DynamoDB 인덱스 프로젝션: KEYS_ONLY, INCLUDE, ALL
보조 인덱스를 만들 때 DynamoDB가 아이템 전체를 자동으로 거기 복사하지는 않습니다. 무엇이 복사될지 — 인덱스의 프로젝션 — 을 여러분이 고릅니다. 너무 적게 고르면 쿼리가 나머지를 가져오느라 두 번째 읽기를 무릅니다. 전부 고르면 갱신마다 추가 스토리지와 쓰기 비용을 무릅니다. 인덱스 생성 때 한 번 정하고 함께 살아가는 절충입니다.
(이것을 프로젝션 표현식과 혼동하지 마세요. 그건 단일 읽기가 돌려주는 속성을 다듬는 것입니다. 이 페이지는 인덱스가 물리적으로 저장하는 것에 관한 것입니다 — 다른 쪽은 프로젝션 표현식을 보세요.)
DynamoDB 인덱스 프로젝션이란?
프로젝션은 DynamoDB가 베이스 테이블에서 보조 인덱스로 복사하는 속성의 집합입니다. 세 가지 유형 중 하나를 고릅니다. KEYS_ONLY(키만), INCLUDE(키에 더해 명명된 속성 목록), ALL(아이템 전체). 프로젝션이 많을수록 베이스 테이블 조회는 줄지만 스토리지와 쓰기 비용은 늘어납니다.
- 프로젝션은 보조 인덱스에 복사되는 속성의 집합입니다.
KEYS_ONLY— 테이블 키와 인덱스 키만. 가장 작고 가장 저렴합니다.INCLUDE— 키에 더해 여러분이 고른 명명된 추가 속성 목록.ALL— 아이템의 모든 속성. 가장 큽니다. 쿼리는 베이스 테이블이 결코 필요 없습니다.- 프로젝션되지 않은 속성을 읽으면 GSI의 경우 베이스 테이블에서 조회를 강제합니다 — 조용한 추가 비용입니다. (LSI는 추가 읽기 비용으로 프로젝션되지 않은 속성을 가져와 줄 수 있습니다.)
- 프로젝션이 많을수록 = 스토리지와 쓰기 비용이 늘어납니다. 모든 베이스 테이블 쓰기가 인덱스로 전파되기 때문입니다.
문제: 두 번 읽게 만드는 인덱스
열린 티켓을 우선순위로 나열하게 해 주는 GSI가 있는 지원 데스크를 운영한다고
합시다. 가볍게 유지하려고 KEYS_ONLY를 프로젝션합니다. 쿼리는 빠르게
돌아옵니다 — 하지만 티켓 id만 주는데, 큐 화면은 각 티켓의 제목, 담당자, 경과
시간이 필요합니다.
그래서 이제 코드는 베이스 테이블에 두 번째 읽기 라운드를 돌려 모든 결과를 채웁니다. 여러분이 설계한 "하나의 쿼리"는 실은 쿼리 더하기 N개의 get이고, 아끼려던 지연과 비용이 고스란히 돌아옵니다. 프로젝션이 액세스 패턴에 비해 너무 얄팍했던 겁니다.
각 프로젝션 유형이 복사하는 것
KEYS_ONLY는 베이스 테이블 키 와 인덱스 키만 저장합니다. 쿼리가 어떤 아이템이 일치하는지만 알면 되고 세부 정보는 다른 데서 가져오거나 — 아예 안 가져올 때 쓰세요.- **
INCLUDE**는 키에 더해 여러분이 명명한 고정 속성 목록을 저장합니다. 최적점: 쿼리가 렌더링에 필요한 필드만 정확히 프로젝션하고 그 이상은 안 하기. - **
ALL**은 아이템 전체를 복사합니다. 쿼리는 인덱스만으로 온전히 자급되지만, 아이템 전체의 스토리지와 쓰기 처리량을 거기 중복하는 대가가 따릅니다.
지원 데스크 큐라면 subject, assignee, age를 담은 INCLUDE가 옳은
선택입니다 — 큐는 두 번째 조회 없이 인덱스만으로 렌더링되고, 티켓의 커다란
body를 인덱스에 중복하지 않습니다.
맞바꾸는 비용
프로젝션하는 모든 속성은
두 번째로 저장되고
베이스 아이템이 바뀔 때마다 인덱스에서 다시 쓰입니다. 그래서 자주 갱신되는
테이블에 넉넉한 ALL 프로젝션은 스토리지와 쓰기 용량을 둘 다 배가합니다. 규율은
이렇습니다. "혹시 몰라서 전부"가 아니라 쿼리가 읽는 것을 프로젝션하기.
알아둘 만한 미묘함: 희소 인덱스에서는 프로젝션이 여전히 인덱스 키를 가진
아이템만 담으므로 — 희소 인덱스의 INCLUDE/ALL은
인덱스 자체가 작기 때문에 작게 유지됩니다. 여러분 프로젝션의 스토리지와 쓰기 승수를
DynamoDB 요금 계산기로 가늠하고, 인덱스 쿼리
자체는 DynamoDB 표현식 빌더로 짜세요.
