 돌려주고 그 이상은 아니라는 걸 지켜봐야 비로소 신뢰를 얻습니다.
DynoTable에서 테이블을 열고, 시즌 인덱스에 리더보드 쿼리를 실행해, 파티션이 순위 매겨지고 한정된 채 돌아오는지 확인하세요 — Scan도, 클라이언트 측 정렬도 없이.

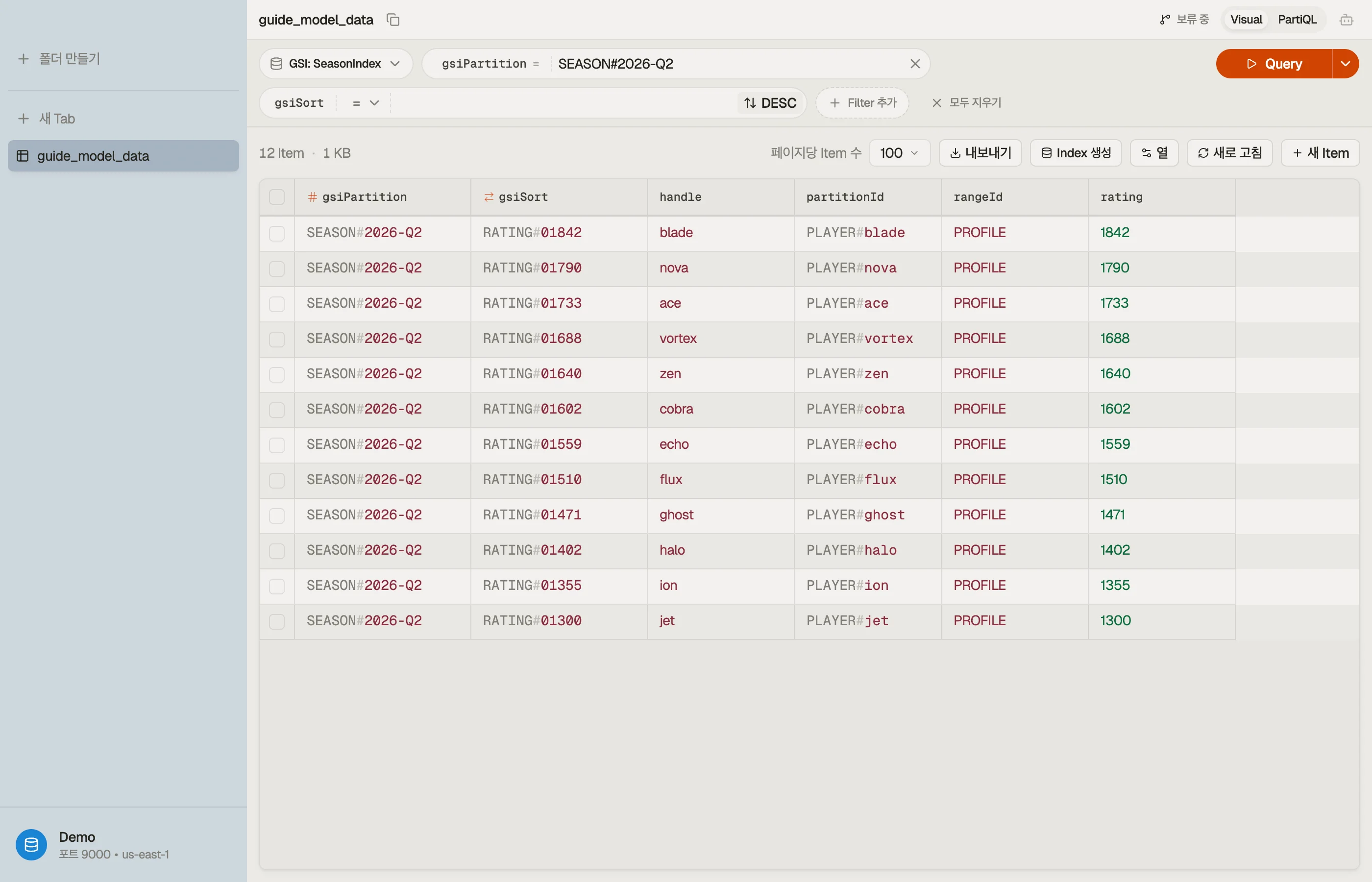

이 쿼리들의 조건 표현식 — begins_with, gsiPartition = :p, 플레이스홀더 :p 바인딩 — 을 지을 때는 DynamoDB 표현식 빌더가 하게 두세요.
이것은 KeyConditionExpression, ExpressionAttributeNames, ExpressionAttributeValues를 생성하므로, result 같은 예약어나 오타 난 플레이스홀더가 읽기를 조용히 망가뜨리는 일이 없습니다.
5단계 — 함정과 다음 단계
모델을 출시하기 전에 점검할 함정 몇 가지:
- 함께 읽지 않는 관계는 모델링하지 마세요. 질문당 GSI는 저렴하지만, 낭비된 GSI는 반복 비용입니다. 인덱스는 추측이 아니라 질문 목록에서 추가하세요.
- 파티션 열을 주의하세요. 한 PK(스타 플레이어, 단일 핫 시즌)가 트래픽 대부분을 흡수하면 그 파티션이 스로틀될 수 있습니다. 키가 명백히 뜨거우면 접미사 샤드로 쓰기를 퍼뜨리세요 — AWS는 이를 파티션 키 설계에서 다룹니다.
- 정렬 키의 숫자나 시간 값은 모두 0 패딩하고 ISO-8601로 하세요. 그래야 사전식 정렬이 의도한 순서와 맞습니다.
- 새 질문 = 새 키나 인덱스, 결코
Scan이 아닙니다. 정말로 새로운 액세스 패턴이 나중에 나타나면 키를 확장하세요. 필터로 덮어 가리지 마세요.
질문을 먼저 모델링하고, 각각이 하나의 Query가 되도록 키를 설계한 뒤, 증명하세요.
DynoTable을 써보세요. 테이블을 둘러보고, 이 쿼리들을 베이스 테이블과 GSI에 나란히 실행해, 여러분이 설계한 액세스 패턴이 계획한 그대로를 돌려주는 걸 지켜보세요.