DynamoDB의 키 오버로딩
SQL에서 넘어왔다면 컬럼은 영원히 한 가지를 의미합니다: orders.created_at은 항상
날짜이고, users.email은 항상 이메일입니다. 키 오버로딩은 그것을 내던집니다.
파티션 키와 정렬 키에 일반적인 이름 — pk, sk — 을 주고, 각 아이템 유형이 거기에 다른
의미를 부어 넣게 합니다. 하나의 테이블, 여러 엔티티, 하나의 형태.
DynamoDB에서 키 오버로딩이란 무엇인가요?
키 오버로딩은 pk/sk처럼 중립적인 키 이름 아래 여러 엔티티 유형을 하나의 테이블에 저장하고, 유형 정보를 값에 인코딩하는 패턴입니다 (USER#u_3001, INVOICE#2026-0014). 속성 이름은 중립으로 유지되므로 사용자, 인보이스, 이벤트가 동일한 파티션을 공유하고, 값이 유형을 실어 나르며, 정렬 키 접두사를 이용해 begins_with 조건 하나로 각 엔티티를 슬라이스할 수 있습니다.
- 일반적인 키 이름, 유형이 담긴 값. 키를
pk/sk로 이름 짓고 엔티티 유형을 값에 넣으세요:pk = "TENANT#acme",sk = "USER#u_3001". 이름은 멍청하고, 값이 유형을 실어 나릅니다. - 그것이 단일 테이블 설계를 작동하게 만듭니다. 오버로딩이 없으면 공유 테이블은 그저
잡동사니 서랍입니다. 오버로딩이 있으면 모든 엔티티가
Query할 수 있는 파티션에 앉습니다. begins_with가 보상입니다. 정렬 키의 유형 접두사는 하나의Query로 엔티티 전체나 그 한 조각을 —Scan도 필터도 없이 — 끌어내게 합니다.- 비용은 가독성입니다. 가공되지 않은
pk/sk덤프는 아무것도 알려주지 않습니다. 접두사를 해독하는 뷰어가 필요합니다. 그러지 않으면 문자열을 노려보게 됩니다.
일반적인 이름이 진짜 이름을 이기는 이유
DynamoDB는 테이블당 정확히 두 개의 키 속성을 가지며, Query는 단일 파티션 키만 겨냥할
수 있습니다. 그래서 키 이름을 userId로 지으면 사용자 아이템만 그 테이블에 깔끔하게
살 수 있습니다 — 다른 모든 것은 userId를 흉내 내거나 자체 테이블로 옮겨야 합니다.
오버로딩은 그것을 비켜갑니다. pk 같은 중립적인 이름은 어떤 엔티티에도 헌신하지 않으므로,
사용자, 인보이스, 감사 이벤트가 모두 같은 키 속성과 같은 테이블을 공유할 수 있습니다.
속성 이름이 아니라 값이 아이템이 무엇인지 말합니다.
이것이 단일 테이블 설계를 이론에서 실제로 쿼리할 수 있는 무언가로 바꾸는 한 수입니다. 공유 테이블은 컨테이너이고, 오버로딩은 구별되는 엔티티가 그 안에서 공존하게 하는 것입니다.
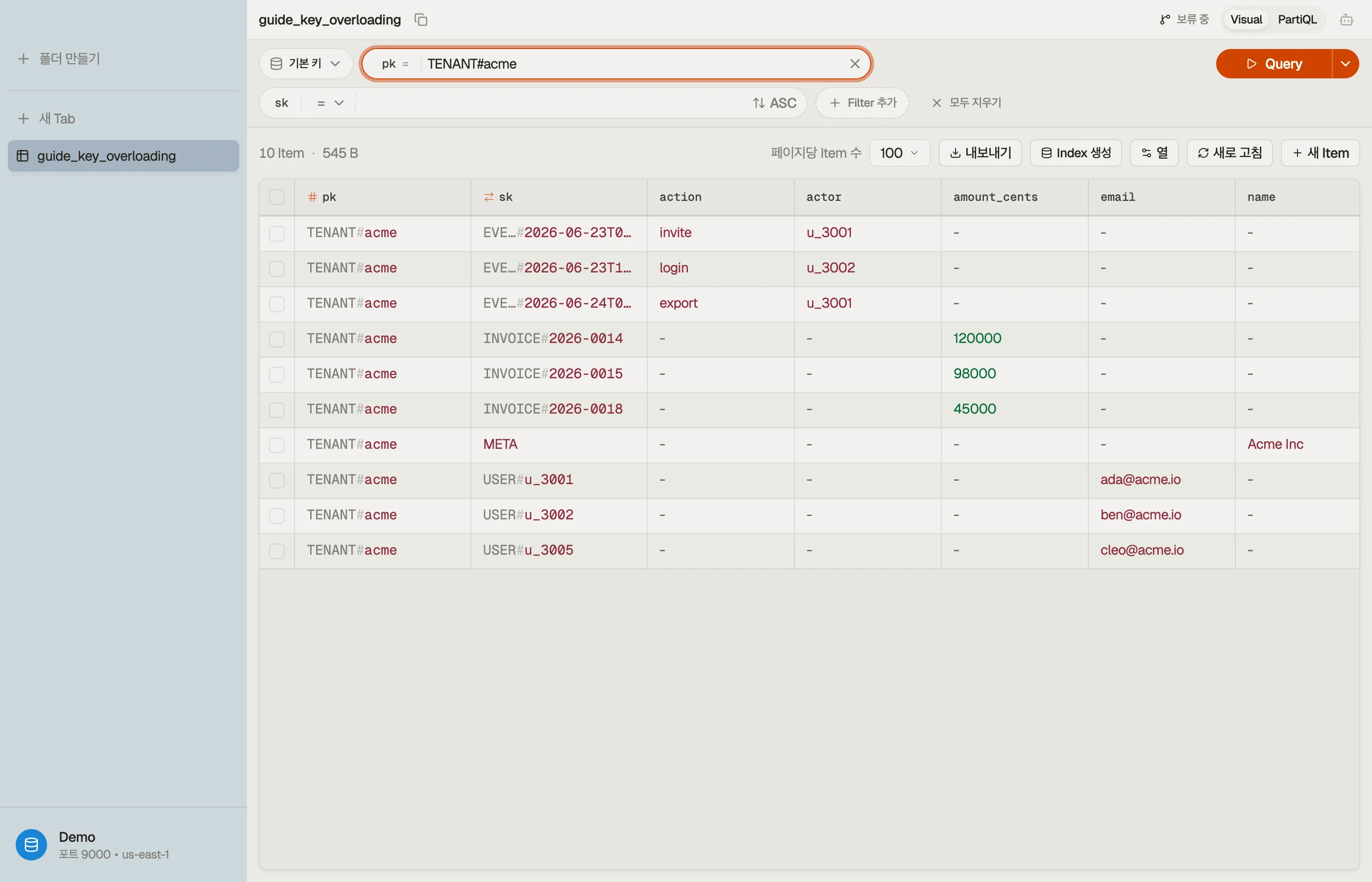
멀티테넌트 예제
SaaS 청구 제품을 운영한다고 합시다. 각 테넌트에는 멤버, 인보이스, 감사 추적이 있습니다. 세 개의 테이블 대신, 모든 것을 하나에 넣고 키를 오버로딩하세요:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
모든 행이 pk = "TENANT#acme"를 공유하므로 하나의 아이템 컬렉션을 형성합니다 — 모두
같은 위치에 있고, 모두 단일 파티션 읽기로 도달할 수 있습니다.
정렬 키 접두사가 진짜 일을 합니다. 엔티티를 그룹화하고 또한 정렬합니다.
오버로딩된 컬렉션 쿼리하기
유형이 정렬 키 접두사에 살기 때문에, begins_with는 아무것도 스캔하지 않고 파티션을
