DynamoDB 아이템 컬렉션
아이템 컬렉션은 같은 파티션 키 값을 공유하는, 테이블(또는 인덱스) 안의 모든 아이템의 집합입니다. 켜는 기능이 아니라 — 여러분의 키 스키마에서 자연스럽게 드러나는 속성입니다.
두 아이템이 같은 파티션 키를 갖는 순간 그들은 컬렉션을 이루고, 그 컬렉션은
DynamoDB가 단일 Query로 함께 읽게 해 주는 단위가 됩니다.
이걸 제대로 하면 읽기가 한 번의 왕복으로 돌아옵니다. 틀리면 Scan에 발이 묶입니다.
DynamoDB 아이템 컬렉션이란 무엇인가요?
DynamoDB 아이템 컬렉션은 같은 파티션 키 값을 공유하는 모든 아이템의 집합으로, 함께 저장되고 정렬 키 순으로 정렬됩니다. 켜는 기능이 아니라 — 여러분의 키 스키마에서 자연스럽게 드러납니다. 컬렉션은 단일 Query가 효율적으로 읽는 단위이며, 반면 Scan은 모든 파티션을 훑습니다.
- 컬렉션은 그냥 "같은 파티션 키"입니다. 같은 파티션 키 값을 가진 둘 이상의 아이템이 함께, 정렬 키 순으로 저장됩니다.
- 효율적인
Query의 단위입니다.Query는 한 컬렉션을 읽고,Scan은 모든 파티션을 훑습니다. 그게 성능 이야기의 전부입니다. - 정렬 키가 없으면 컬렉션도 없습니다. 파티션 키만 있는 테이블은 키마다 아이템 하나뿐이라 — 모을 게 없습니다.
- 두 한계가 발목을 잡습니다: LSI가 있을 때의 컬렉션당 10GB 상한, 그리고 낮은 카디널리티 키로 인한 핫 파티션.
문제: 관련 아이템을 함께 읽기
차량 한 무리를 운영한다고 합시다. 각 차량이 몇 초마다 텔레메트리 — 속도, 냉각수
온도, 연료 수준 — 를 스트리밍합니다. 지배적인 읽기는 "차량 V-7741의 최근 측정값
주세요"입니다.
SQL에서 왔다면 vehicle_id 컬럼을 인덱싱하고 플래너가 일하게 두었을 겁니다. 평범한
키-값 저장소에는 그런 사치가 없습니다.
키-값 저장소는 모든 측정값을 고립된 레코드로 취급하므로, 그 질문은 테이블 전체를 스캔하고 필터링한다는 뜻이 됩니다. 느리고 비싸고, 무리가 커질수록 더 나빠집니다.
DynamoDB의 답은 "한 차량의 모든 측정값"을 물리적으로 묶이고 직접 주소 지정 가능한 것으로 만드는 것입니다. 그 묶음이 아이템 컬렉션입니다.
컬렉션이란 실제로 무엇인가
DynamoDB는 아이템을 파티션에 저장하고, 파티션 키를 해시해 각 아이템을 파티션에 배정합니다. 따라서 같은 파티션 키 값을 가진 모든 아이템은 같은 파티션에 떨어지고, 정렬 키로 정렬됩니다.
AWS 개발자 안내서가 정확히 이를 이름 붙입니다. 파티션 키 값을 공유하는 아이템들은 아이템 컬렉션 으로, 함께 저장되고 정렬 키로 순서가 매겨집니다.
이것은 2007년 Amazon Dynamo 논문이 도입한 바로 그 아이디어입니다 — 키를 노드에 배정하는 일관 해싱 — 에 정렬 차원을 더해 관련 아이템이 디스크에서 인접하도록 확장한 것이죠.
인접하고 정렬되어 있으므로, DynamoDB는 한 번의 탐색으로 그들의 연속 구간을
돌려줍니다. 그래서 Query는 저렴하고 Scan은 그렇지 않습니다. Query는 단일
컬렉션을 읽고, Scan은 모든 파티션을 훑습니다.
컬렉션을 이루려면 복합 기본 키 — 파티션 키 와 정렬 키 — 가 필요합니다. 파티션 키만으로 키잉된 테이블은 키 값마다 아이템이 정확히 하나뿐이라, 모을 게 없습니다.
실전 예제: 차량 → 텔레메트리 측정값
텔레메트리 스트림을 복합 키로 모델링하세요. 파티션 키는 차량을 식별하고, 정렬 키는 측정 타임스탬프로, 컬렉션 안에서 측정값을 최신순으로 유지합니다.
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPct여기엔 두 컬렉션이 있습니다 — 차량마다 하나씩. META 아이템(차량 메타데이터)과
V-7741의 모든 측정값이 한 컬렉션을 이루고, V-7742의 아이템들이 또 하나를
이룹니다.
