DynamoDB 정렬 키 전략
DynamoDB 기본 키는 하나 또는 두 개의 속성입니다. 파티션 키 단독, 또는 파티션 키 더하기 정렬 키. 파티션 키는 어느 물리 파티션이 아이템을 담을지 결정합니다.
정렬 키는 그 파티션 안에서 아이템의 순서를 결정하고 — 그 순서가 Query를
강력하게 만드는 것입니다.
정렬 키를 잘못 고르면 데이터를 쓸 수는 있어도, 범위 읽기와 정렬, 그리고 한 컬렉션의 여러 액세스 패턴을 잃습니다.
SQL에서 왔다면 사후에 ORDER BY나 보조 인덱스에 손을 뻗었을 겁니다. DynamoDB에서는
순서를 미리 키에 구워 넣거나, 아니면 얻지 못합니다.
DynamoDB 정렬 키는 어떻게 작동하나요?
DynamoDB 정렬 키는 파티션 안에서 아이템을 정렬하므로, Query가 한 번에 하나씩 가져오는 대신 범위 읽기(>=, between, begins_with)를 할 수 있습니다. 정렬은 인코딩된 키의 바이트 순서이므로, 바이트 순서가 읽고 싶은 순서와 같도록 키를 설계하세요 — ISO-8601 타임스탬프, 0으로 패딩된 숫자 형태로.
- 정렬 키는 파티션 내 인덱스입니다. 디스크에서 아이템 컬렉션을 정렬하므로,
Query가 단일GetItem이 아니라 범위 읽기(>=,between,begins_with)를 할 수 있습니다. - 정렬은 인코딩된 키의 바이트 순서입니다. 바이트 순서가 읽고 싶은 순서와 같도록
키를 설계하세요 — ISO-8601 타임스탬프, 0으로 패딩된 숫자, 결코 날것의 UUID나
6/23/2026이 아니라. - 잘 빚어진 정렬 키 하나가 많은 액세스 패턴을 충족합니다. 복합
키(
EVT#<timestamp>)는 접두사이자 범위입니다 — GSI가 필요 없습니다. - 방향은 공짜입니다.
ScanIndexForward = false는 같은 비용으로 최신순으로 읽습니다. 그걸 흉내 내려고 역순 타임스탬프를 저장하지 마세요.
정렬 키가 지렛대인 이유
정렬 키가 없으면, 파티션의 모든 아이템은 전체 기본 키로만 주소 지정됩니다 — 잘해야
GetItem이죠. 정렬 키를 추가하면 DynamoDB는 아이템을 파티션 안에서 그것으로
정렬해 저장하고, 그것이 Query를 풉니다.
그건 범위 조건(>=, between), 접두사 매칭(begins_with), 그리고 오름차순/내림차순으로
읽는 ScanIndexForward 플래그를 뜻합니다.
AWS DynamoDB 개발자 안내서에 따르면, 파티션 키를 공유하는 모든 아이템은 디스크에서 정렬 키로 정렬된 아이템 컬렉션을 이룹니다.
그러니 정렬 키는 단지 두 번째 식별자가 아닙니다. 파티션 안에서 쿼리하는 대상인 인덱스입니다.
그 정렬은 인코딩된 정렬 키의 바이트 순서입니다. 문자열은 UTF-8 바이트로, 숫자는 숫자로 비교됩니다. 이 한 가지 사실이 아래 거의 모든 전략을 이끕니다.
범위 쿼리가 의미를 가지길 원한다면, 바이트 순서가 읽고 싶은 순서와 맞아야 합니다.
전략 1: 정렬 키를 정렬 가능하게 만들기
가장 흔한 실수는 의미 있게 정렬되지 않는 정렬 키입니다. 무작위 UUID는 고유성을 주지만 쓸모 있는 범위 쿼리는 주지 않습니다 — 바이트 순서가 임의이므로 "마지막 20개 주세요"가 불가능해집니다.
대신, 정렬하고 필터링하는 값을, 바이트 순서가 논리적 순서와 같은 표현으로 정렬 키 안에 인코딩하세요. 타임스탬프라면 사전식으로 정렬 가능한 형식을 뜻합니다. ISO-8601 문자열이나 0으로 패딩된 epoch죠.
ISO-8601은 문자열 비교가 연대 비교와 같도록 설계되었습니다 — 정확히 범위 쿼리가
필요로 하는 것이죠. 6/23/2026 같은 형식은 피하세요. 달이 넘어가는 순간 잘못
정렬됩니다.
숫자(버전 카운터, 점수)로 정렬한다면, 42가 9 앞이 아니라 뒤로 정렬되도록 문자열
대신 DynamoDB의 네이티브 Number 타입을 쓰세요.
숫자가 복합 문자열 정렬 키 안에 살아야 한다면, 고정 폭으로 0 패딩하세요.