엔티티별로 잘라냅니다:
Query pk = "TENANT#acme" -- 테넌트 전체, 모든 유형
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- 멤버만
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- 인보이스만파티션 전체가 아니라 조건이 일치하는 아이템에 대해서만 비용을 냅니다 — 읽은 행을 그냥
버리면서도 비용을 내는 필터 걸린 Scan의 정반대입니다. AWS는
이를 키 조건이라 부릅니다. 어떤 데이터든 파티션을 떠나기 전에 키에서 실행됩니다.
그 begins_with 조건을 직접 손으로 만든다면 유형 태그를 정확히 맞추세요 — USER#
대신 USERS#를 잘못 쓰면 아무것도 반환하지 않습니다, 조용히.
expression builder는 접두사가 당신이 실제로 쓴
것과 일치하도록 KeyConditionExpression과 ExpressionAttributeValues 맵을
생성합니다.
인덱스도 오버로딩하기
같은 트릭이 GSI에도 적용됩니다. 일반적인 키 이름 — gsi1pk, gsi1sk — 을 주고, 각
엔티티가 필요한 것을 쓰게 하세요. 그러면 하나의 인덱스가 베이스 테이블이 할 수 없는
패턴에 답합니다.
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
이제 Query gsi1 WHERE gsi1pk = "STATUS#open"은 모든 테넌트에 걸쳐 열린 모든
인보이스를 마감일 순서로 나열합니다 — 베이스 테이블의 테넌트 범위 키로는 절대 처리할 수
없는 파티션 간 뷰입니다. 다른 엔티티가 자기 의미로 gsi1을 재사용할 수 있으므로
(예: gsi1pk = "ROLE#admin"), 하나의 인덱스가 여러 읽기를 커버합니다. 다만 GSI는
최종적 일관성을 가진다는 점을 기억하세요 — 그 쓰기는 베이스
테이블보다 뒤처집니다.
DynoTable에서 해보기
가공되지 않은 오버로딩된 키는 읽기에 적대적입니다: INVOICE#2026-0015와
EVENT#2026-06-23T09:12Z는 평평한 목록에서 뒤섞입니다. 파티션별로 그룹화하고 접두사를
드러내는 뷰어는 잡동사니 서랍을 다시 엔티티로 되돌립니다.


함정
- 구분자는 한 번 고르고 절대 바꾸지 마세요.
#이 관례입니다. 엔티티 전반에#과:을 섞으면 아무것도 경고하지 않는 방식으로begins_with가 깨집니다. - 범위 연산이 필요한 값을 오버로딩하지 마세요.
INVOICE#2026-0015라는 정렬 키는 숫자가 아니라 사전식으로 정렬됩니다 — ID는 0으로 채우고 날짜는 ISO-8601을 써서 문자열 순서가 의도한 순서와 일치하게 하세요. - 접두사 네임스페이스를 예약하세요. 둘 다
USER로 시작하는 두 엔티티 유형(예:USER#과USERGROUP#)은begins_with(sk, "USER")아래에서 충돌합니다. 접두사를 첫 글자부터 모호하지 않게 만드세요. - 키보다 읽기를 먼저 계획하세요. 오버로딩은 당신이 열거한 액세스 패턴을 처리합니다. 읽기를 아직 모른다면, 먼저 단일 테이블 설계를 참고하세요 — 키는 쿼리의 하류에 있습니다.
파티션을 그려본 다음, DynoTable을 다운로드하여 자신의 오버로딩된 키를
둘러보고 하나의 Query가 테넌트 전체를 한 번에 끌어오는 모습을 지켜보세요.