DynamoDB의 복합 정렬 키
복합 기본 키는 파티션 키에 정렬 키를 더한 것입니다. 이를 강력하게 만드는 비결은
정렬 키 안에 무엇을 넣느냐입니다. 계층 구조를 하나의 구분자가 들어간 문자열로
인코딩하면, 단일 Query가 서브트리 전체를 정렬 순서대로 읽습니다 — 조인도, 재귀도, 두
번째 왕복도 없이.
DynamoDB에서 복합 정렬 키는 어떻게 작동하나요?
복합 정렬 키는 계층 구조를 하나의 구분자가 들어간 문자열 — root/photos/2026/ — 에 담고, DynamoDB는 이를 UTF-8 바이트 순서로 저장합니다. 레이아웃이 이미 트리와 일치하므로, begins_with(SK, "root/photos/")를 쓰는 단일 Query가 서브트리 전체를 경로 순서로 읽습니다. 조인도, 재귀도, 두 번째 왕복도 없이 — 연속된 슬라이스에 대한 접두사 스캔일 뿐입니다.
- 정렬 키는 단순한 ID가 아니라 정렬 가능한 문자열입니다. 경로를 담으세요 —
root/photos/2026/— 그러면 DynamoDB가 파티션의 아이템을 자동으로 UTF-8 바이트 순서로 저장합니다. - 구분자는 접두사 일치를 서브트리 읽기로 바꿉니다.
begins_with(SK, "root/photos/")는 그 폴더의 모든 자손을 단일 쿼리로 반환합니다. - 정렬 키는 임의 필터가 아니라 범위 조건을 지원합니다.
begins_with,between,>,<를 쓸 수 있습니다 — 필요한 읽기가Scan이 아니라 접두사나 범위가 되도록 키를 설계하세요. - 구분자가 핵심을 짊어집니다. 경로 세그먼트에 등장할 수 없는 구분자를 고르세요. 그러지 않으면 무관한 두 가지가 충돌합니다.
정렬 키가 게임의 전부인 이유
SQL에서 넘어왔다면 폴더 트리를 parent_id 셀프 조인으로 모델링하고 재귀적으로
순회할 것입니다 — 레벨마다 쿼리 하나씩. DynamoDB에서 그것은 조인이 없는 키-값 저장소를
상대로 한 N+1 지뢰입니다.
DynamoDB는 모든 아이템을 파티션 키 아래에 정렬 키로 정렬하여, 문자열의 경우 UTF-8 바이트 순서로 저장합니다 (AWS: Query 키 조건). 그래서 정렬 키가 경로 그 자체라면, 물리적 레이아웃이 이미 트리와 일치합니다. 읽기는 그래프 순회가 아니라 연속된 슬라이스에 대한 접두사 스캔이 됩니다.
그것이 핵심의 전환입니다. 정렬 키는 정확히 일치시켜야 하는 식별자가 아닙니다. 정렬 가능한 주소입니다. 잘 설계하면 쿼리가 거저 따라 나옵니다.
