Relasi One-to-Many di DynamoDB
Sebuah control plane SaaS hampir selalu punya hierarki containment: satu
workspace memiliki banyak project. Di SQL Anda akan memasang foreign key
workspace_id pada tabel project dan melakukan JOIN.
DynamoDB tidak punya join dan tidak punya foreign key, jadi relasinya harus hidup
di dalam key schema itu sendiri. Dikerjakan dengan benar, "muat sebuah
workspace beserta setiap project di dalamnya" menjadi satu Query alih-alih satu
pembacaan ditambah scan susulan.
Bagaimana cara memodelkan relasi one-to-many di DynamoDB?
Berikan induk dan semua anaknya yang sama agar mereka berbagi satu , lalu bedakan mereka dengan sort key. DynamoDB tidak punya join atau foreign key, sehingga relasinya hidup di dalam key schema itu sendiri. Memuat sebuah induk beserta setiap anaknya kemudian menjadi satu Query alih-alih sebuah join.
- Modelkan pembacaannya, bukan entitasnya. Relasi one-to-many hanya ada untuk melayani "daftar project sebuah workspace" — bentuk key di sekitar query itu.
- Kodekan induk ke dalam partition key anak. Beri workspace dan semua projectnya nilai partition-key yang sama agar mereka mendarat di satu item collection.
- Lalu pembacaan daftar menjadi satu
Query. Induk plus sejumlah anak sembarang kembali dalam satu panggilan yang ditagih — tanpa join, tanpa round trip kedua. - Waspadai hot partition. Satu tenant raksasa memusatkan semua trafiknya pada satu partition; workspace berukuran besar mungkin butuh key yang di-shard dan pembacaan fan-out.
Pola akses, lebih dulu
Pemodelan DynamoDB mengutamakan pola akses, bukan mengutamakan entitas — disiplin yang sama di balik single-table design. Sebelum memilih key apa pun, tuliskan pembacaan yang benar-benar dikeluarkan aplikasi:
- Ambil setelan satu workspace.
- Daftar setiap project dalam sebuah workspace, terbaru lebih dulu.
- Ambil satu project tertentu berdasarkan id.
Relasi "satu workspace, banyak project" hanya penting karena pembacaan #2. Jika Anda tidak pernah perlu mendaftar project sebuah workspace bersama-sama, Anda tak akan memodelkan relasinya sama sekali — Anda akan menyimpan project secara independen.
Jadi pertanyaannya tidak pernah "bagaimana saya merepresentasikan one-to-many?" secara abstrak. Pertanyaannya adalah "query mana yang harus dilayani relasi ini?" Jawab itu, lalu bentuk key di sekitarnya.
Mengapa foreign key tidak menolong di sini
Di DynamoDB setiap GetItem dan Query menargetkan sebuah partition key, dan
layanan ini melakukan hash terhadap key itu untuk menemukan partition yang menampung
Item tersebut.
AWS menyatakannya langsung dalam dokumen Core Components: nilai partition-key adalah input bagi fungsi hash internal yang memutuskan di mana data berada.
Penempatan berbasis hash itu adalah warisan dari makalah Dynamo: Amazon's Highly Available Key-value Store asli tahun 2007, di mana consistent hashing menyebarkan key ke seluruh node.
Sebuah atribut workspace_id polos pada sebuah Item project tak terlihat oleh
mesin itu — DynamoDB tak bisa "mengikutinya".
Untuk mengambil Item terkait dalam satu request, identitas induk harus dikodekan ke
dalam partition key project, agar semua Item sebuah workspace di-hash ke
partition yang sama dan satu Query bisa menyapunya.
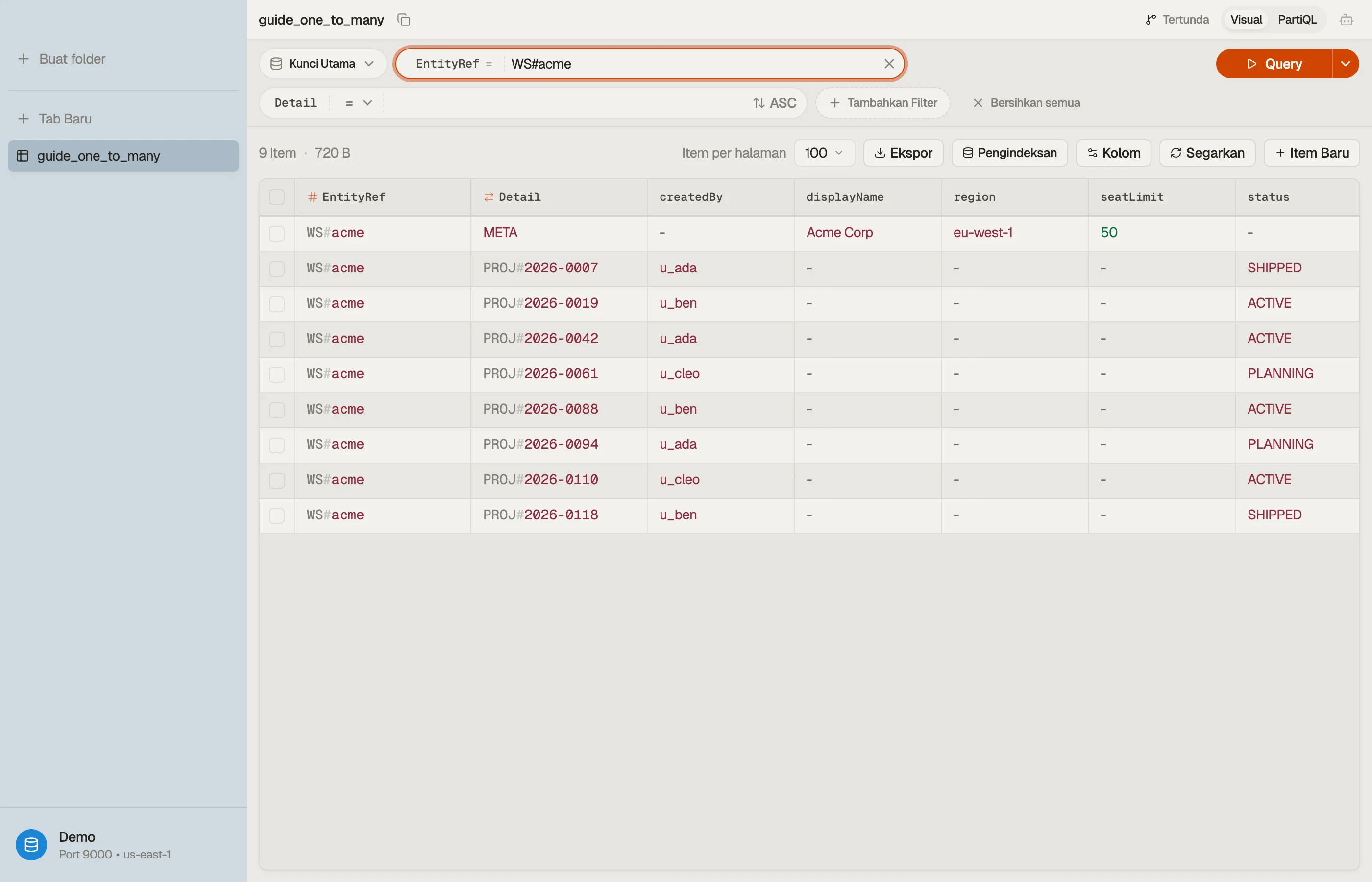
Contoh nyata: workspace dan project
Gunakan key schema generik yang ditumpangi. Beri nama partition key EntityRef dan
sort key Detail. Identitas workspace masuk ke EntityRef untuk baik Item