비결에 주목하세요. 메타데이터에 어떤 TS#... 값보다도 앞서 정렬되는 정렬
키(META)를 주면, PK = "VEH#V-7741"에 대한 단일 Query가 차량의 프로필 과 그
측정값을 함께 돌려줍니다.
그게 싱글 테이블 디자인의 핵심인 부모-자식 패턴입니다.
각 점선 상자가 하나의 아이템 컬렉션입니다. 같은 파티션 키, 정렬 키로 정렬된
아이템들. Query는 정확히 한 상자를 읽습니다.
컬렉션 쿼리하기
컬렉션이 정렬 키로 정렬되어 있으므로 범위 읽기가 공짜로 따라옵니다. 한 차량의 10분 구간에 기록된 측정값을 뽑으려면 정렬 키를 한정하세요:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # 최신순키 조건이 여러분을 한 컬렉션(vehicleId = :v)으로, 그리고 그것의 연속 슬라이스
(recordedAt BETWEEN ...)로 제한합니다. DynamoDB는 그 아이템들만 읽고 그만큼만
과금합니다. 메타데이터만 원하나요? recordedAt = "META"가 단일 META 아이템을
가져옵니다.
이런 키 조건과 프로젝션 표현식을 손으로 짓는 건 까다롭습니다.
DynamoDB 표현식 빌더가
KeyConditionExpression, ExpressionAttributeNames,
ExpressionAttributeValues를 대신 생성해 주므로, 예약어와 플레이스홀더 세부가
발목을 잡지 않습니다.
인덱스 위의 컬렉션
보조 인덱스에는 자체 키 스키마가 있으므로, 자체 아이템 컬렉션을 이룹니다.
depotCode(파티션)와 recordedAt(정렬)으로 키잉된 글로벌 보조 인덱스를 추가하면,
"차고지 DEP-LON-3의 모든 측정값을 최신순으로"가 그 인덱스 컬렉션에 대한 단일
Query가 됩니다 — 베이스 테이블이 제공할 수 없는 읽기죠.
그래서 인덱스 유형이 중요합니다. 어떤 컬렉션을 이룰 수 있고 그것이 어떻게 동작할지를 좌우하니까요. 그 절충은 GSI vs LSI를 보세요.
날카로운 구분 하나: 로컬 보조 인덱스(LSI) 는 베이스 테이블의 파티션 키를 공유하므로, 그 컬렉션이 베이스 아이템 컬렉션과 물리적으로 묶입니다 — 그리고 그 결속이 아래의 강한 한계를 만듭니다.
발목을 잡는 한계들
아이템 컬렉션은 강력하지만, 두 제약이 키를 어떻게 빚을지를 결정합니다:
- 10GB LSI 한계. 테이블에 하나 이상의 로컬 보조 인덱스가 있으면, 단일 아이템
컬렉션 — 한 파티션 키에 대한 베이스 아이템과 그 LSI 프로젝션 — 은 10GB를 넘을
수 없습니다. 넘으면 컬렉션을 키우는 쓰기가
ItemCollectionSizeLimitExceeded로 실패하기 시작합니다. LSI가 없는 테이블에는 그런 컬렉션당 상한이 없습니다. 이것이 바로 끝없이 자라는 무한 스트림(멈추지 않는 텔레메트리)이 LSI에 안 맞는 이유입니다. 컬렉션이 자라기만 하니까요. GSI는 자체 파티션을 얻으므로 그 한계를 비껴갑니다. - 핫 파티션. 컬렉션은 한 파티션 안에 살고, 단일 파티션의 처리량은 유한합니다.
한 차량(또는 한
depotCode)이 트래픽의 터무니없이 큰 몫을 끌어모으면, 테이블 전체가 프로비저닝 미달인 와중에도 그 파티션을 핫스팟으로 만들 수 있습니다. 적응형 용량 — AWS의 "Advanced Design Patterns for DynamoDB" re:Invent 심층 강연에서 다루는 — 은 핫 키를 자동으로 격리하고 부스트하지만, 분산이 전혀 없는 키를 구해 주지는 못합니다. 트래픽이 여러 컬렉션으로 퍼지도록 카디널리티가 높은 파티션 키를 고르세요.