파일 시스템 트리 모델링
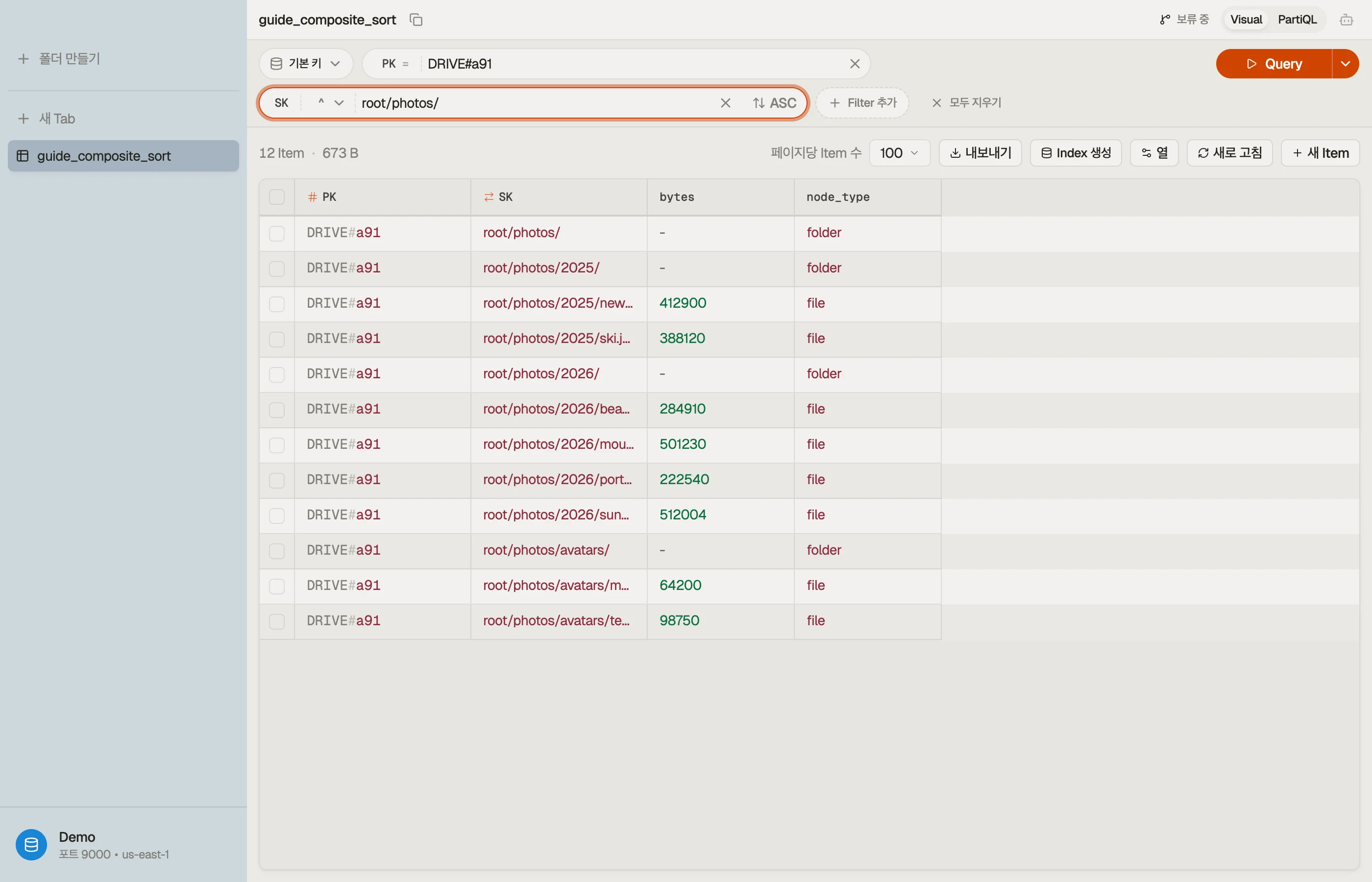
계정별 파일 트리를 저장한다고 합시다. 계정당 하나의 드라이브가 자연스러운 파티션이고, 그 안의 경로가 정렬 키입니다.
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
여기서 일하는 두 가지 본래의 관례:
PK = DRIVE#<account>는 한 계정의 트리 전체를 하나의 아이템 컬렉션에 담아, 어떤 서브트리 읽기든 단일 파티션Query가 되게 합니다.SK는 폴더에 끝의/가 붙은 전체 경로입니다. 끝의 슬래시는 의도적입니다 — 폴더가 자기 자식들보다 먼저 정렬되게 하고,root/photos/를root/photos라는 이름의 형제 파일과 구별되게 합니다.
서브트리를 한 번의 쿼리로 읽기
root/photos/ 아래의 모든 것을 — 폴더, 하위 폴더, 파일을 재귀적으로 — 나열합니다:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"이는 root/photos/, root/photos/2026/, beach.jpg, sunset.jpg를 — 경로 순서로,
하나의 과금되는 읽기로 반환합니다. 드라이브 전체가 아니라 그 슬라이스의 아이템에 대해서만
비용을 냅니다.