전략 2: 계층을 위한 복합 정렬 키
정렬 키는 구분자 — 가장 흔히 # — 로 세그먼트를 이어 붙여 계층을 인코딩할 수
있습니다. 그러면 하나의 begins_with 조건이 하위 트리 전체를 선택합니다:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#")는 6월의 이벤트만 돌려주고, 더 넓은
begins_with(SK, "EVENT#")는 전부 돌려줍니다.
세그먼트 순서는 설계 결정입니다. 굵게-에서-가늘게(연 → 월 → 일)는 관련 아이템을 연속되게 유지하므로, 범위 읽기가 파티션 곳곳으로 흩어지는 대신 하나의 저렴한 쿼리로 남습니다.
전략 3: ScanIndexForward로 방향 제어
DynamoDB는 아이템을 오름차순 정렬 키 순으로 저장하고 기본적으로 그렇게 읽습니다.
최신순으로 — 활동 피드의 자연스러운 순서로 — 읽으려면 Query에
ScanIndexForward = false를 설정하세요.
이것은 스키마 결정이 아니라 읽기 시점 플래그입니다. 같은 컬렉션이 양방향을 같은 비용으로 제공합니다. 내림차순 읽기를 얻으려고 타임스탬프를 뒤집지("역 epoch" 저장) 마세요.
한 아이템 컬렉션, 오름차순으로 한 번 저장, 양방향으로 읽기:
같은 아이템, 같은 파티션, 같은 비용 — 읽기 방향만 다릅니다.
한 가지 예외: 내림차순이 희소 인덱스나 페이지네이션 커서가 전진하는 순서이기도 해야
하는 경우. 그게 아니라면 ScanIndexForward가 더 단순한 지렛대입니다.
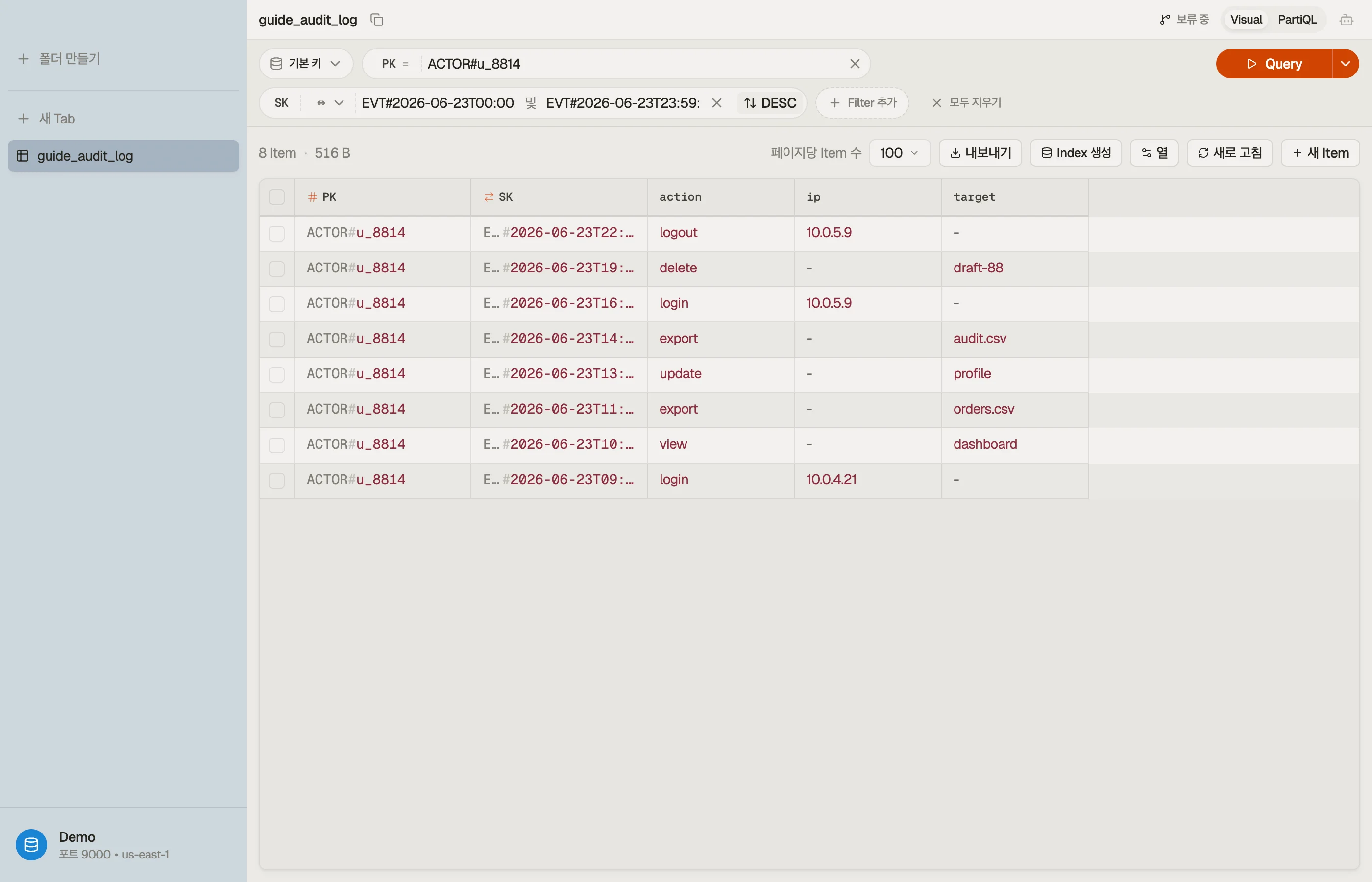
실전 예제: 행위자 범위 감사 로그
SaaS 제품에서 행위자 — 사용자, 서비스, API 키 — 가 생성한 타임스탬프 이벤트를 기록하고, 두 가지 읽기가 있다고 합시다:
- 한 행위자의 활동 스트림, 최신 이벤트 먼저.