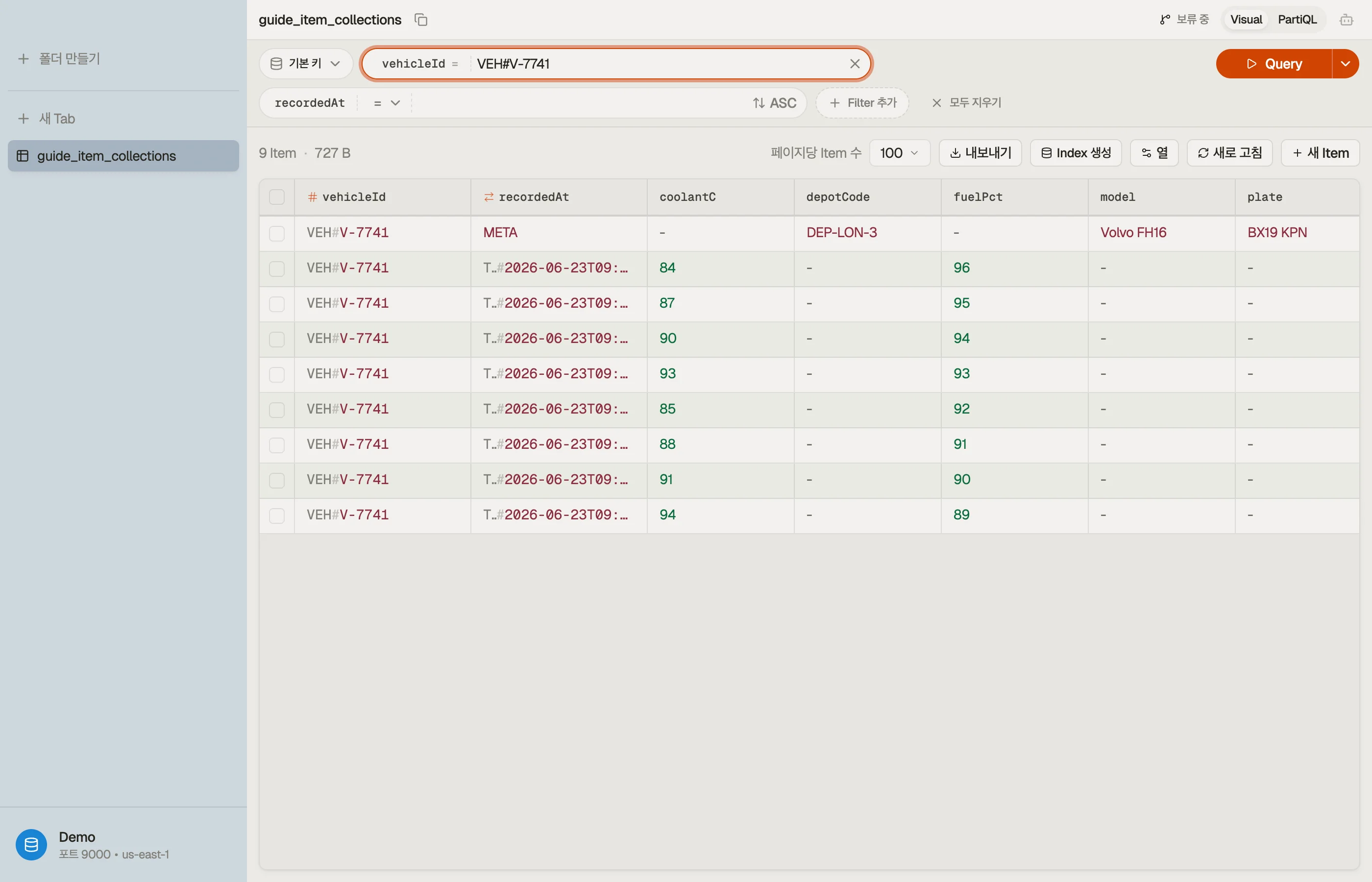
DynoTable에서 직접 보기
컬렉션에 대한 직관을 쌓는 가장 빠른 길은 하나를 직접 보는 것입니다. DynoTable에서
파티션 키를 쿼리하면 컬렉션 전체가 연속된, 정렬 키 순서의 목록으로 렌더링됩니다 —
META 아이템이 타임스탬프 측정값들 바로 앞에 화면에 놓이며, 머릿속 재구성은 필요
없습니다.


함정과 다음 단계
- 정렬 키가 없으면 컬렉션도 없습니다. 파티션 키만 있는 테이블은 관련 아이템을 묶을 수 없습니다. 아이템을 함께 읽어야 한다면 복합 키가 필요합니다.
- LSI 컬렉션이 무한정 자라게 두지 마세요. 추가 전용 스트림은 10GB 상한 때문에 LSI가 아니라 GSI(또는 시간 버킷 파티션 키)에 속합니다.
- 파티션 키를 퍼뜨리세요. 컬렉션은 그것이 사는 파티션만큼만 확장 가능합니다. 낮은 카디널리티 파티션 키는 핫스팟을 만듭니다.
Scan이 아니라Query를 쓰세요. 컬렉션은 관련 아이템을 하나의 겨냥된Query로 읽기 위해 존재합니다.Scan으로 물러나면 그 이점을 내버립니다 — Query vs Scan을 보세요.
여러분만의 키 스키마를 스케치하고, 실제 파티션 키에 Query를 실행해, 컬렉션이
정렬되어 돌아오는 걸 지켜보세요. DynoTable을 다운로드해 여러분 테이블의
컬렉션을 직접 탐색하세요.