DynoTable에서는 경로 정렬 키에 이 begins_with 쿼리를 그대로 실행하면 폴더와 그
자손이 경로 순서로 돌아옵니다 — 자리표시자 구문을 직접 손으로 쓸 필요가 없습니다.
자신의 코드에 쓸 원시 KeyConditionExpression(이름, 값, begins_with)이 필요하신가요?
DynamoDB Expression Builder에서 만들고 복사하세요.


서브트리 전체가 아니라 한 레벨만 나열하기
begins_with는 재귀적 읽기를 줍니다. 비재귀적 디렉터리 나열 — root/photos/의
직속 자식만 가져오고 그 아래로는 들어가지 않는 것 — 을 위해서는 depth 속성을
저장하고 정렬 키 범위와 필터를 더하거나, 경로를 parent GSI로 분리하세요. 가장 단순한
방법은 parent 속성(root/photos/)을 유지하고 그것을 키로 하는 GSI를 두는 것입니다.
요점: 정렬 키는 접두사와 범위 질문에 저렴하게 답합니다. "직속 자식만"은 다른
질문입니다 — FilterExpression이 효율적이기를 바라기보다 명시적으로 모델링하세요. 필터는
읽기가 끝난 후 실행되며, 버리는 아이템에 대해서도 비용을 냅니다.
구분자를 신중히 고르기
구분자는 데이터 계약의 일부입니다. 두 가지 규칙:
- 경로 세그먼트 안에 절대 등장하면 안 됩니다. 파일 이름에
/가 들어갈 수 있다면,/는 잘못된 구분자입니다 —a/b라는 이름의 파일이b를 담은 폴더a와 구별되지 않습니다. 예약된 바이트(어떤 팀은#이나 제어 문자를 씁니다)를 고르고 세그먼트에서 금지하세요. - 경계에서의 정렬 순서에 유의하세요.
/(0x2F)는 숫자와 글자보다 먼저 정렬되는데, 이는 보통 트리 순서로 원하는 바입니다. 구분자를 바꾸면 순서가 바뀝니다 — 실제 데이터로 검증하세요.
복합 정렬 키 vs. 별도의 정렬 속성
복합 정렬 키 (root/photos/2026/x) | 단순 ID 정렬 키 + parent 속성 | |
|---|---|---|
| 서브트리 읽기 | begins_with 쿼리 하나 | 재귀 쿼리(N+1) 또는 GSI 순회 |
| 정렬 | 경로 순서, 거저 | 명시적 정렬 속성을 추가해야 함 |
| 이동 / 이름 변경 | 모든 자손을 다시 씀 | parent 포인터 하나를 업데이트 |
| 직속 자식 나열 | depth 속성이나 GSI 필요 | 자연스러움 (parent = x) |
복합 키는 읽기가 서브트리 형태이고 순서가 중요할 때 이깁니다. 트리가 끊임없이 변할 때는 평평한 ID 모델이 이깁니다. 대부분의 읽기 중심 계층 구조 — 파일 트리, 카테고리 트리, 조직도 — 는 복합 쪽으로 기웁니다.
함정과 다음 단계
- 키를 과하게 채우지 마세요. 인코딩하는 모든 것은 불변이며 접두사로만 인덱싱됩니다. 동등성으로 조회하는 속성은 정렬 키에 욱여넣지 말고 별도 필드나 GSI에 두세요.
- 정렬 키는 임의의
WHERE를 할 수 없습니다.begins_with,between, 비교만 가능합니다.FilterExpression에 손을 뻗고 있다면, 키를 잘못 모델링했을 가능성이 큽니다 — Query vs. Scan을 참고하세요. - 키 설계를 더 깊이 파고드는 내용은 단일 테이블 설계에 있습니다. 서브트리 읽기가 베이스 테이블 대신 인덱스를 필요로 할 때는 GSI vs. LSI를 참고하세요.
Expression Builder로 begins_with 키 조건을
만든 다음, DynoTable을 다운로드하여 이런 접두사 쿼리를 자신의 테이블에서
실행하고 서브트리가 경로 순서로 돌아오는 모습을 지켜보세요.