DynoTable에서 프로젝션 보기
DynoTable은 테이블의 각 보조 인덱스를 나열하고 그중 하나를 통해 곧장 쿼리하게 해 줍니다. 같은 액세스 패턴을 베이스 테이블과 GSI에 각각 돌려 결과를 비교하세요 — 인덱스 결과에서 빠진 속성이 바로 그 인덱스가 프로젝션하지 않는 것들이므로, 테이블 정의를 다시 읽지 않고도 프로젝션의 효과가 눈에 보입니다.

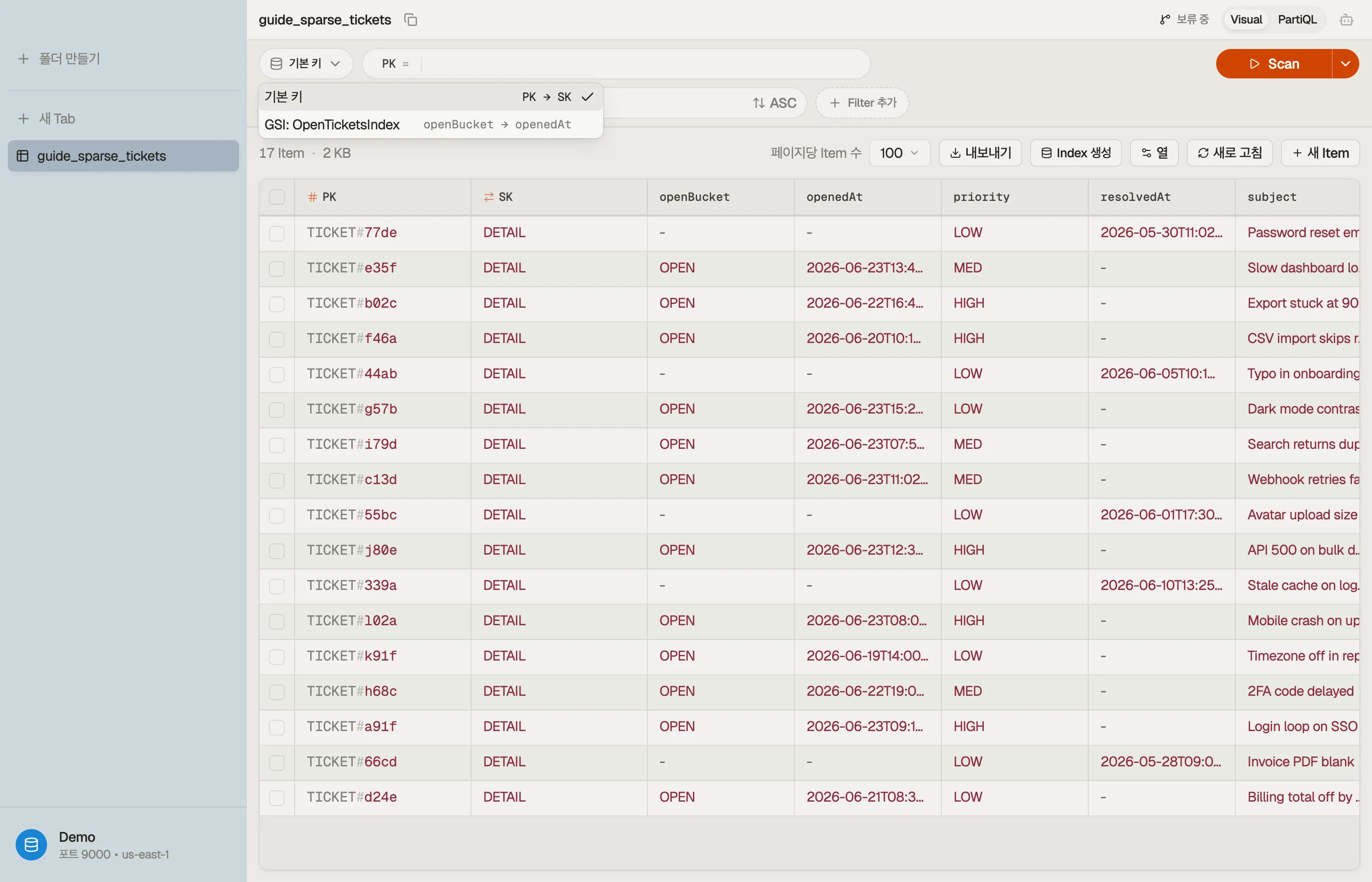

함정과 다음 단계
- GSI에서 프로젝션되지 않은 속성은 베이스 테이블 조회를 뜻합니다 — 쿼리가 렌더링하는 것을 중심으로 프로젝션을 설계하세요.
ALL이 공짜인 경우는 드뭅니다 — 스토리지와 쓰기 비용을 중복합니다. 인덱스가 진정으로 모든 필드를 필요로 하지 않는 한INCLUDE를 기본으로 삼으세요.- 프로젝션은 대체로 고정입니다. 인덱스를 다시 만들지 않고는 GSI의 프로젝션을 나중에 자유로이 편집할 수 없습니다 — 처음부터 신중히 고르세요.
- 관련: GSI 대 LSI와 희소 인덱스가 프로젝션이 실제로 얼마나 많이 저장하는지를 좌우합니다.
인덱스를 재설계하기 전에 각 인덱스가 실제로 무엇을 돌려주는지 보고 싶으신가요? DynoTable을 받아서 테이블을 직접 쿼리하세요.