- 시간 구간 안의 한 행위자 이벤트(예: "두 배포 사이의 모든 것"), 조사용.
두 읽기 모두 단일 행위자로 범위가 잡히므로, 행위자가 파티션 키이고 이벤트 시간이 정렬 키입니다. 같은 테이블이 나중에 다른 엔티티를 담을 수 있도록 범용 키 이름을 쓰세요:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
EVT# 접두사 더하기 ISO-8601 타임스탬프가 정렬 가능한 정렬 키를 줍니다. 읽기 1은
최신순을 위해 ScanIndexForward = false를 단 Query PK = "ACTOR#u_8814"입니다.
읽기 2는 정렬 키에 between 조건을 걸어 같은 파티션을 좁힙니다:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"한 컬렉션, 두 액세스 패턴, GSI 없음 — 정렬 키가 접두사(EVT#)이자
범위(타임스탬프)이기 때문입니다. 내림차순 읽기와 구간 읽기는 같은 순서의 같은
아이템입니다. 파라미터만 다릅니다.
그 키 조건을 손으로 짓다 보면 between 경계를 잘못 잡거나 속성 이름의 예약어
이스케이프를 헛디디기 쉽습니다.
DynamoDB 표현식 빌더는
begins_with나 between 정렬 키 조건의 KeyConditionExpression,
ExpressionAttributeNames, ExpressionAttributeValues를 생성합니다.
런타임에 이스케이프를 디버깅하는 대신 그것을 바로 SDK 호출에 복사하세요.
DynoTable에서 해보기
정렬 키 설계는 반복적입니다. 대표 아이템 몇 개를 쓰고, 범위 쿼리를 실행해, 행이 기대한 순서로 돌아오는지 확인하세요. GUI에서 라이브 테이블에 그렇게 하는 게 코드로 왕복하는 것보다 낫습니다.


정렬 방향을 뒤집고, between 경계를 좁히고, 코드 한 줄 안 쓰고 돌아오는 컬렉션이
바뀌는 걸 지켜보세요 — 정렬 키 설계를 확정하기 전에 확인하는 가장 빠른 방법입니다.
함정과 다음 단계
- 정렬 키는 파티션 안에서 고유해야 합니다. 두 이벤트가 타임스탬프를 공유할 수 있다면, 복합이 고유하게 유지되도록 정렬 키에 구분자(시퀀스 번호나 짧은 id)를 덧붙이세요.
- 핫 파티션은 정렬로 우회할 수 없습니다. 한 행위자가 나머지보다 훨씬 많은 이벤트를 만들면 정렬 키가 구해 주지 못합니다 — 부하를 퍼뜨리는 파티션 키 설계가 필요합니다. 싱글 테이블 디자인을 보세요.
- 두 번째 정렬 순서는 두 번째 인덱스가 필요합니다. 베이스 테이블의 정렬 키는 하나의 순서를 줍니다. 같은 아이템을 다르게(예: 이벤트 유형으로) 정렬하려면 다른 정렬 키로 GSI를 추가하세요 — 로컬 vs 글로벌 보조 인덱스 절충을 저울질하면서.
- "나중에 정렬"하려고
Scan에 손을 뻗지 마세요.Scan후 클라이언트 측 정렬은 테이블 전체를 읽고 순서를 버립니다 — 그게 Scan 함정입니다. 대신 순서를 정렬 키에 밀어 넣으세요.
키 조건이 맞으면, DynoTable을 써보세요. 컬렉션을 모델링하고, 오름차순과 내림차순 쿼리를 나란히 실행해, 출시 전에 실제 데이터로 정렬 키 전략을 검증하세요.