workspace maupun setiap project di bawahnya:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
Workspace dan semua projectnya berbagi EntityRef = "WS#acme", sehingga mereka
membentuk satu item collection yang hidup bersama pada satu partition.
Sort key Detail memisahkan mereka: META adalah catatan workspace, dan setiap
project membawa prefiks PROJ# dengan id terurut-waktu yang di-zero-pad sehingga
project terurut secara alami.
Secara visual, induk dan anak-anaknya menumpuk di dalam satu partition, terurut berdasarkan sort key:
Satu Query pada EntityRef = "WS#acme" menyapu seluruh tumpukan — induk plus
setiap anak — dalam satu pembacaan.
Kini ketiga pola akses masing-masing menyusut menjadi satu panggilan:
- Setelan workspace —
GetItem(EntityRef="WS#acme", Detail="META"). - Daftar project terbaru lebih dulu —
Query(EntityRef="WS#acme")denganDetail begins_with "PROJ#", dijalankan dalam urutan menurun (ScanIndexForward = false). - Satu project —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
Yang kedua adalah inti seluruhnya: induk dan sejumlah anak sembarang kembali dalam
satu Query yang ditagih, tanpa join dan tanpa round trip kedua. Itulah
langkah yang tak bisa Anda lakukan dengan atribut foreign-key dan sebuah Scan.
Menulis kondisi begins_with itu dengan tangan memang merepotkan — sintaks
key-condition dan projection-expression menggigit.
DynamoDB Expression Builder menghasilkan
KeyConditionExpression, peta placeholder #name/:value, dan snippet SDK siap
jalan sehingga Anda tak perlu melawan tata bahasanya:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Inspeksi item collection di DynoTable
Hasil dari tata letak ini bersifat visual: setiap baris yang berbagi EntityRef
adalah workspace plus anak-anaknya, duduk berdampingan.
DynoTable mengelompokkannya agar Anda melihat relasi one-to-many sebagai satu blok yang menyatu alih-alih menebak-nebaknya di antara tabel terpisah.


Jebakan dan bentuk alternatif
Beberapa hal yang perlu diwaspadai:
- Hot partition. Setiap Item untuk satu workspace hidup pada satu partition,
jadi satu tenant yang sangat besar atau sangat sibuk memusatkan trafik. Perilaku
adaptive capacity
yang dijelaskan AWS menyerap skew moderat, tetapi workspace dengan jutaan project
mungkin butuh key yang di-shard (mis.
WS#acme#01 … #10) dan pembacaan fan-out. - Ukuran item collection. Dengan local secondary index, item collection satu partition dibatasi 10 GB; tanpa LSI tidak ada batas semacam itu. Jika Anda menimbang tipe index di sini, lihat GSI vs LSI.
- Raih
Query, jangan pernahScan. Seluruh desain ini ada agar Anda bisaQuerysatu partition. Kembali keScanberfilter untuk "menemukan project sebuah workspace" membuang model itu dan membaca seluruh tabel — jebakan yang dibahas dalam Query vs Scan.
Jika Anda benar-benar perlu mendaftar project lintas workspace (misalnya, semua
project status = ACTIVE secara global), tabel dasar tak bisa menjawabnya —
partition keynya tercakup-workspace.
Itu pekerjaan untuk secondary index yang mem-partition ulang project pada atribut berbeda, bukan untuk membentuk ulang relasi ini.
Langkah berikutnya
Modelkan pola akses, kodekan induk ke dalam partition key anak, dan pembacaan
one-to-many menjadi satu Query. Bangun dan validasi kondisi key dengan
DynamoDB Expression Builder.
Lalu unduh DynoTable untuk memuat schema ini, menelusuri item collection workspace→project secara langsung, dan memastikan setiap query melakukan tepat satu pembacaan.